![[MIT6.5940] Lect 10 MCUNet: TinyML on Microcontrollers](/upload/宏村.webp)
一、什么是TinyML
- 随着时间推移和AI发展,模型大小急剧增加,因此我们需要新的算法和硬件来实现TinyML和Green AI,低能耗,低延迟,低成本,更好的隐私,以便我们能在本地设备上运行机器学习应用。
- 将深度学习压缩到物联网设备中。
- 全球有数十亿台基于微控制器的物联网设备。
- 低成本:低收入人群能够负担得起机会。民主化人工智能。
- 低功耗:绿色人工智能,减少碳排放。
- 各种应用:智能家居、智能制造、智能健康设备和精准农业等
二、TinyML的挑战
-
权重和激活在内存方面的约束条件是什么?
- 输入激活和输出激活,我们必须将其存储在可读写的内存(SRAM)中
- 但对于核和权重,我们可以将它们存储在闪存中(也可以在DRAM,但是微控制器通常没有DRAM)
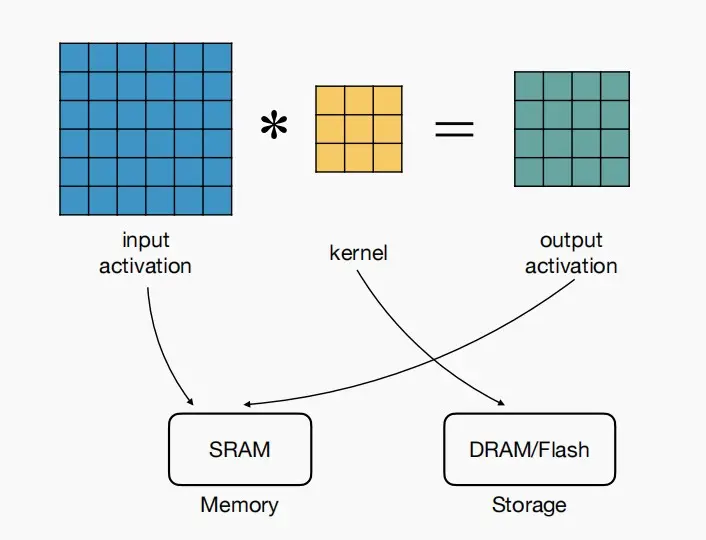
- Flash用途
- =模型大小
- 静态的,需要保持整个模型
- SRAM用途
- =输入激活+输出激活
- 动态的,每一层大小都不同
- 由于每一层都需要计算新的激活值,因此关注峰值SRAM
- 权重不计算,因为它们可以部分存取
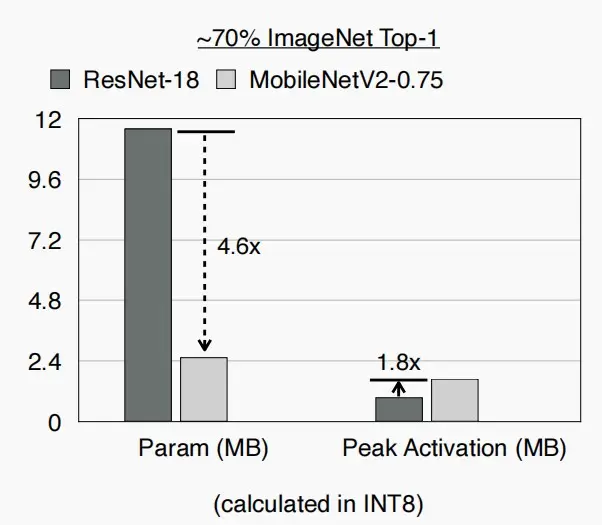
- 因此,我们不仅希望减小模型大小,也希望减小激活大小。
- 两者并不是同一个问题,如图中模型大小减小4.6×,但是激活大小反而增加了1.8×
- 本lect即将介绍的MCUNet不仅减少模型大小,而且减少激活大小。
三、微型神经网络设计
Ⅰ、MCUNet: System-Algorithm Co-design
- 三个研究方向
- 1、在给定的推理库基础上,目标寻找能够快速运行的最佳模型架构(NAS)。
- 2、针对给定神经网络,目标开发设计推理库与推理引擎。
- 3、神经架构搜索和推理引擎共同设计。
- 神经架构搜索为推理引擎提供高效的神经架构。
- 推理引擎为神经架构搜索提供非常高效的编译器与运行时环境,以支持这些高效模型的运行。
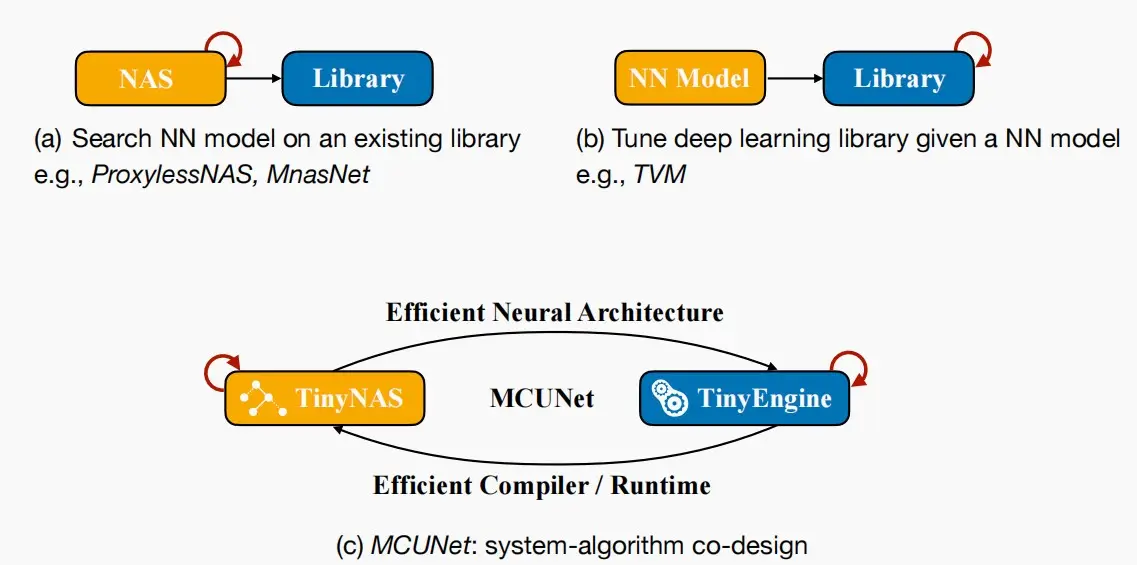
- 本节课介绍TinyNAS,下一课介绍TinyEngine
Ⅱ、TinyNAS: Two-Stage NAS for Tiny Memory Constraints
问题:什么是正确的搜索空间?
