![[MIT6.5940] Lect 18 Distributed Training (Ⅱ)](/upload/宏村.webp)
一、Hybrid parallelism and auto-parallelize
Ⅰ、Hybrid parallelism
- 混合并行是指数据并行、流水线并行和张量并行进行组合搭配使用,具体三种并行的讲解可以看Lect 17。
- 2D并行
- 数据并行+流水线并行
- 对于外部,使用数据并行,将四个GPU分为两组[GPU1 & GPU3, GPU0 & GPU2],分别处理数据的两个分片。
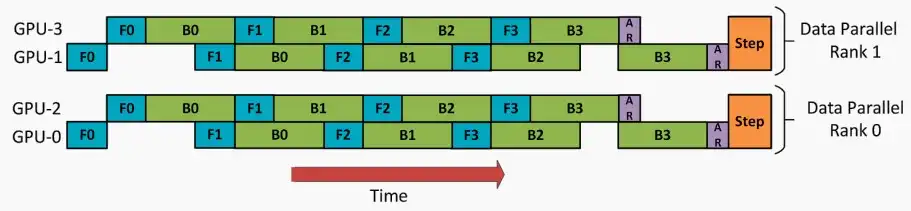
- 对于内部,使用流水线并行,组内两个GPU如下图分工,当后向传播B0进行时,另一个GPU可以进行前向传播F1。
- 数据并行+流水线并行
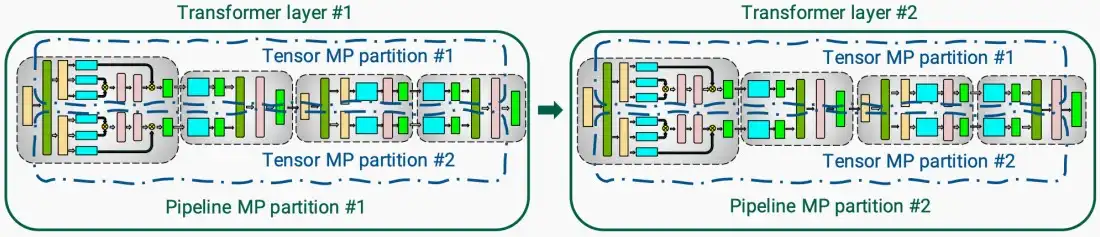
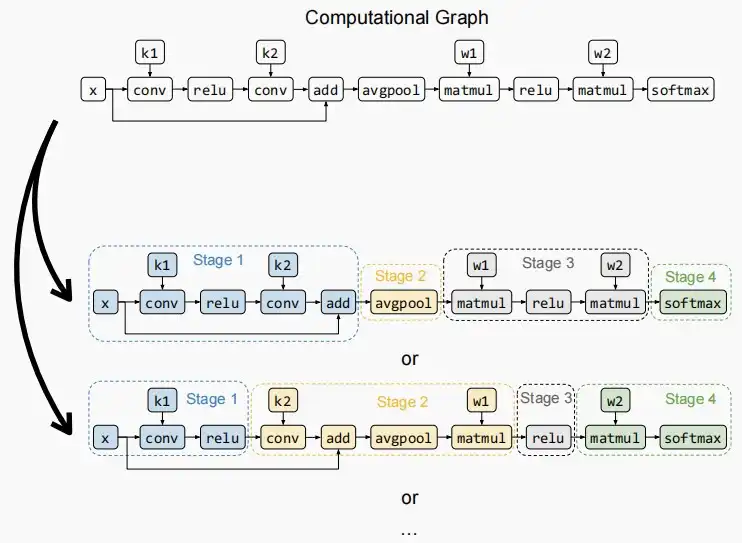
* 流水线并行+张量并行 * 对于外部,流水线并行,每一层由不同的GPU执行。 * 对于内部,张量并行,每一层内的计算分片,如下图中蓝色框,每个GPU负责一个蓝色框。
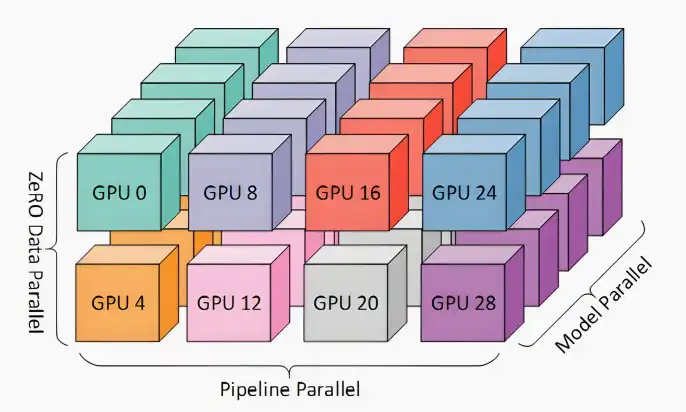
- 3D并行
- 流水线并行+张量并行+数据并行
- 相同的颜色表示在同一台服务器上的GPU,并对同一服务器上的GPU进行模型并行,因为模型并行对通信带宽的需求极高。
Ⅱ、Auto Parallelize
- 动机
- 当型号太大无法适合GPU时:使用流水线并行分割模型。
- 当一个层太大无法适应GPU时:使用张量并行分割图层。
- 但是,如何找到最好的并行策略呢?
