![[MIT6.5940] Lect 9 Knowledge Distillation](/upload/宏村.webp)
一、什么是知识蒸馏
-
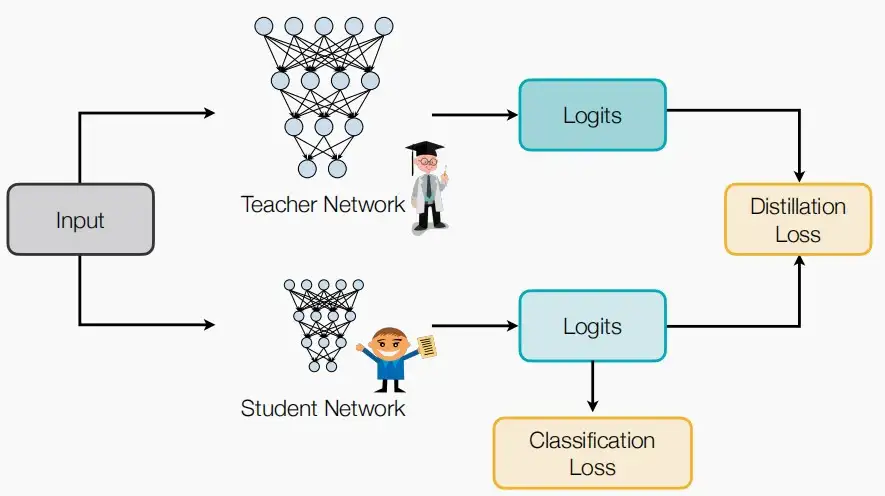
定义:知识蒸馏是一种从一个更大的模型中学习的过程,旨在将多个模型的知识蒸馏到一个更小的模型中。这种方法的关键是将大模型的知识传递给小模型,从而创建可以在边缘设备上使用的更小模型。
-
更大更复杂的模型作为教师网络,而更小更简单的模型作为学生模型。学生模型通过知识蒸馏来学习教师模型的逻辑,接近其类概率分布,以达到在准确性上接近教师模型。
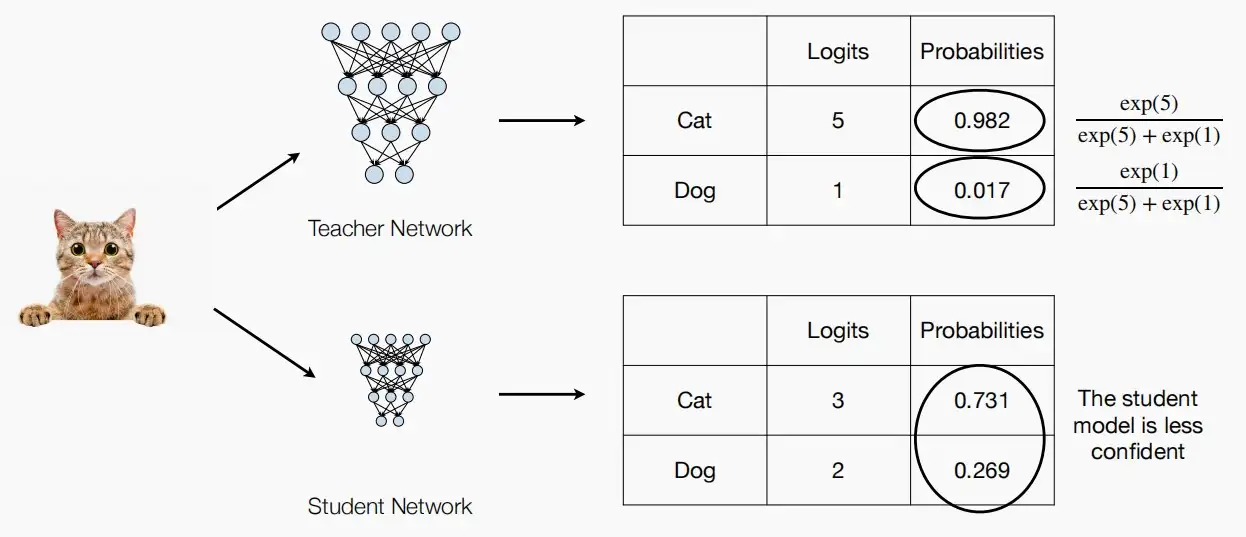
- 知识蒸馏中引入了温度T的概念
- 原本逻辑和分类概率的关系如下 p(z_i) = exp(z_i) / \sum_jexp(z_j)
- 引入温度T后,p(z_i,T) = exp(z_i/T) / \sum_j exp(z_j/T)
- 温度T通常设置为1。
二、匹配的内容
- 在知识蒸馏中,匹配(match)通常指的是学生网络和老师网络之间在特征表示上的相似程度。
- 匹配的内容,即从哪方面衡量两个网络的相似程度,常见的有以下六种:
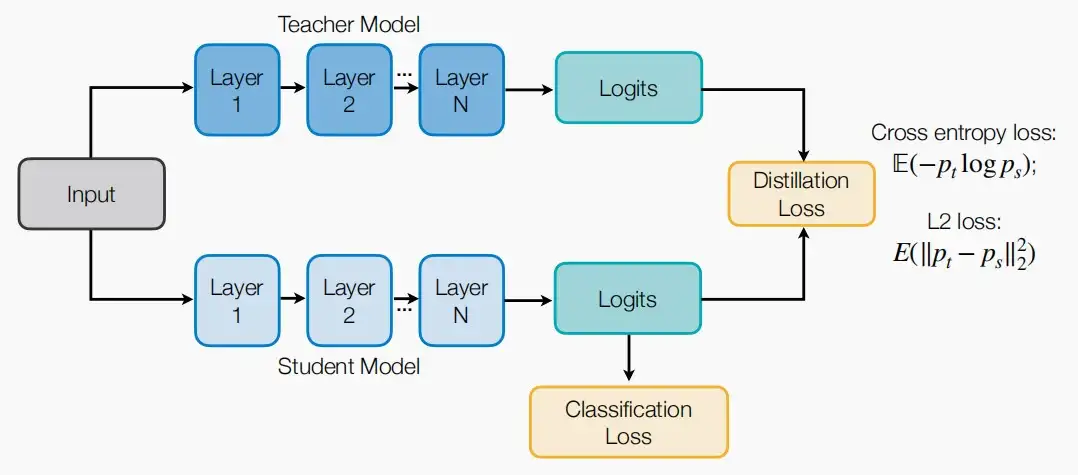
Ⅰ、输出逻辑
- 匹配输出逻辑是最简单且应用最广泛的。
- 如下图,对于最后的输出逻辑,可以采用交叉熵损失函数或L2损失函数来匹配逻辑。
Ⅱ、中间权重
- 我们还可以尝试匹配两个网络的中间权重。