- 搜索空间的质量在很大程度上决定了搜索模型的性能。在完整的网络空间中,可能存在多个更优的子空间。
- 选项1:重复利用曾经为移动AI(例:MobileNet、MnasNet)精心设计的搜索空间。
- 搜索空间中最小的子网络由于巨大的差距而无法适应硬件。
- 选项2:为物联网设备选择一个搜索空间(更明智的选择)
问题:如何扩展类似于MBNet-alike的搜索空间?
- 我们可以通过使用不同的width multiplier宽度因子W和resolution multiplier分辨率因子R来缩放类似mbnet的搜索空间。
- width multiplier主要是按比例减少输入输出通道数,resolution multiplier主要是按比例降低特征图的大小。--《Efficient Convolutional Neural Networks for Mobile Vision Applications》
- 一个特定的R和W会得到一个子搜索空间。
- 例如:智能手机适合R=224,W=1.0;GPUs适合R=224,W=1.4。
- TinyNAS主要分为两个阶段:
- 设计搜索空间:在给定的内存和存储限制下,首先推导出一个优化的子空间,即确定W和R参数,随后在该子空间中研究。
- 搜索子网络:确定核大小、扩展比率、块数量等参数。
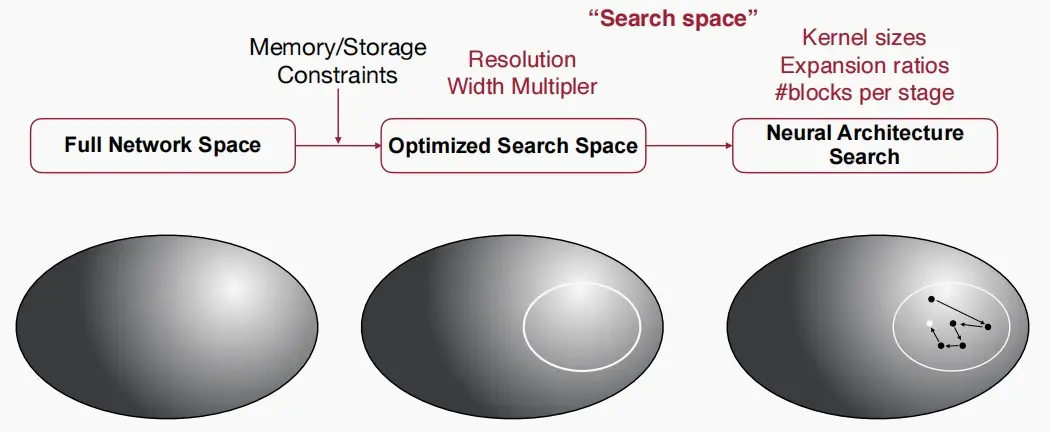
- 自动搜索空间优化
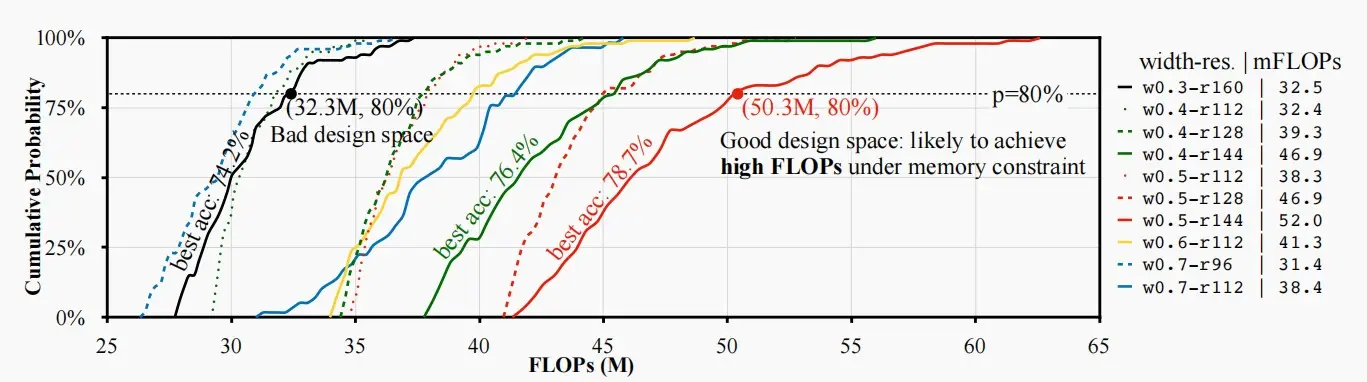
- 如何衡量搜索空间是否良好?
