- 论文 - 《MMBind: Unleashing the Potential of Distributed and Heterogeneous Data for Multimodal Learning in IoT》
- 代码 - Github
- 关键词 - SenSys25、系统、模态缺失、异构、多模态、物联网、训练
摘要
- 研究问题:现有的大多数多模态学习方法严重依赖大量同步、完整的多模态数据进行训练。然而,在实际的物联网(IoT)感知应用中,这种设定并不现实,因为数据通常由分布式的节点采集,具有异构的数据模态,且很少有标签。
- 本文方法 - MMBind
- 一种面向分布式、异构 IoT 数据的新型多模态数据绑定方法。
- MMBind 的核心思想是通过一个足够具有描述性的共享模态,将来自不同来源和模态不完整的数据进行绑定,从而构建用于模型训练的伪配对多模态数据集。
- 还提出了一种加权对比学习方法以应对不同来源数据之间的域偏移(domain shift),并结合一种可适应不同模态组合的多模态学习架构。
- 实验性能:在十个真实世界的多模态数据集上的实验评估表明,MMBind 在不同程度的数据缺失和域偏移情况下均优于当前最先进的基线方法,并有望推动物联网应用中多模态基础模型的训练发展。
1 引言
-
大多数现有的多模态学习方法需要使用大量完整的多模态数据进行训练,其中每个样本都包含所有传感器模态同时采集的数据,并配有相应的标签。
-
实际物联网感知应用中,上述多模态学习范式将遇到的问题 - 分布广泛且异构的数据形式:
- (1)这类数据通常是异构且不完整的:不同节点上的多模态数据差异很大,常常存在缺失的模态或标签。
- (2)由分布式节点收集的传感器数据通常是在不同的时间和地点采集的,因此数据彼此之间存在差异,但可能描述的是相似的事件。
-
跨模态生成
- 一种直接的方法,即从已有模态中生成缺失的模态数据,但由于配对传感器数据不足,训练一个稳健的生成模型在 IoT 应用中极具挑战性。
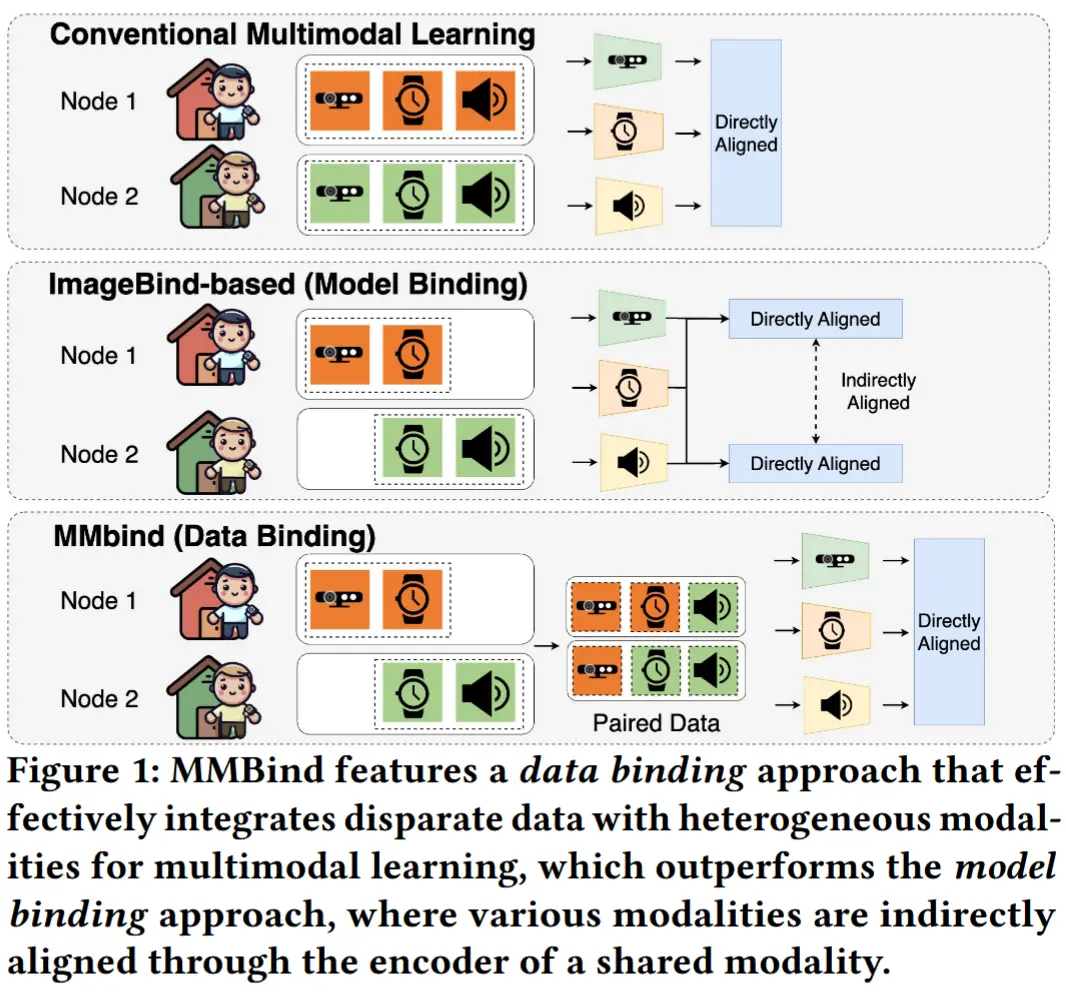
- 最近的一些方法,如 ImageBind [13] 及其他 [9, 56],旨在将不同模态对齐到某一中心模态的嵌入空间中,如图 1 所示。然而,这些模型绑定方法并未显式地关联不同节点之间的模态数据,且严重依赖于来自单一中心模态的大量数据。实验结果也表明,它们在数据有限且存在显著域偏移的 IoT 数据集上表现不佳。
- MMBind 框架
- MMBind 是首个通过利用分布式节点间的共享模态来构建伪配对多模态数据以供模型训练的数据绑定方法。