- 由于两个网络的规模不同,无法直接计算两个网络之间的权重距离。因此可以添加一个逐元素的卷积层或增加一个全连接层来进行投影。
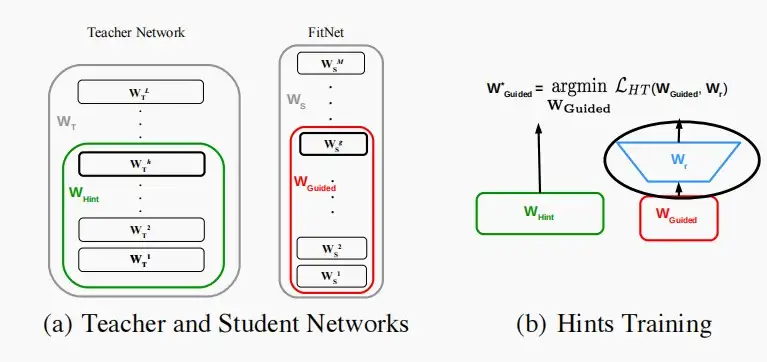
Ⅲ、中间特征
- 我们还可以匹配中间特征,不仅仅是权重,还包括中间特征本身,不仅是最后一个输出特征,即最后一个特征图,还包括中间特征图。
- 我们可以运用知识KD损失,以匹配中间特征图。
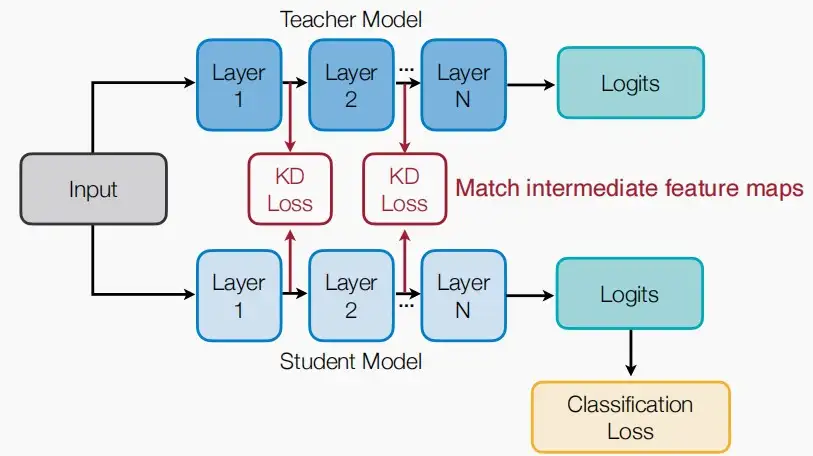
Ⅳ、梯度
- 利用特征图的梯度来描述DNNs的“注意力”,其中梯度是一个可以学习(匹配)的对象。如果梯度\frac{\partial f}{\partial x_{i,j}}很大,则代表在(i,j)位置一个微小的扰动将明显影响最后输出,这代表着网络对于(i,j)位置有更多的注意力。
- 因此梯度匹配,可以认为是特征图的注意力匹配。
- 如下图,三个模型准确性不同,但ResNets34和ResNets101的注意图彼此相似,而性能较差的NIN注意图有显著差异。
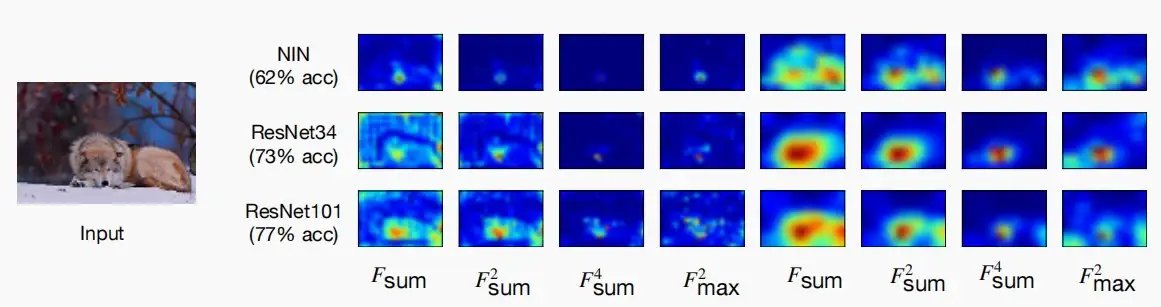
- 权重可能具有不同的维度,梯度也可能有不同的维度。我们可以利用线性投影,即全连接层,将输入映射确保能直接计算出输出距离。
Ⅴ、稀疏模式
- 在ReLU激活后,教师和学生网络应该具有相似的稀疏性模式。
- 如果一个神经元的值大于0,则它在ReLU后被激活,如果值小于0,则不被激活,用指示器函数ρ(x)表示。