- 《Alpa: Automating Inter- and Intra-Operator Parallelism for Distributed Deep Learning》 [Zheng et al. 2022]
- Alpa设置了intra-op 和 inter-op的两级并行架构
- Intra-op算子内并行:切分了tensor维度的并行方式,包括数据并行和算子并行。
- Inter-op算子间并行:不切分tensor,只是把子图进行不同的摆放分布,包括流水线并行。
- 如下图,左图为全部的搜索空间,右图为Alpa层次结构空间。算子间并行分为A和BCD,算子内并行则是将B水平或垂直分片并行。
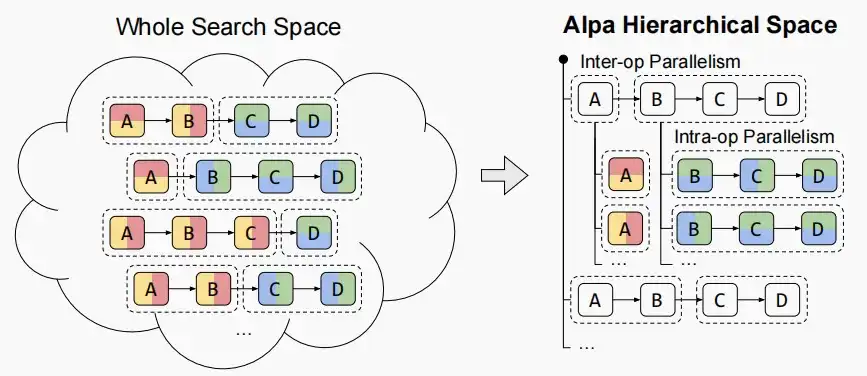
- 下图为Inter-op划分,图中两种例子中第二个更好,因为考虑到流水线并行需要GPU间等待,划分更加协调可以减少等待时间。
- Alph会自动进行计算,判断哪一种划分更加优异,无需手动选择。
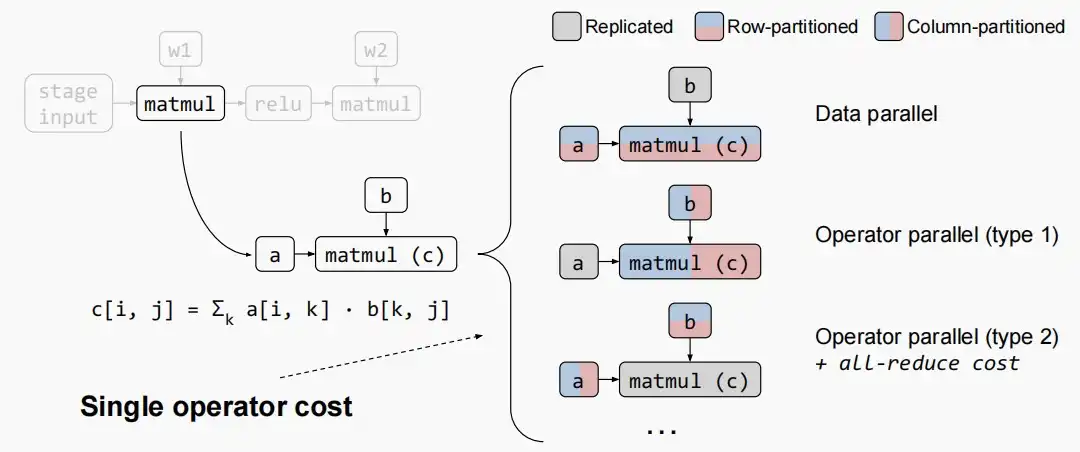
- 下图为Intra-op划分,对于一个矩阵乘法就有三种并行化方法,a为输入,b为权重。
- 第一种数据并行,a按行/列分片,b存储在多个GPU上副本。
- 第二种算子并行,a复制输入多个GPU,b按行/列分片存储在多个GPU上。
- 第三种算子并行+All-Reduce。
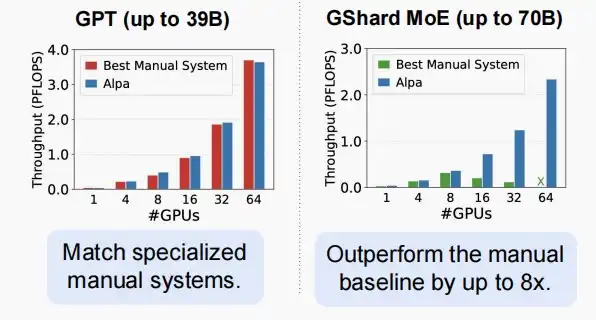
- Alph所做的,是一个针对分布式训练的统一编译器。
- 它首先确定最优的算子间路径,接着是算子内路径,然后将它们协调起来,执行运行时的编排工作。
- 它经过优化,实现了自动搜索,无需手动配置,并且在此情况下,也以相当大的优势超越了手动基准线。
二、Understand the bandwidth and latency bottleneck of distributed training
- 更大的数据-更大的模型-更多的计算资源-更多的内存,导致需要分布式训练,进而导致更加繁重的通信需求。
- 因此通信瓶颈也是一个值得关注的问题。