- 共享模态既可以是传感器数据,也可以是标签,两者都能有效描述事件之间的相似性。不需要同步采集完全相同事件的多模态数据,而是证明:即使是不同时间、不同地点采集的、观测相似事件的不同模态数据,也可以被有效地用于多模态训练。这使得 MMBind 能够从分布式 IoT 节点所采集的各种分散且不完整的小型数据集中构建一个多模态基础数据集。
- 具体而言,MMBind 采用了一种新颖的两阶段训练策略,用于将分布式和异构的 IoT 数据进行绑定:
- (1)通过共享模态对不完整数据进行配对。
- MMBind 收集所有包含共享模态的数据样本,用于预训练一个单模态编码器。当共享模态为标签时,也可以直接使用预训练的大语言模型(LLMs)。
- 随后,MMBind 利用共享模态的特征相似性,从具有不同域偏移的数据中匹配最相似的样本,从而构建出与相应相似度度量相关联的伪配对多模态数据。
- 此外,MMBind 还可以轻松扩展,通过连续的数据绑定整合多个不完整的数据集,即使这些数据集使用的共享模态各不相同。
- (2)使用异构配对数据进行加权对比学习。
- MMBind 采用加权多模态对比学习方法,在对比学习过程中根据数据对之间的相似性为样本分配不同的权重。这一设计是数据绑定方法所独有的,因为它考虑了伪配对样本的不同贡献。通过考虑到由于显著的域偏移导致伪配对样本质量参差不齐的情况,该方法增强了所学表示的鲁棒性。
- 此外,MMBind 集成了一种自适应多模态学习架构,能够利用异构模态组合的数据进行模型训练,同时结合伪配对数据和原始的不完整多模态数据。因此,MMBind 能够在来自分布式节点的大规模不完整数据上高效地训练多模态联合嵌入,仅需少量甚至无需自然配对的多模态数据即可完成训练。
- (1)通过共享模态对不完整数据进行配对。
2 相关工作
- 多模态感知系统
- 融合多个传感器数据的多模态感知系统,该领域的大多数研究都假设可以获取完整的、时间同步的多模态数据。
- 分布式感知与学习
- 由空间分布的传感节点组成的分布式传感器网络,其节点可能彼此靠近且具有重叠的视野范围,也可能部署在完全不同的环境中并观测不同的场景。在这样空间分布的数据上训练模型通常采用传感器融合算法 [6, 20, 24],以整合来自多个视角的信息。
- 尽管此前的一些多模态联邦学习研究 [34, 48] 支持在具有异构模型的节点上进行分布式模型训练,但它们的性能上限是集中式的单模态学习,且这种方法未能充分对齐不同模态。
- 缺失模态下的多模态学习
- 现有在不完整多模态数据下进行训练的策略。例如,[18, 25] 利用在单模态数据上预训练的单模态编码器来构建多模态模型,而 [3, 46] 则尝试从已有模态生成缺失的模态数据。
- 然而,由于高质量多模态配对数据的稀缺,这些方法在 IoT 应用中往往难以有效学习跨模态信息。