ρ(x) = \begin{cases}
1 & x>0\\
0 & x\leq0
\end{cases}
Ⅵ、关系信息
- 在之前的讨论中仅尝试了匹配单个点的情况。而在此处,尝试匹配输入通过该模块前后之间的关系,即关系信息。
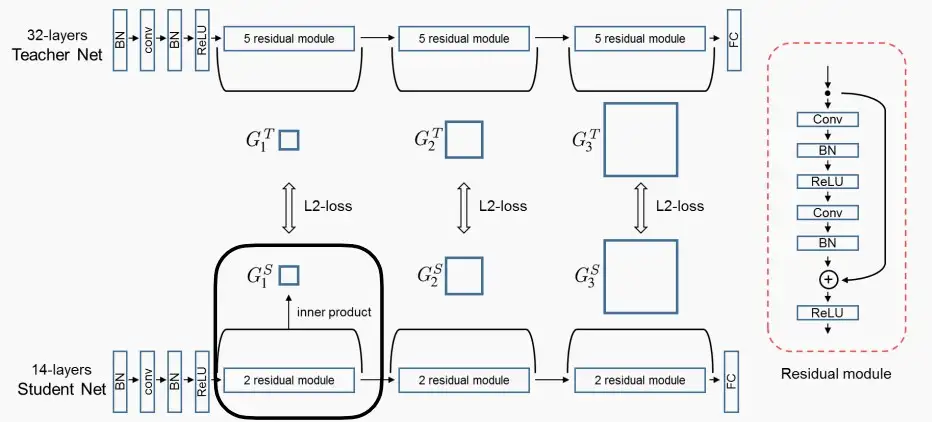
- 例如下图中,我们可以使用内积来提取关系信息,即G = C_{in} × C_{out},然后比较学生网络和老师网络(G_1^T,G_1^S)。
- 学生和教师网络只在层数上有所不同,而不是通道数。
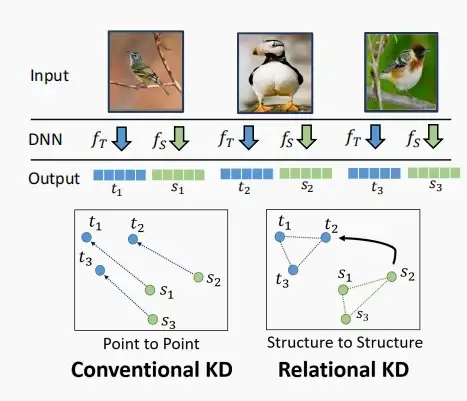
- 也可以尝试匹配不同样本间的关系。
- 例如下图中,对于三个输入图像,经过老师网络输出(t_1,t_2,t_3),经过学生网络输出(s_1,s_2,s_3)。
- 对于传统的知识蒸馏,旨在最小化每一对(t_i,s_i)之间的距离。
- 对于基于关系的知识蒸馏,旨在相似t_i和s_i之间的相对关系图。
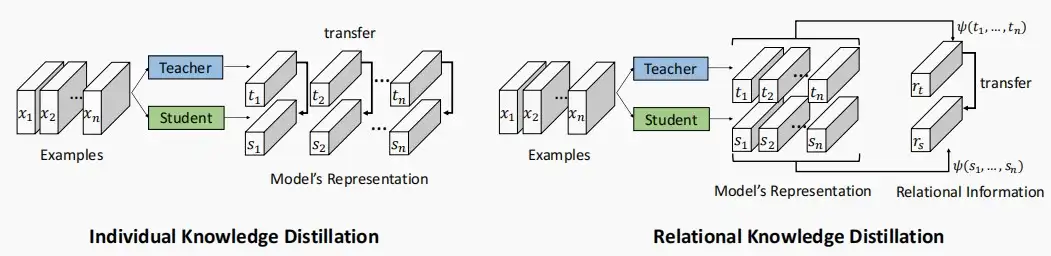
- 除此以外,还可以研究多个样本输出的关系信息。
- 如下图,独立知识蒸馏中,单独匹配每个样本输出之间的距离;关系知识蒸馏中,匹配所有输出特征向量的成对距离\Psi。
\Psi = (||s_1 - s_2||^2_2,||s_1-s_3||^2_2,...,||s_{n-1} - s_n||^2_2)
三、自蒸馏和在线蒸馏
Ⅰ、自蒸馏
固定式的教师网络的缺点是什么?一定需要吗?