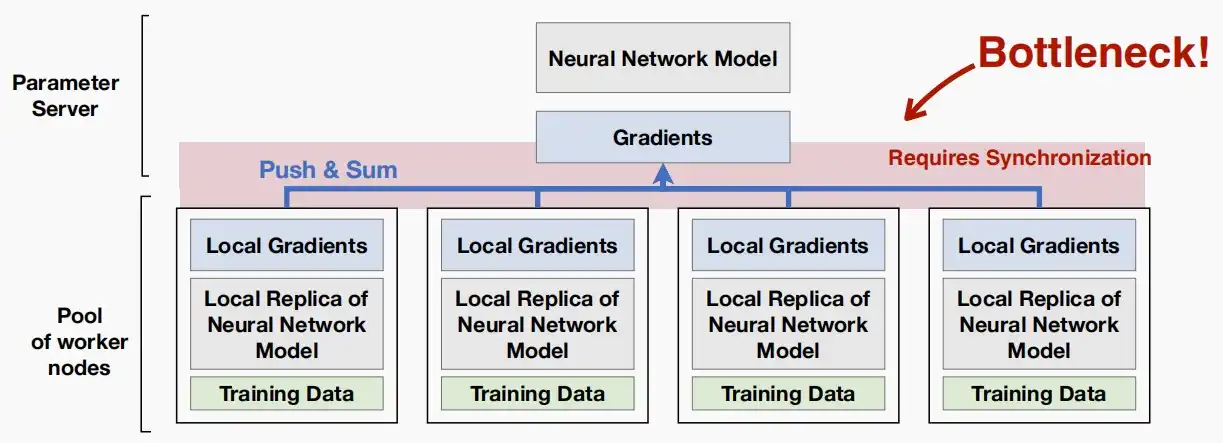
- 如下图中心参数服务器和工作节点的框架,初始化时需要将中心服务器的参数拷贝至工作节点,训练时需要将局部梯度从工作节点推至中心服务器,这可能会导致在扩展工作节点数时产生瓶颈。
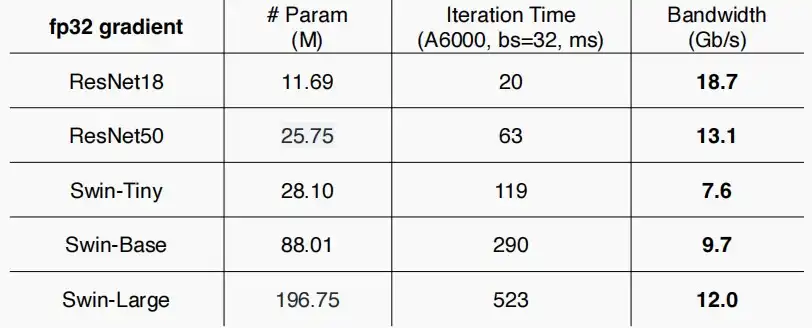
- 如下图,为常见视觉模型的通信带宽需求
- 根据迭代时间和参数量进行计算,假设每次迭代都需要发送一次参数或梯度,以此进行计算所需带宽。
- 模型越大,传输数据量越大,传输时间越长。
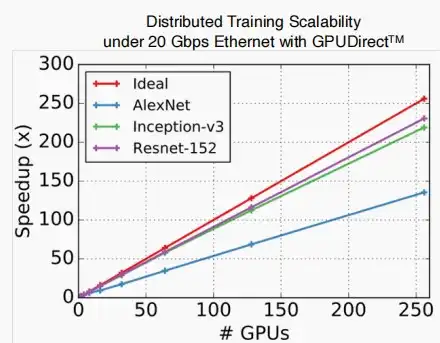
- 如下图,测试各模型在分布式训练情况下的可扩展性,理想情况下250个GPUs应该加速250×,但是实际情况低于理想情况,对于AlexNet甚至仅加速了140×。
- 原因是,模型越大,传输数据量越大,传输时间越长,导致GPU间通信时间较长,延迟更长,因此加速倍率下降。
- 网络带宽和内存带宽成为分布式训练的瓶颈。
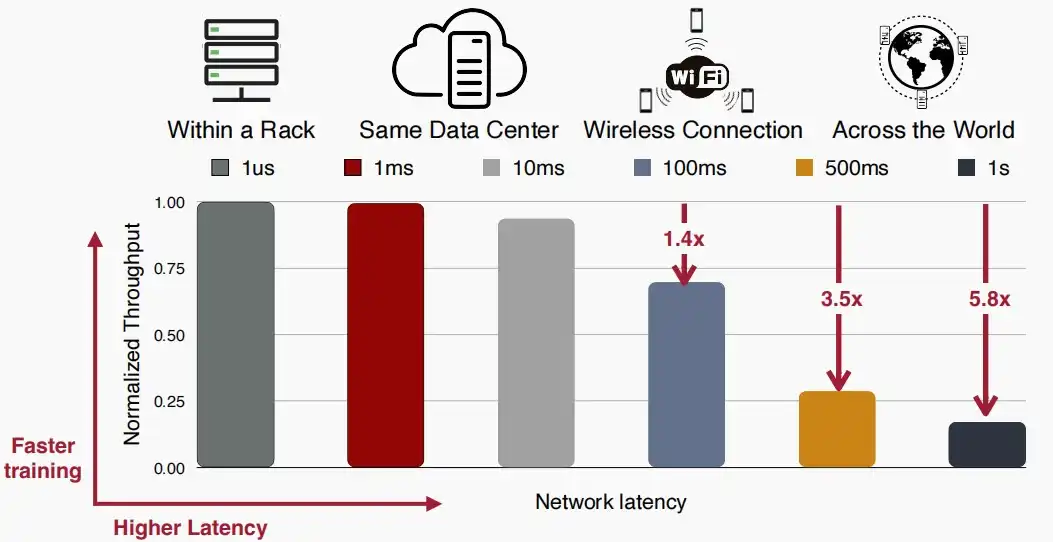
- 分布式训练中,不同的距离导致不同的延迟。
- 同一个机架内延迟仅为1us
- 同一数据中心延迟在1ms至10ms间,吞吐量与同一机架相差不大。
- 对于无线连接甚至是全球范围内进行分布式训练,将面临100ms至1000ms的延迟。
三、Gradient compression
- 对于分布式训练中,主要的通信集中在工作节点将梯度push至中心服务器,因此梯度压缩是解决通信瓶颈的主要方法。
- 如下图,主要有两种:剪枝与量化。剪枝后,原本密集的梯度变稀疏,梯度为0的值不需要发送。量化后,精度下降,同时需要传输的信息大小也下降。

Ⅰ、Gradient Pruning
1、Sparse Communication
- 《Sparse communication for distributed gradient descent》 [Alham Fikri et al 2017]
- 仅发送最大的k个梯度(按大小计算),但是使用了局部梯度积累,给较小梯度一个机会,使其累积到足够大,从而能够被发送出去。