- 直接训练模型获取准确度进行比较,成本较大,因此考虑使用FLOPs进行近似。
- 分析每个搜索空间中模型的FLOPs分布:更大的FLOPs ->更大的模型容量->更有可能提供更高的精度。
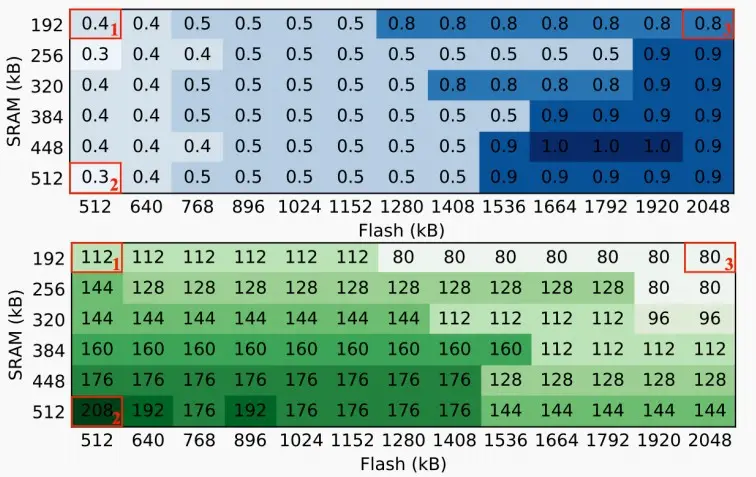
- 如下图中,红色线代表的搜索空间最佳,其中W=0.5,R=144。
- 对于不同大小的SRAM和Flash,寻找最佳配置(W,R)
- 横坐标为SRAM大小,纵坐标为Flash大小,上图表格为宽度W(代表着通道数量),下图表格为分辨率R。
- 当仅增加SRAM大小时,分辨率R更大。 SRAM决定激活大小,激活大小=分辨率×分辨率×输入通道×输出通道,而Flash大小不变->输入通道和输出通道不变,因此导致宽度W和通道数量大致保持不变,分辨率R增大。
- 当仅增加Flash大小时,宽度W增大,分辨率R减小。 Flash增大导致容纳的模型大小增大,输入输出通道增大,即宽度W增大,而SRAM不变决定激活大小不变,因此分辨率R降低。
- 资源受限的模型专业化
- 在缩小设计空间后,我们可以执行Once-for-All架构搜索,随机抽样网络,微调该模型,寻找到最佳的子网络。
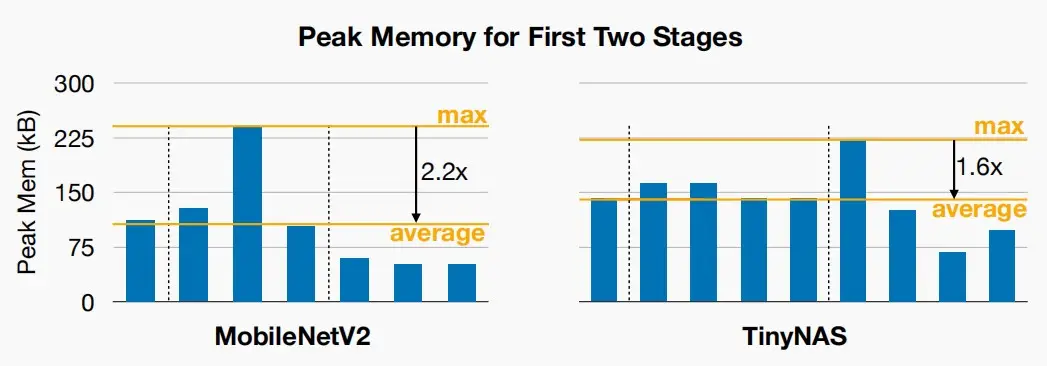
- TinyNAS更好的利用内存
- TinyNAS为每个块设计具有更统一的峰值内存的网络,允许我们在相同数量的内存下适应一个更大的模型。
- 人工设计与MCUNet对比
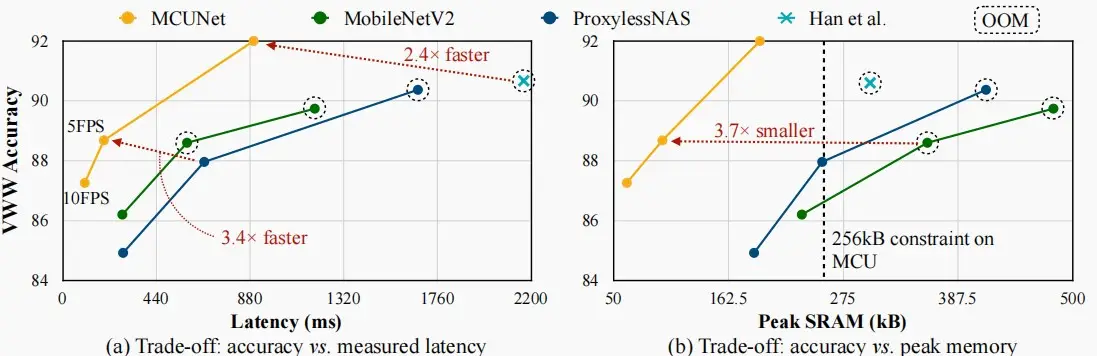