答:不是一定需要的,固定式的教师网络需要更大的开销,可以采用自蒸馏。
- Self-Distillation with Born-Again NNs
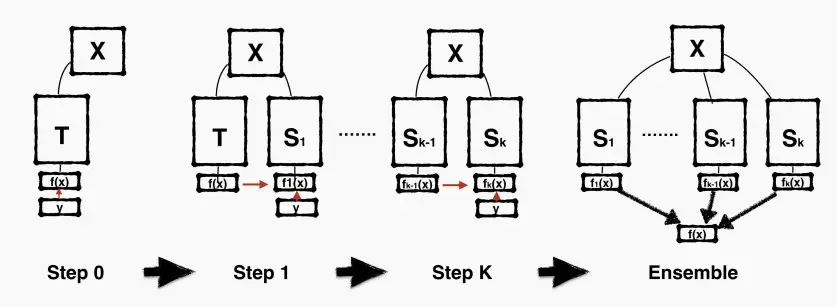
- 重生网络增加了迭代训练阶段,并在后续阶段同时使用分类目标和蒸馏目标。
- Step0,初始化模型T,输入后得到输出,并利用给定的标签进行训练,但并不训练至收敛。
- Step1,得到第一代学生模型S_1,学生收到的反馈和监督不仅来自标签,还有前一代的输出结果,及其父作为监督者。迭代重复,得到S_2,S_3,...,S_k。
- 迭代训练阶段,每一个模型的架构相同,即T,S_1,S_2,...,S_k的架构相同,但准确性不断提高。
- 由于架构相同,在最后可以采用交替集成/加权平均集成等方法得到性能更高的最终模型。
Ⅱ、在线蒸馏
- 教师模型不一定非得比学生模型大,学生模型不一定非得比教师模型小,两者可以相等。
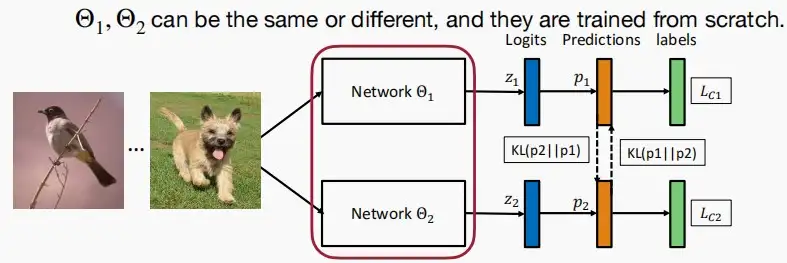
- Deep Mutual Learning深度相互学习
- 在深度相互学习中,没有明确区分教师与学生,而是两个“学生”均从零初始化,并一同启动训练,不需要提前预训练教师模型。
- 此处,损失包含两个部分:交叉熵损失和KL散度。
- 交叉熵损失:给定输入,模型的预测与标签之间的交叉熵损失。
- KL散度:两个学生模型预测之间的KL散度。既可以是最终输出的标签,也可以是中间数据量。
- 两个模型的大小、架构和容量可以保持一致,但这不是必要的。
- 使用两个“学生”模型的优势?