- 利用残差\Delta_t,即原始稠密梯度与修剪后的稀疏梯度之间的差值,作为局部梯度。为了避免信息损失,我们计算剩余的局部梯度,直到这些梯度成为一个较大的梯度(达到阈值)再发送。
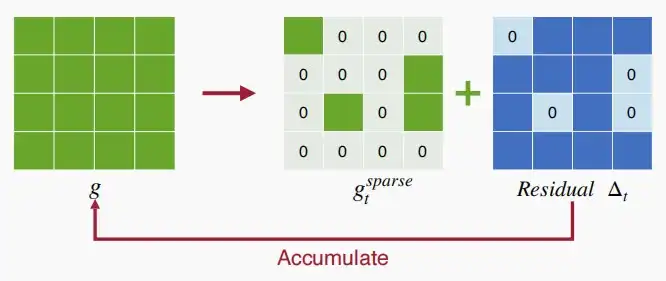
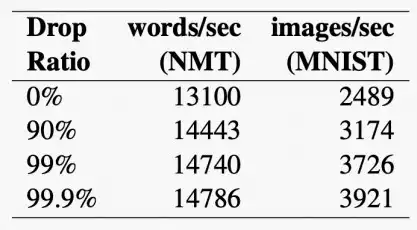
- 如下图,在Nvidia TitanX显卡上,使用梯度剪枝的加速效果,随着drop率的增大,每秒的处理数逐渐增大。
- 虽然适用于简单的神经网络,但在像ResNet-110这样的现代模型上产生了明显的精度下降。

- 为什么在使用梯度下降后会出现性能下降?
- 原因:Momentum(动量),这也是梯度压缩的局限性。
- 因此,提出了深度梯度压缩技术。
2、Deep Gradient Compression
- 本节主要介绍两篇论文《Deep Gradient Compression: Reducing the Communication Bandwidth for Distributed Training》 [Lin et al 2017] & 《PowerSGD: Practical Low-Rank Gradient Compression for Distributed Optimization》 [Vogels et al 2019]
DGC
- Momentum Correction
- 动量是对梯度下降的一种扩展,有助于克服有噪声梯度的局部最小值和振荡。
- 动量被广泛用于现代深度神经网络的训练。
- 动量的概念
- 在经典力学中,动量表示为物体的质量和速度的乘积,指的是运动物体的作用效果。
- 在进行梯度下降时,𝒖_𝑡 = 𝑚 ⋅ 𝒖_{𝑡−1} + 𝒈_t,其中g为梯度,u为速度,m为动量,得到更新后的速度方向和大小。接着,以w_t = w_{t-1}-\eta·u_t更新权重。
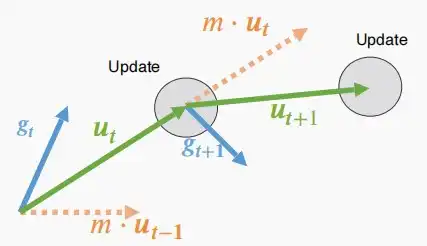
- 在稀疏通信中,修剪后的梯度在局部缓冲区中积累。
- 如果我们直接使用累积的缓冲区来进行动量计算,会发生什么?