- 下图中,Han et al指人工设计网络的表现,左图为延迟与准确率的关系,右图为峰值内存与准确率的关系,实验数据集为Visual Wake Words。
- 从左图可以看出MCUNet相比于人工设计有2.4×的延迟提升,与MobileNetV2也有3.4×的提升。
- 从右图可以看出,对于256kB的微控制器内存限制,只有MCUNet可以避免OOM。
Ⅲ、MCUNetV2: Patch-based Inference
Imbalanced Memory Distribution of CNNs
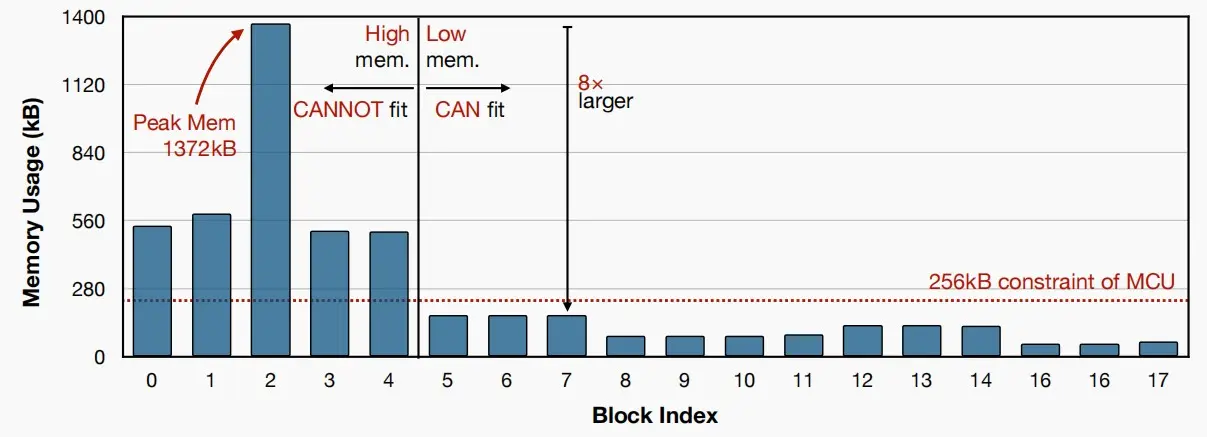
- 如下图是MobileNetV2的各块SRAM用量,可以看出前几个阶段峰值极高,这是限制部署到边缘端的瓶颈。
- 由于MobileNetV2前几个阶段分辨率较高,都使用了大约三个卷积核,大量的激活导致了对SRAM需求较高。
- 我们知道在后面阶段SRAM需求下降是因为进行了下采样,每下采样一次,内存即缩小四倍。
- 若我们能减少这一初始阶段的内存使用,便能降低整体内存消耗。
1. Saving Memory with Patch-based Inference
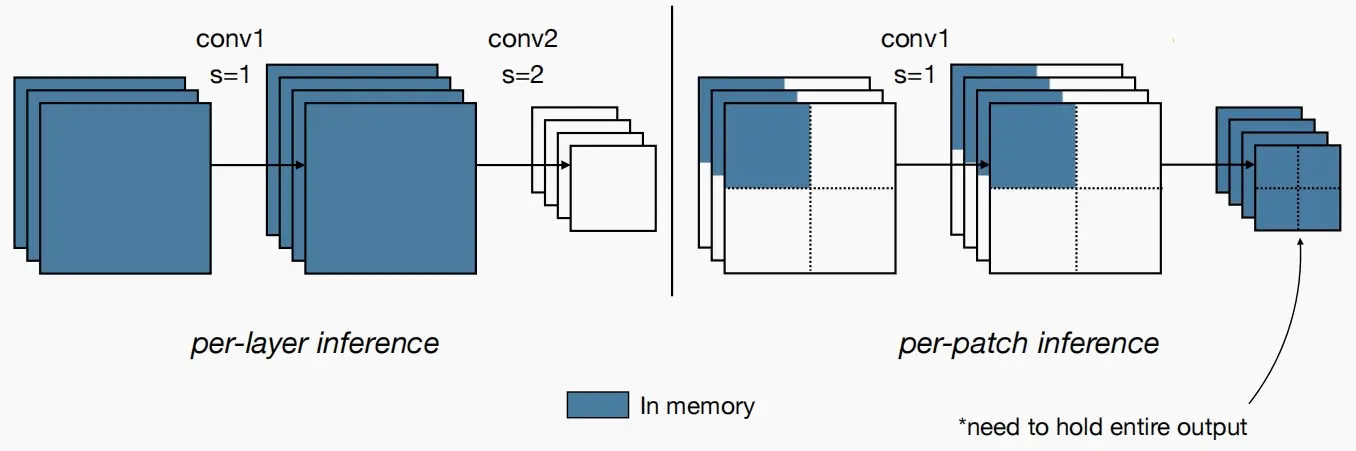
- Per-layer inference:原始的MobileNetV2中是逐层进行推理计算的,必须同时保留输入激活和输出激活,这两者都需要在内存中存储。