- 可以拥有额外的监督和稍微更大的容量。
- 防止出现不良的初始化。
L(S_1) = CrossEntropy(S_1(I),y) + KL(S_1(I),S_2(I))
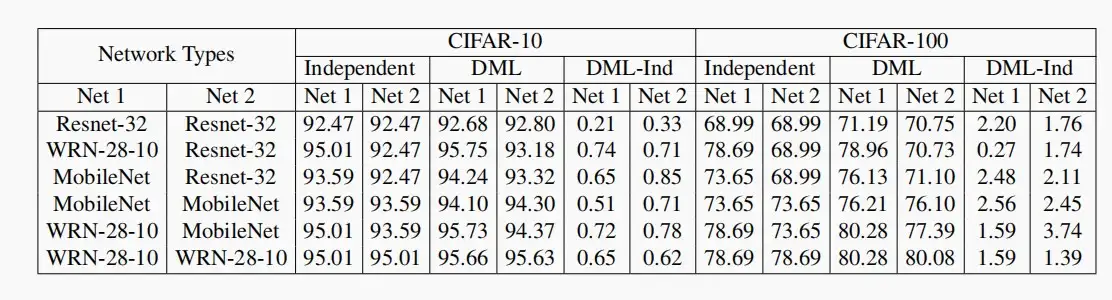
- 对于数据集CIFAR-10和CIFAR-100,分别使用独立训练和DML(Deep Mutual Learning)进行测试,发现使用DML后准确性都有所提高。
Ⅲ、两者结合
- 将在线蒸馏与自蒸馏相结合
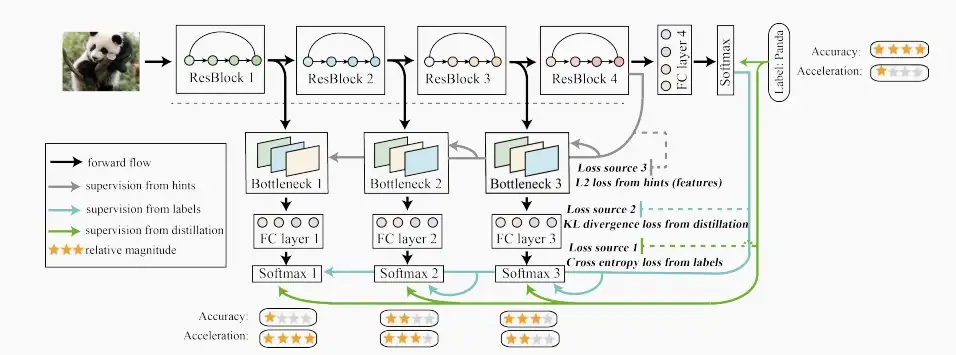
- 经典论文:《Be Your Own Teacher: deep supervision + distillation》
- 整体来看整个训练过程的思想就是最深层layer去蒸馏和监督浅层的各个Blocks。黑色虚线下方的Bottlenecks、FC Layers、Softmaxs这些都是训练时为了方便蒸馏和监督时加入的模块,在inference的时候是不需要这些的,因此不会增加任何推理计算成本。
- 整个模型的损失公式分为三部分,loss = I_1 + I_2 + I_3 :
- I_1是交叉熵损失,I_1 = (1-\alpha)*CrossEntropy(q^i,y),其中q^i是第i个softmax层分类器的输出,即模型预测结果与标签之间的交叉熵损失。
- I_2是KL散度,I_2 = \alpha * KL(q^i,q^C),其中q^i是第i个softmax层分类器的输出,q^C是最深层softmax层分类器的输出。
- I_3是特征损失,I_3 = \lambda * ||F_i - F_C||_2^2,其中F_i就是第i个bottleneck的feature输出,F_C就是最深bottleneck的feature输出。
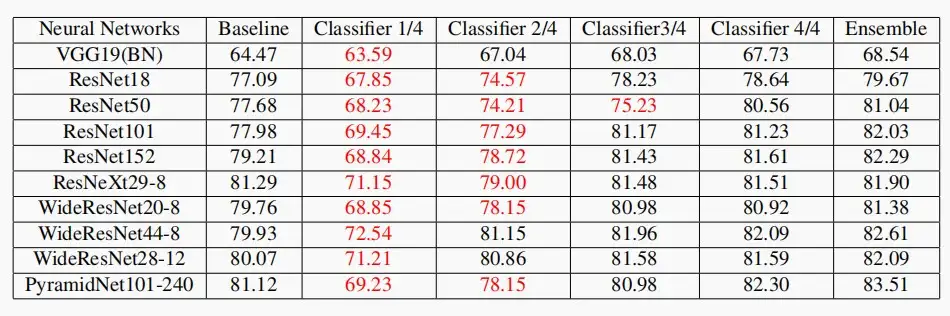
- CIFAR100的结果显示,比基线有一致的性能改进。
- 来自中间分类器(1/4、2/4、3/4)的预测有时会优于基线。因此,可以提高推理效率。