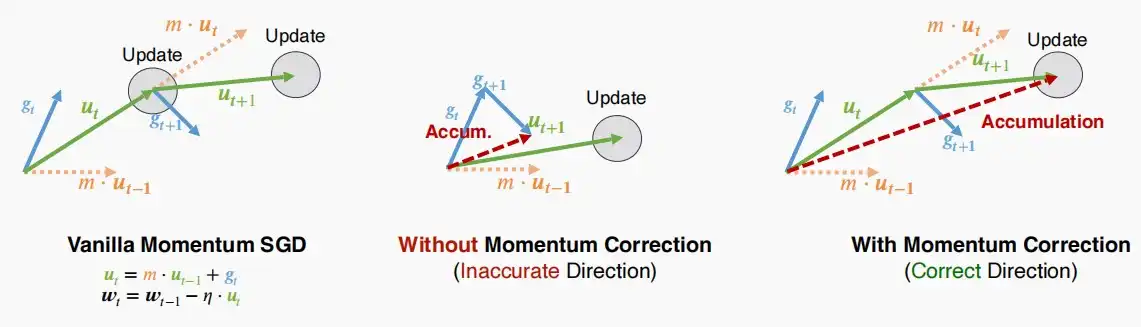
- 如下图中
- 左图是原始动量SGD,我们希望实现的,正确的方向。
- 中间是使用局部累计梯度作为动量的SGD,进行更新后的方向显然产生了不匹配。
- 右图是使用累计速度作为动量的SGC,更新的方向匹配左图,被称为动量修正Momentum Correction。
- Warm Up Training
- 原因
- 在训练的早期阶段,网络正在改变快速变化。
- 局部梯度积累和陈旧梯度会加剧这一问题。
- 预热
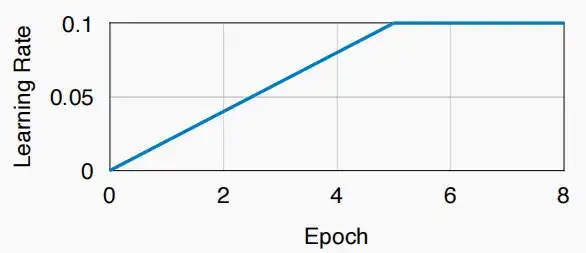
- 预热学习率
- 因此,论文提出对学习率进行预热,从较小的学习率开始,逐渐增大至0.1。
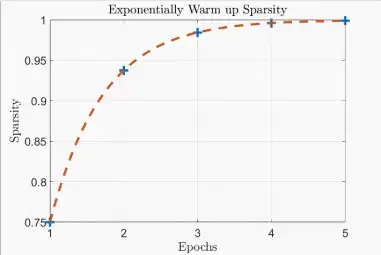
- 预热稀疏率
- 避免在稀疏性上的突然变化。
- 在前几个时期呈指数增长的稀疏性,→帮助优化器适应较大的稀疏性。
- 预热学习率
- Performance
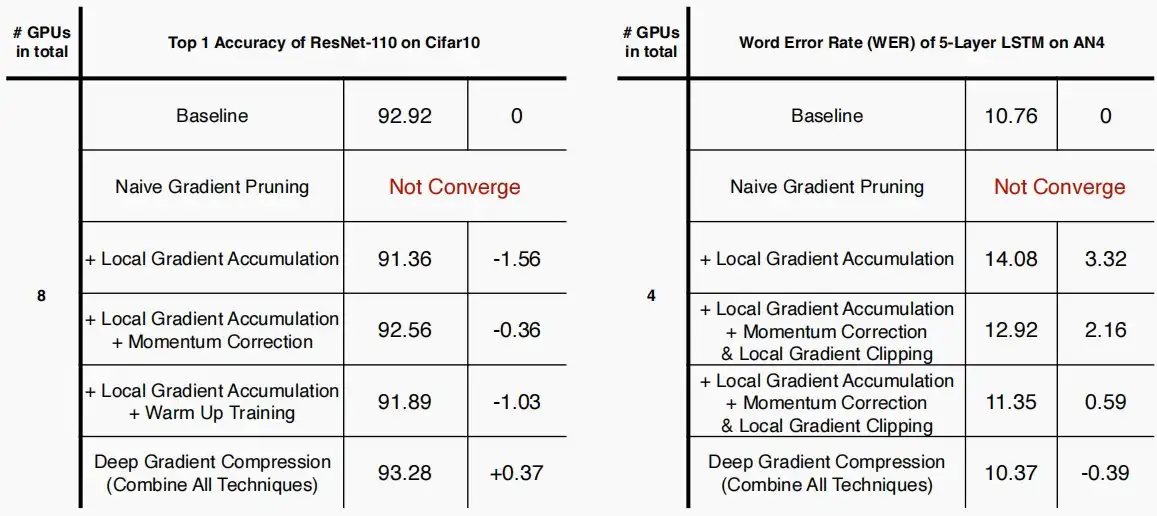
- 如下图,作者使用消融实验验证模型有效性,稀疏率设置为99%
- 原始梯度剪枝无法收敛。
- 单使用Local Gradient Accumulation,LSTM on AN4错误率变高,ResNet-110 on Cifar10的top-1准确率降低。
- 而若加上作者提出的Momentum Correction、Local Gradient Clipping和Warm Up Training三者其一,或者多个技术叠加后的DGC,都能缓解稀疏后的副作用,甚至DGC还超越了基线性能。
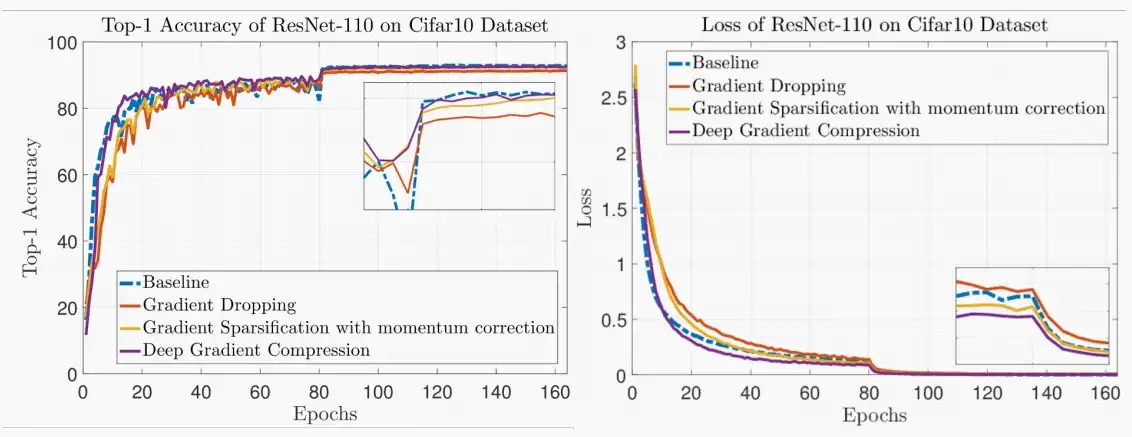
- 下图为,在数据集Cifar10、梯度剪枝稀疏率99.9%的条件下,训练准确率和损失图如下,当收敛后,DGC与基线是最拟合的。