- Per-patch inference:MCUNetV2提出了基于Patch的推理方法,模型每次仅在小比例区域(比完整区域小10倍)进行计算,这可以有效降低峰值内存占用。当完成该部分后,网络的其他具有较小峰值内存的模块则采用常规的layer-by-layer 方式运行。例如图中示意,每次仅计算该特征图的四分之一。
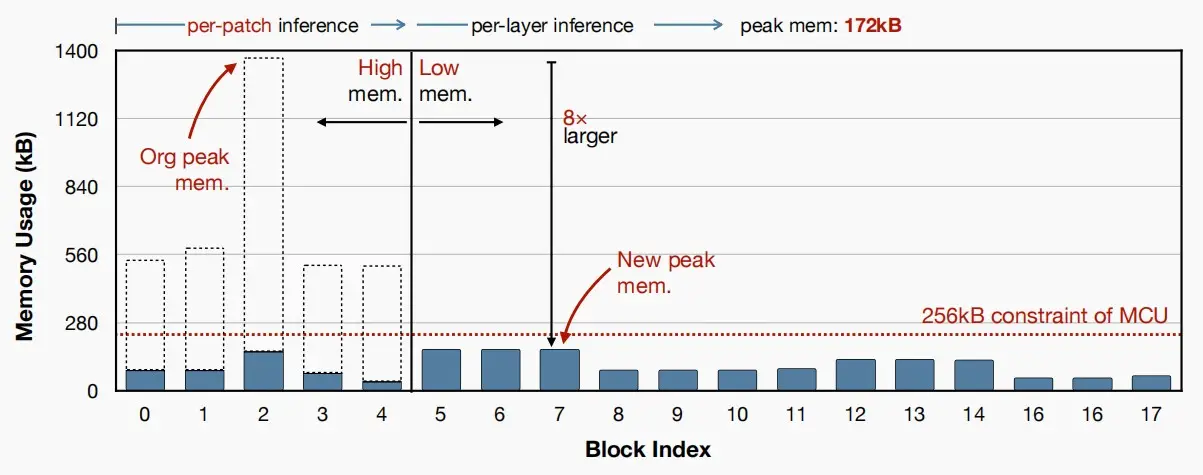
- 下图为采用Patch-base inference后,MobileNetV2各块的SRAM用量。可以看到改进后,满足256kB的限制。
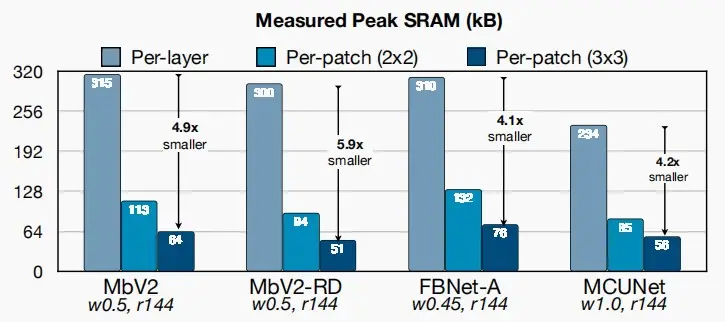
- 下图为采用2×2Patch和3×3Patch的效果对比图。可以看出后者对于SRAM需求的改进更为明显。
- 问题:随着接感受野receptive field的增加,空间重叠会变大,重复计算导致更大的计算开销
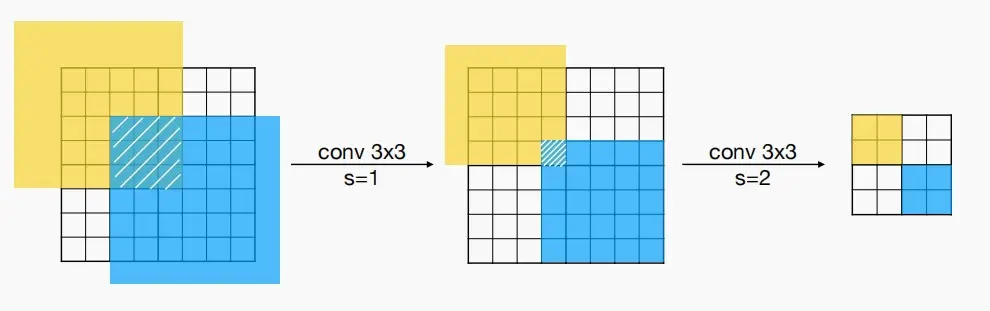
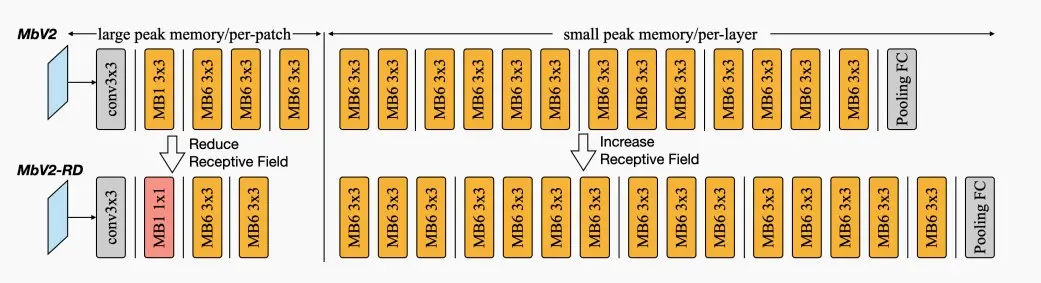
2. Network Redistribution to Reduce Overhead
- 上述重叠区域的将带来10%的额外计算开销,虽然相对于其提升微不足道,但是作者还是力求完美以消除额外的开销。
- Redistribution感受野:在进行Per-patch推理时,希望减小感受野,而在Per-layer推理时希望增大感受野。
- Per-patch阶段:移除了一个3×3卷积,并用一个1×1的卷积取而代之,减小感受野。
- Per-layer阶段:增加了一个3×3卷积
- 总体而言,总感受野不变,准确度不变,而重叠部分减小,额外计算开销降低。