四、不同任务的蒸馏
- 蒸馏不仅局限于分类任务,还包括多样化的任务,接下来介绍几种常见的任务。
Ⅰ、KD for 目标检测
- 《Learning Efficient Object Detection Models with Knowledge Distillation》[Chen et al., NeurIPS 2017]
- 与图像分类相比,将蒸馏技术应用于多类目标检测具有挑战性,原因有几个。
- 检测模型的性能会随着压缩而进一步下降,因为检测标签的成本更高,因此检测模型的性能在压缩时会更受影响。
- 对分类进行知识蒸馏时假设每个类别都同等重要,而对于背景类别更为普遍的检测,情况并非如此。
- 检测是一项更复杂的任务,它结合了分类和边界框回归的元素。
- 一个额外的挑战是,我们专注于在同一领域(同一数据集的图像)内传输知识,而没有额外的数据或标签,而其他工作可能依赖于来自其他领域的数据(如高质量和低质量的图像领域,或图像和深度领域)。
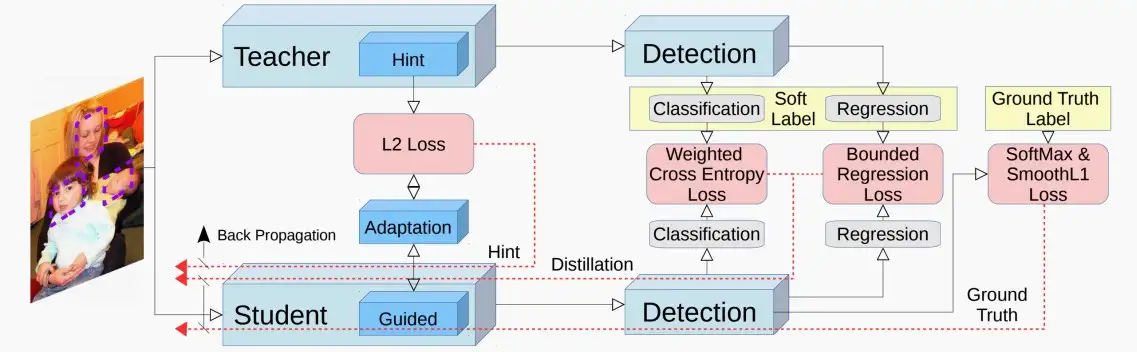
- 在该论文中,架构图如下
- 主要分为三个部分:主干网络、分类任务和回归任务。
- 主干网络,使用hint learning进行蒸馏,L_{Hint}(V,Z)=||V-Z||_2^2,其中V,Z分别是教师和学生网络的特征向量。为了使向量形状相同,使用adaption layer(1*1卷积/全连接层)使得维度大小相同。
- 分类任务,对于分类损失中的背景误分概率占比较高的情况,作者提出增大蒸馏交叉熵中背景类的权重来解决失衡问题。L_{soft}(P_S,P_t) = -\sum w_cP_t\log{P_s},令背景类的w_c = 1,目标类的w_c = 1.5。
- 回归任务,由于回归的输出是无界的,且教师网络的预测方向可能与groundtruth的方向相反。因此,利用教师的预测作为学生要达到的上限。一旦学生的质量以一定的差距超过教师,损失就变为零。公式略。
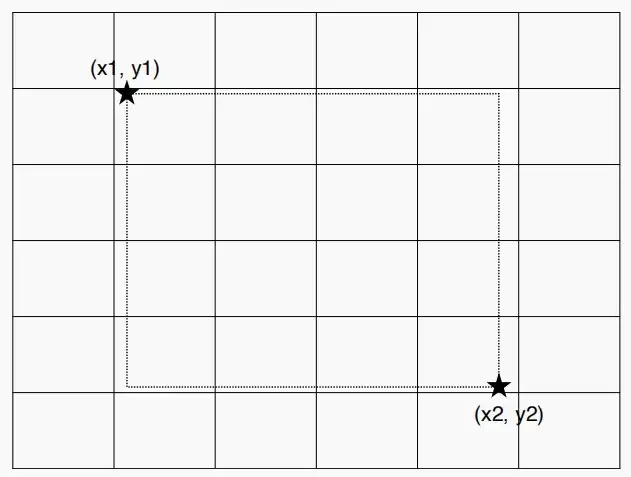
如何将边界框回归转换为分类问题?