- Problem
- 分布式训练中,需要每个工作节点获得其他工作节点的梯度的副本,而在All-Reduce时稀疏梯度会在此过程中变得更加密集。
- 例如,下图中是环All-Reduce,每个节点从邻居节点获得其梯度副本并进行归约,这将导致自己存储的副本越来越多 "1",稀疏度逐渐密集。
- 解决办法:
- 相同的稀疏性模式,粗粒度的稀疏性。
- 可能在环All-Reduce的中间修剪。
- 另一种克服这一潜在问题的方法是不采用稀疏性,而是采用低秩,即下面介绍的PowerSGD。
PowerSGD
- 《PowerSGD: Practical Low-Rank Gradient Compression for Distributed Optimization》 [Vogels et al 2019]
- 动机:解决梯度压缩中的不规则稀疏模式,防止梯度越来越密集。
- 方法:不再使用细粒度剪枝,而是采用低秩分解。
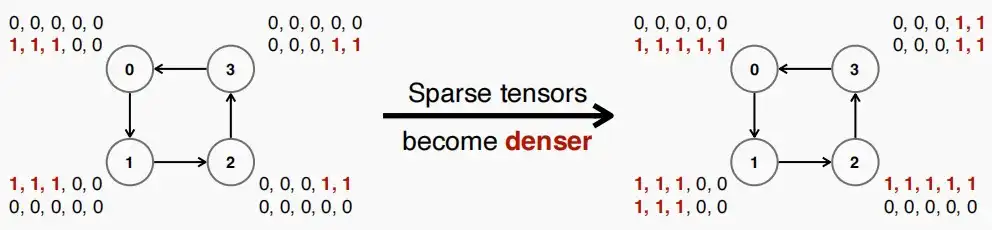
- 例如,下图中左边的DGC方法剪枝后具有不同的稀疏模式,进行reduce后稀疏系数增大,密集;而右边的采用低秩分解后,仅有八个元素,无论如何迭代reduce,都不会改变其稀疏模式。

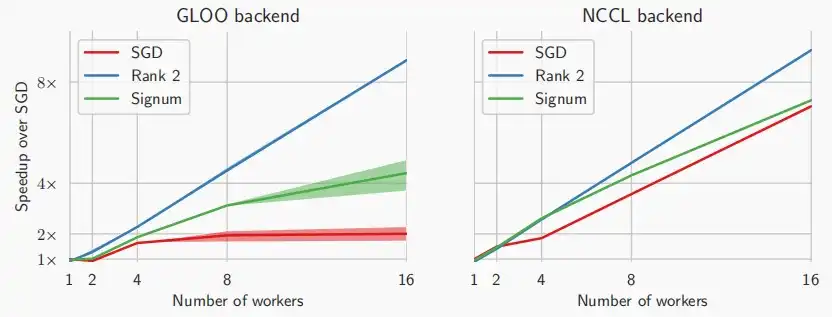
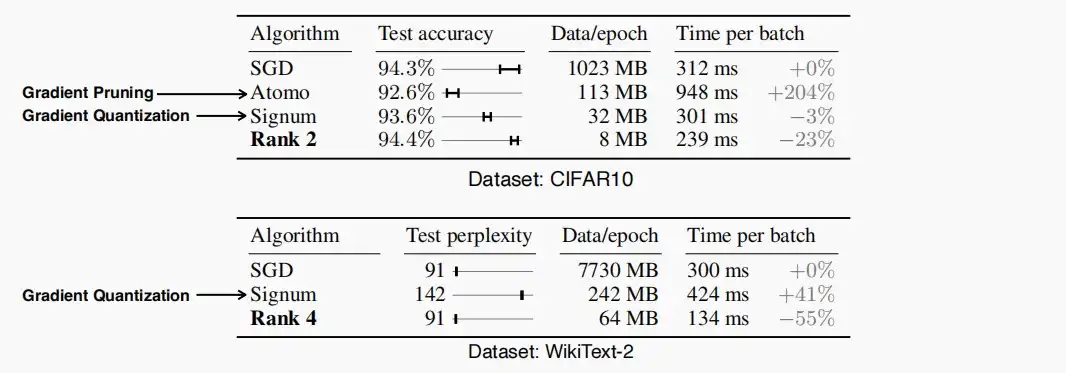
- 如下两图为延迟和精度评估,rank 2和rank 4即为PowerSGD,可以看到PowerSGD的延迟加速与工作节点数量呈线性关系,且高于其他方法。其降低所需转移的梯度数据大小,同时保持精度在相同的水平。
3、对比
-
Sparse Communication
- 局部梯度积累,给小梯度一个机会,使其累积到足够大,从而能够被发送出去。
- 但是只能达到比较低的稀疏度比。
-
DGC
- 主要提出了三种技术:动量校正,梯度裁剪和热身训练。