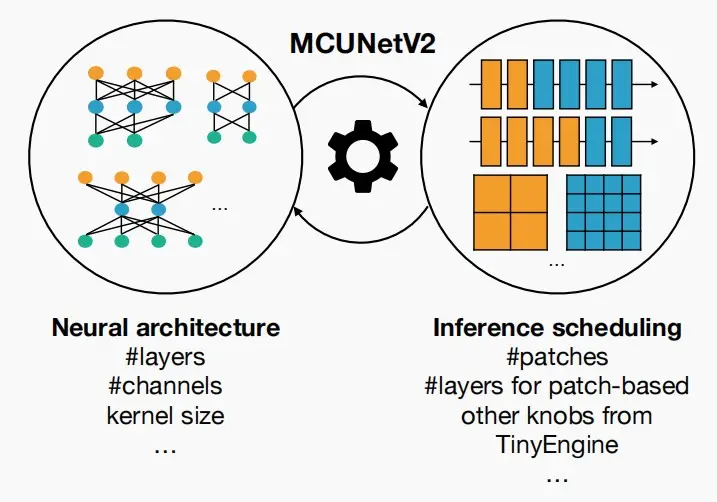
3. Joint Automated Search for Optimization
- 通过将神经架构搜索与推理调度结合,即可得到MCUNetV2。
- 对于神经架构搜索,我们有层数、通道数、卷积核大小等参数可供调整。
- 对于推理调度,我们有patches、基于patches推理层数以及TinyEngine的参数可供调整
- 在下一节进行讨论。
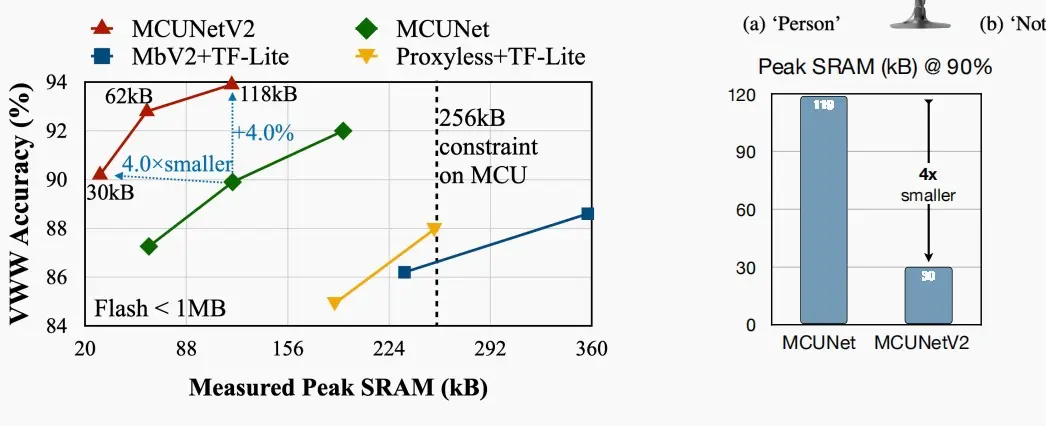
Performance
- 如下左图是基于Visual Wake Words数据的准确率与峰值内存对比图,右图是MCUNet和其V2的峰值内存对比图,接近4×的差距。
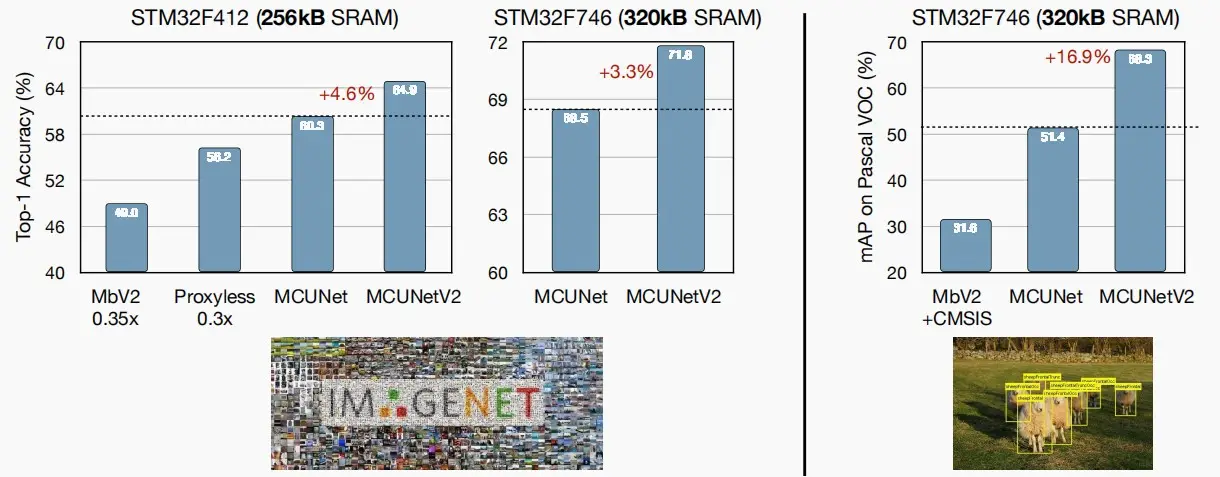
- 左图是ImageNet分类,右图Pascal VOC目标检测,都是在微处理器STM32上进行实验。
Dissecting(解剖) MCUNetV2 architecture
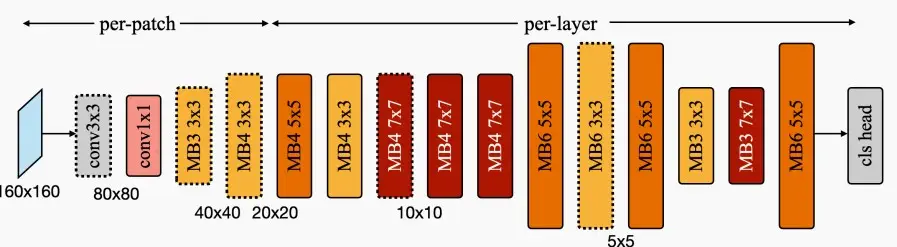
- 下图是MCUNetV2的架构示意图
- 从160×160的分辨率开始,实际上可以使用基于patch的推理来适应相当大的分辨率。
- 前期per-patch推理阶段,使用相对较小的核,以减小感受野和空间重叠。
- 中间阶段的扩展比率仍然较小,以降低峰值内存,因为此时分辨率仍然较高。
- 后期阶段采用更宽的神经网络,以提高性能。