例如要查找边界框的边界坐标(x_1,y_1)\&(x_2,y_2),可以将y轴分成6个箱子,并将x轴分成6个箱子,则变成一个六分类问题。
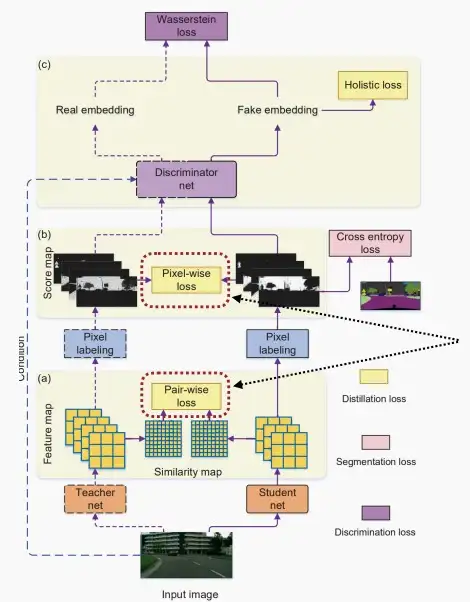
Ⅱ、KD for 分割
- 《Structured Knowledge Distillation for Semantic Segmentation》 [Liu et al., CVPR 2019]
- 文章中引入了判别器网络,它试图提供对抗性损失。
- 从流程图可以看出,学生网络和教师网络分别对同一输入图片做出像素标注,判别器网络分别对像素标注打分。尝试采用GAN方法训练判别器网络,确保学生和教师的得分非常接近,以至于能够欺骗判别器网络。同时训练判别器,使其具备准确的判断力。因此判别器和学生网络共同提升。
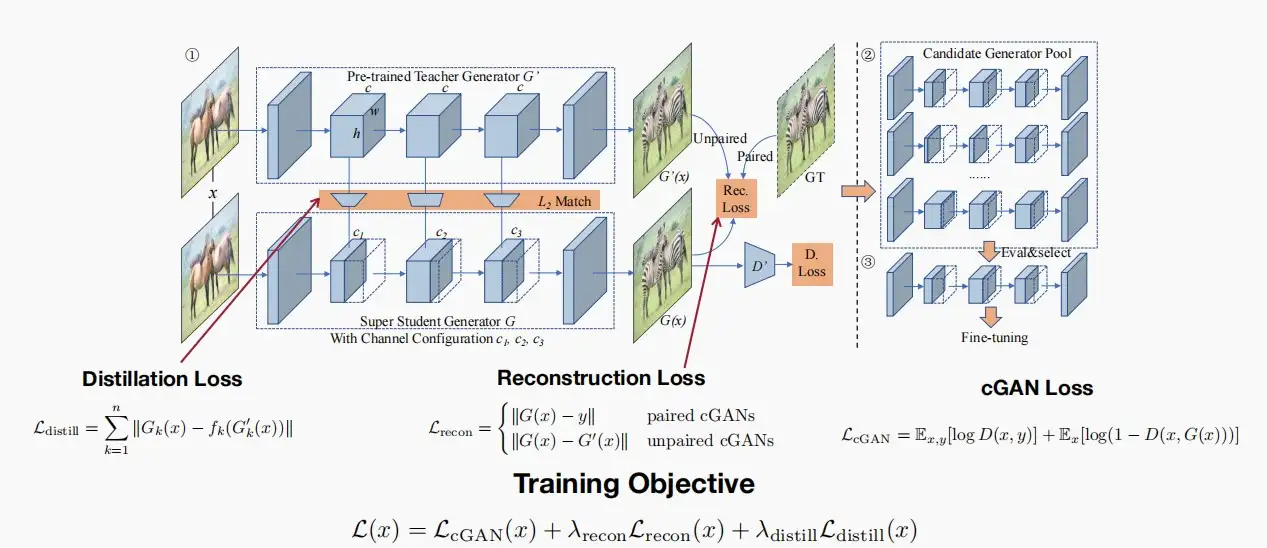
Ⅲ、KD for GAN
- 《GAN Compression: Efficient Architectures for Interactive Conditional GANs》 [Li et al., CVPR 2020]
- 在本文中,训练目标由以下三个损失组成:
L(x) = L_{cGAN}(x) + \lambda_{recon}L_{recon}(x) + \lambda_{distill}L_{distill}(x)
- 常规的蒸馏损失L_{distill}
- 条件GAN损失L_{cGAN}
- 重建损失L_{recon}:对于成对条件GAN,我们可以利用真实数据来监督生成的图像;对于非成对条件GAN,我们尝试利用教师生成的图像,使其与学生生成的图像相匹配。
- 除此以外,本文中作者将神经架构搜索与蒸馏相结合,在训练过程中有一个候选模型生成池,可以选择一个池化通道或部分通道,以及子网络的不同部分,类似于Lect7&8中的OFA网络。