- 较高的稀疏度比(99.9%),同时保持准确性。
-
PowerSGD
- 选择低秩的修剪,而不是细粒度的修剪
Ⅱ、Gradient Quantization
-
1-Bit SGD
-
《1-bit stochastic gradient descent and its application to data-parallel distributed training of speech DNNs》 [Frank 2014]
-
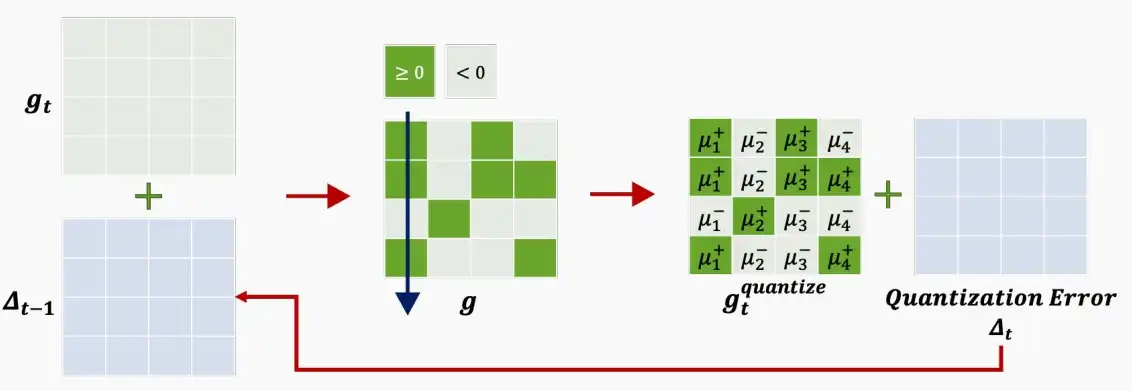
该文中提出了误差补偿方法将32bit梯度降为1bit梯度进行通信传输。
- 误差补偿:每次量化时,将上次梯度的量化误差加到本次梯度上,然后再进行量化。同理,本次梯度的量化误差也需要加到下次梯度当中。即下图中的\Delta_t。
-
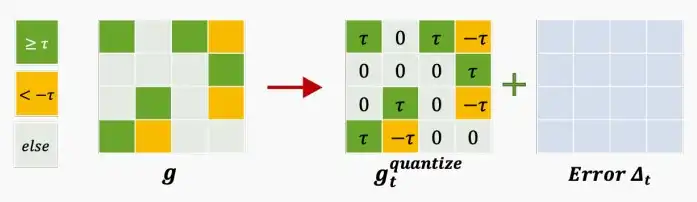
- Threshold Quantization
- 《Scalable distributed DNN training using commodity GPU cloud computing》 [Nikko 2015]
- 本文提出了一种基于阈值量化梯度的方法,基于经验先去决定阈值t的大小,t既是阈值也是重建值。
- 大于t的量化为+t,小于t的量化为-t,其他情况量化为0。
- TernGrad
- 《TernGrad: Ternary Gradients to Reduce Communication in Distributed Deep Learning》
- TernGrad不同于前面两种1 bit,TernGrad是2 bit方法,可以量化为-1、0、+1。
- TernGrad中为概率量化,即对于原梯度 g_i ,有 |g_i|/max(g) 的概率量化为+1/-1,符号取决于原符号,可知有1-|g_i|/max(g) 的概率量化为0。