- 对于VWW等对分辨率敏感的数据集,采用更大的输入分辨率,以便检测到更小的人和物体。
四、应用
- 第四章主要是介绍韩松老师实验室的一些实践成果,在微控制器上部署微型模型,并取得不错的效果。
Ⅰ、Tiny vision
Tiny Image Classification
- ImageNet-level image classification
- 通过MCUNet等技术,我们能够在微控制器上实现ImageNet级的图像分类性能。
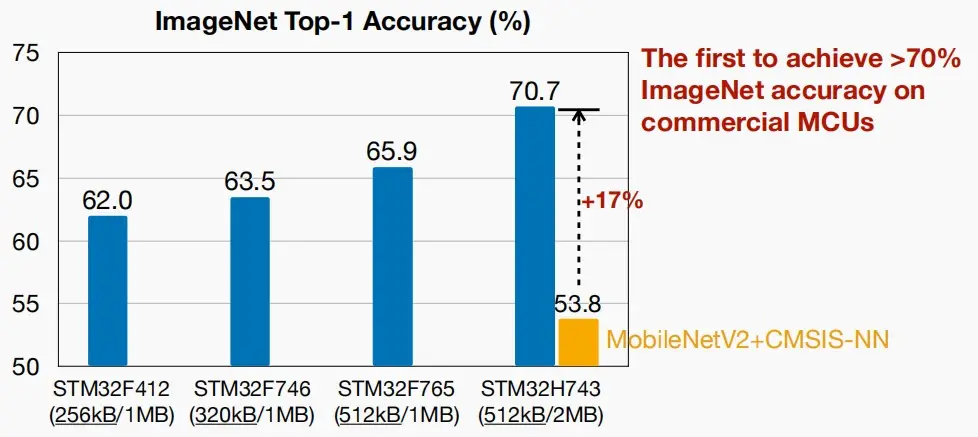
- 如下图,通过MCUNet技术,使得在相对较高规格的STM32H743微控制器上的准确率从53.8%提升至70.7%,这是第一个在商业MCU上实现>70%的ImageNet精度。
- 图中四种微控制器上的网络可以轻松得到,无需重新训练模型,可以使用Once-For-All网络,再为不同的内存约束采样不同的子网络。
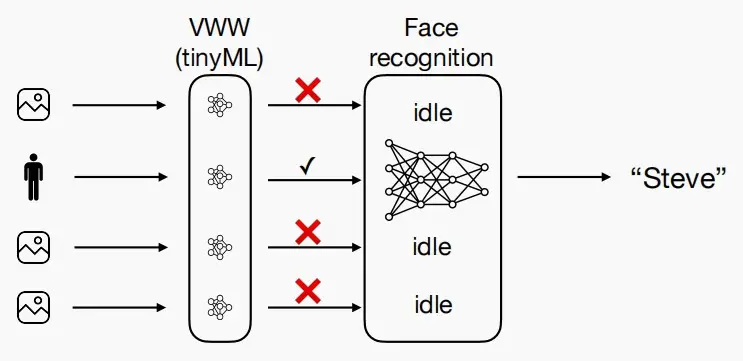
- visual wake words
- 只有当一个人站在摄像机前时,才能进行人脸识别,这样可以节省大量的能量。
Tiny Object Detection
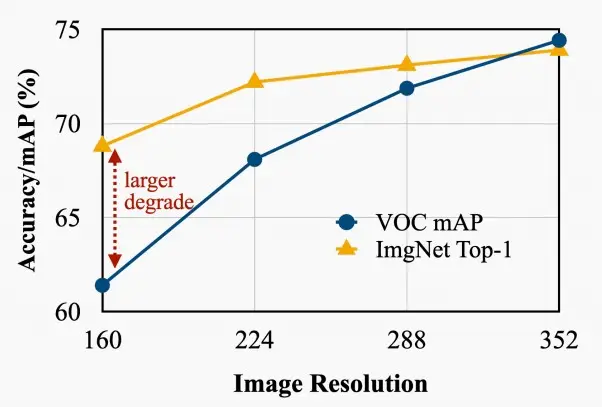
- 目标检测对输入分辨率更为敏感,因为我们需要做出更密集的预测。Patched-based推理可以通过打破内存瓶颈来适应更大的分辨率。
- 该图展示了平均精度与图像分辨率的关系。
Tiny On-device Training
- 不仅能够在微控制器上推理,还可以进行训练。