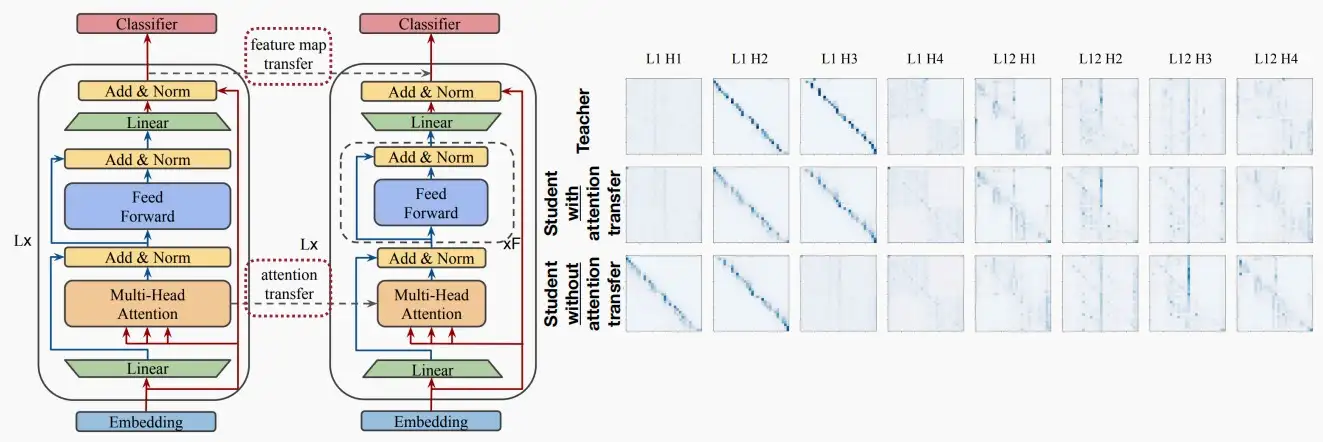
Ⅳ、KD for NLP
- 知识蒸馏同样可以用于NLP任务中,在NLP任务中进行匹配的通常是注意力图。
五、网络增强
网络增强、数据增强、Dropout
- 数据增强是解决过拟合问题,而网络增强是解决欠拟合问题,两者用途正好相反。
- 数据增强:用于解决过拟合问题,因此若模型规模较大而数据量不足,可以采用数据增强,包括:裁剪部分区域、混色、自动增强颜色和旋转等。
- Dropout:同样用于解决过拟合问题,在训练阶段随机移除部分激活神经元,而在推理阶段全部激活。类似的还有SpatialDropout、DropBlock。
- 网络增强:用于解决欠拟合问题。Dropout和数据增强会降低微型模型的准确率,因为小魔仙往往是欠拟合的,这就需要使用网络增强来提高准确率。
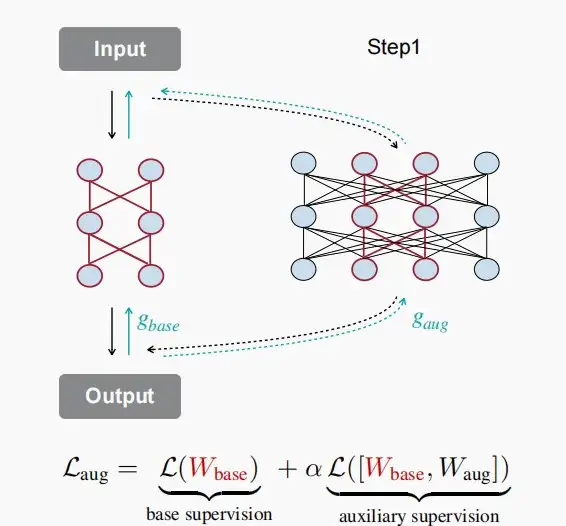
- 《Network Augmentation for Tiny Deep Learning》[Cai et al., ICLR 2022]
- 在本文中,构建了一个增强模型,而基础模型是增强模型的子集,就像once-for-all网络一样。
- 在给定输入和输出的情况下,我们不仅要通过前向和后向传播来获取基础模型的损失,还要从这个增强模型中获取梯度。
- 在每一步中采样不同的增强模型,来获得实际额外的监督。总的loss函数如下:
L_{aug} = L(W_{base}) + \alpha L([W_{base},W_{aug\_1}])+...+ \alpha L([W_{base},W_{aug\_n}])
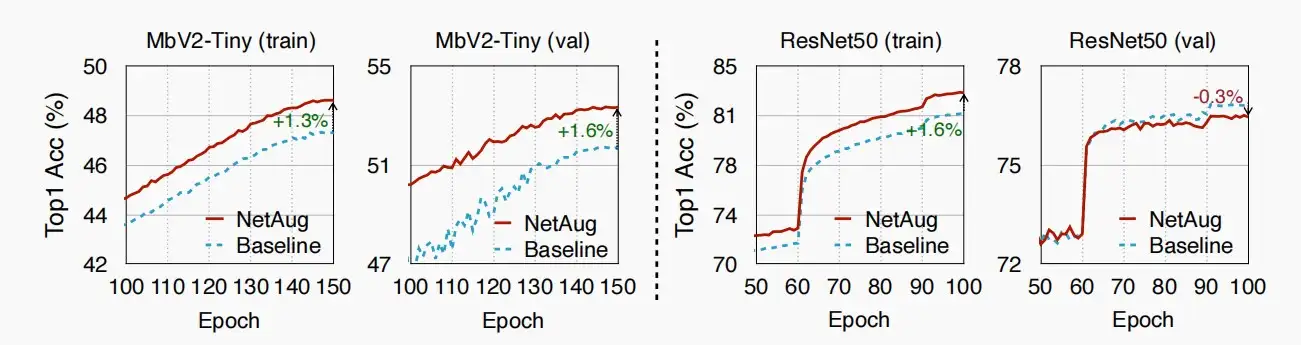
- 如图,使用网络增强的NetAug可以提升微型网络的训练精度和验证精度,但对于大型模型提升训练精度,且降低验证精度。
- NetAug与KD结合效果图