- 这样可以保证量化后的梯度期望值仍为g_i,整个梯度的期望值不变。
- 没有量化误差积累,因为是动态的。
四、Delayed gradient update
- 带宽容易改善,但延迟很难。
- 带宽瓶颈可以通过梯度剪枝和梯度量化来改善,也可以升级硬件设施来改善,相对容易。
- 但延迟较难,一是物理上以光速从上海旅行到波士顿仍然需要162 ms,二是信号拥堵,城市的办公室和家庭造成了很多信号拥堵。
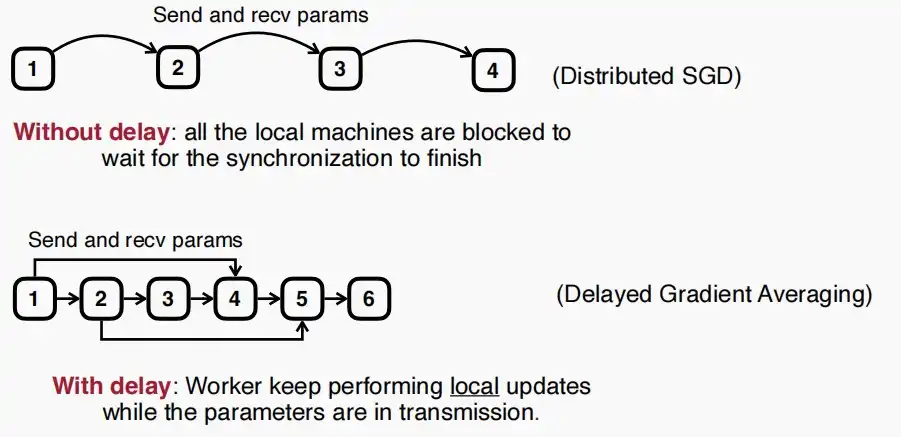
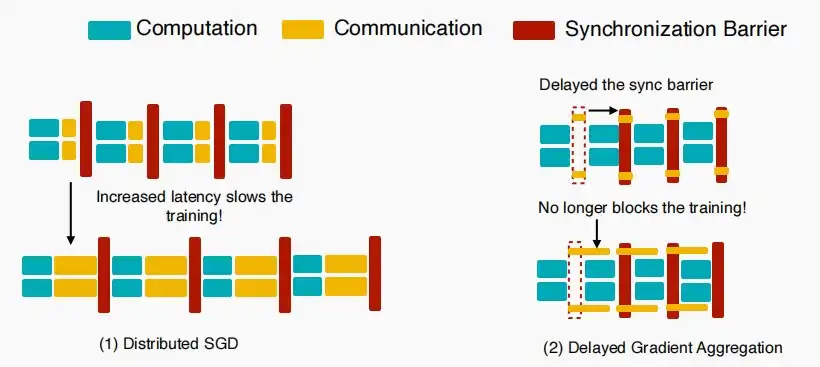
- Vanilla Distributed Synchronous SGD
- 如下图是传统的分布式同步SGD,局部更新和通信将按顺序执行,工作节点必须等待传输完成后再进行下一步操作。因此延迟对于分布式训练的效率影响巨大。
- 如何在高延迟条件下提高训练吞吐量?
- 我们可以允许旧梯度吗?所以我们可以重叠通信与计算两个部分。类比:允许先发布作业3,再要求提交作业2。

- 如下图所示,在第一轮发出局部参数后,继续进行第二轮迭代,而直至第四轮才从其他工作节点收到梯度,再应用这个梯度更新。
- 工作节点始终使用的是落后的梯度进行更新,但是无需像普通分布式SGD一样等待通信时间。
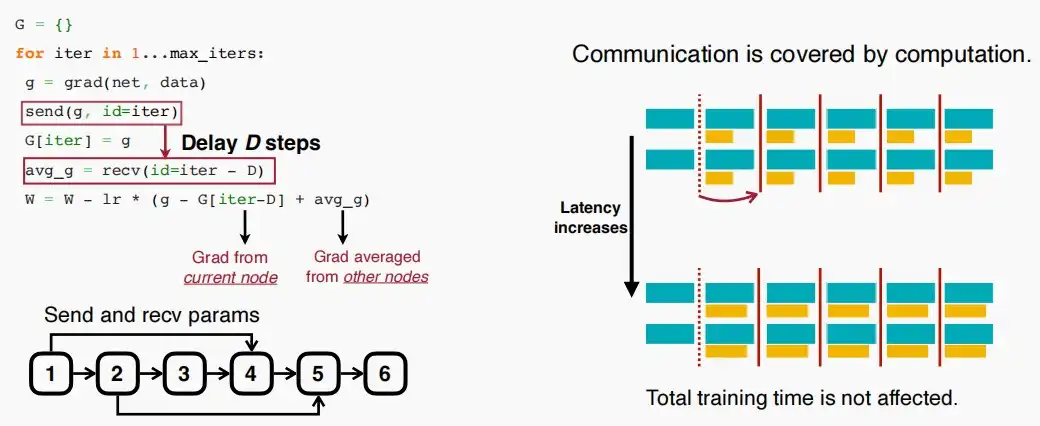
- 代码实现如下,注意send和recv的id之间具有差值D,即延迟的轮数;当更新参数时,使用的梯度是当前工作节点的局部梯度-当前工作节点iter-D的梯度+从其他节点发来的平均梯度。
- 如下图为分布式SGD与延迟梯度聚合SGD的流程对比图
- 对于延迟梯度更新只要传输在几轮的局部计算中完成,那么它就不会阻碍训练。
- 下列实验为对CIFAR、ImageNet以及语言模型任务的准确性评估。
- 可以看出延迟梯度更新DGA具有非常明显的加速比,远优于FedAvg,且准确性大致保持不变。