Ⅱ、Tiny audio
- 在我们的日常生活中的常见应用
- 音频关键词/关键字定位
- 语音识别
- 噪声消除
- 关键字定位
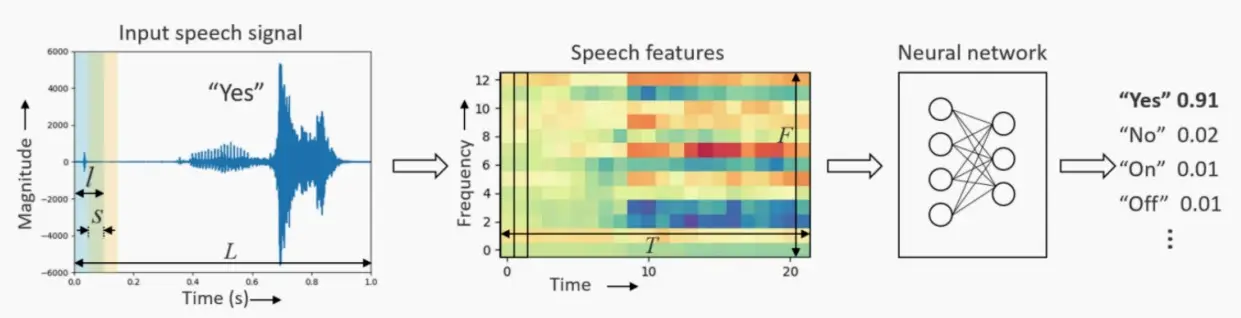
- 输入:一段长度为l、步长为s的重叠帧,总共T=(L-l)/s+1的帧。
- 人工设计的特征:将时域信号转换为一组频域光谱系数。
- 神经网络提取特征:生成输出类的概率,例如关键字是“是/否”“开/关”的概率。
Ⅲ、Tiny time series/anomaly detection
- 在微型设备上的异常检测应用
- 视频监控
- 医疗保健
- 反诈反骗,对抗攻击
- 用自动编码器(autoencoders)检测异常
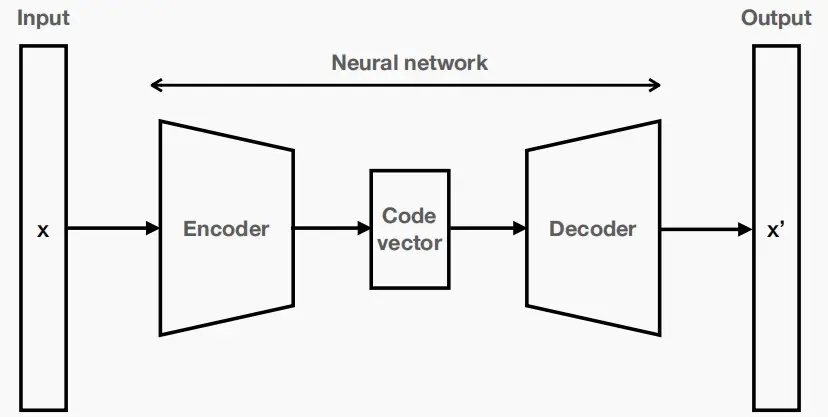
- 自动编码器定义:一种预测其输入的神经网络
- 编码器:将输入端压缩成一个较低维的代码向量(code vector)
- 代码向量(code vector):输入的抽象化
- 解码器:重建来自代码向量的输出
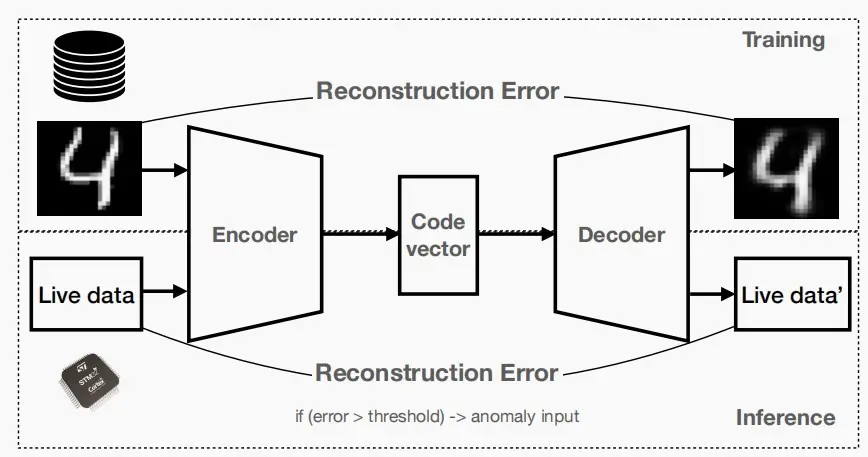
- 通过检查输入与输出之间的差异,可以判断当前场景正常还是异常
- 训练和推理
- 训练:最小化重建误差
- 推断:使用实时数据检测异常输入
- 自动编码器的属性
- 无监督学习:我们不需要培训时的标签。
- 特定数据:它们只能有意义地压缩类似于训练数据集的数据,即特定领域的数据,例如数字图像等。
- 损失性:输出将与输入不相同。
- 自动编码器定义:一种预测其输入的神经网络