- 模型绑定方法
- 近期的一些工作,如 ImageBind [13] 和 LanguageBind [56],通过对比学习将不同模态对齐到某一中心模态的嵌入空间中。[10] 在此基础上进行了扩展,采用顺序训练两个模态的方式,而非依赖于一个中心模态。所有这些方法都属于“模型绑定”方式,即各种模态通过传递性间接对齐,模型仅接触 (Central, X) 类型的模态对。
- 相比之下,MMBind 提出了首个“数据绑定”方法,基于共享模态显式合成 (Central, X, Y) 类型的数据对,从而实现多个模态之间的直接多模态学习。
- 此外,MMBind 仅利用共享模态编码器进行数据配对,而 ImageBind 则依赖该编码器完成所有模态在嵌入空间中的对齐,因此更容易受到共享模态数据不足的影响。
3 动机研究
在本节中,我们评估在配对数据有限的情况下多模态学习的性能,并探索利用分散且不完整数据的潜力。这里,“配对数据”(paired data)指的是具有完整模态的数据,而“配对”(pairing)描述的是将多个独立的数据样本组合成一个包含完整模态的数据样本的过程。
3.1 有限配对数据的影响
在现实场景中,获取具有完整模态并带有标签的多模态数据通常是不现实的。
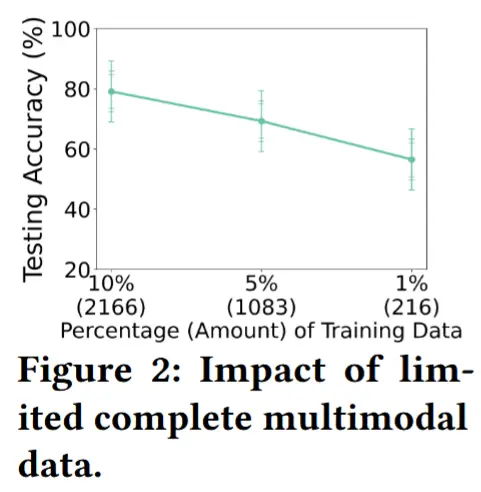
作者通过实验来研究不同数量的带标签配对数据下,监督多模态学习的性能表现。使用RealWorld 数据集,将数据集划分为训练集和测试集:训练集分别包含 10%、5% 和 1% 的带标签数据,测试集则保留 90%,同时保持类别平衡。使用一个简单的深度学习模型(5层CNN、2个门控循环单元层和一层全连接)。结果如图2所示,在仅使用 1% 的训练数据(即 216 个样本)时,准确率只有 55.74%。表明多模态学习高度依赖于足够数量的完整模态数据。
3.2 绑定不完整数据的潜力
为了克服配对多模态数据有限的问题,作者探索利用分散且不完整的多模态数据。
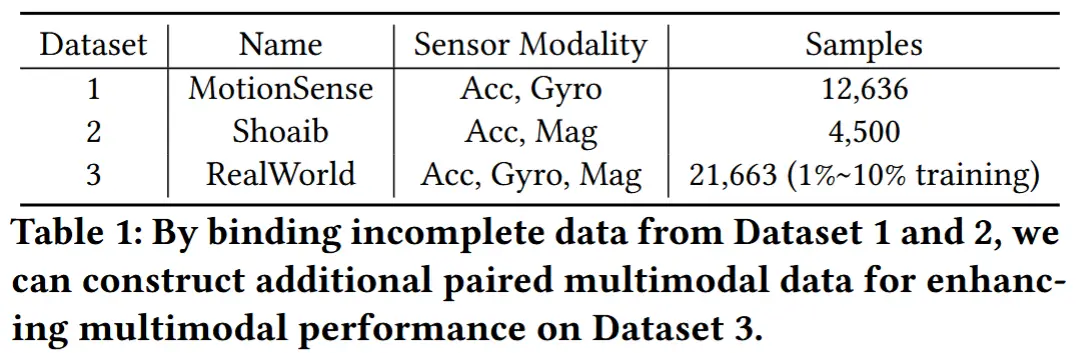
如表1所示,三个数据集各自有着不同的模态,但是相同的五种活动类别。作者利用MotionSense 数据集的(加速度计 Acc,陀螺仪 Gyro)数据和Shoaib 数据集的(Acc,磁力计 Mag)数据,进行随机选择相同活动的样本,提取出缺失的那个模态数据,形成一个新的配对样本。再利用构建出的17136个新的伪配对样本训练一个多模态模型,并在训练完成后,使用 RealWorld 数据集中少量带标签的完整模态数据进行微调。图 3 显示,在完整多模态数据有限的情况下,引入 MotionSense 和 Shoaib 的伪配对数据能够显著提升性能。
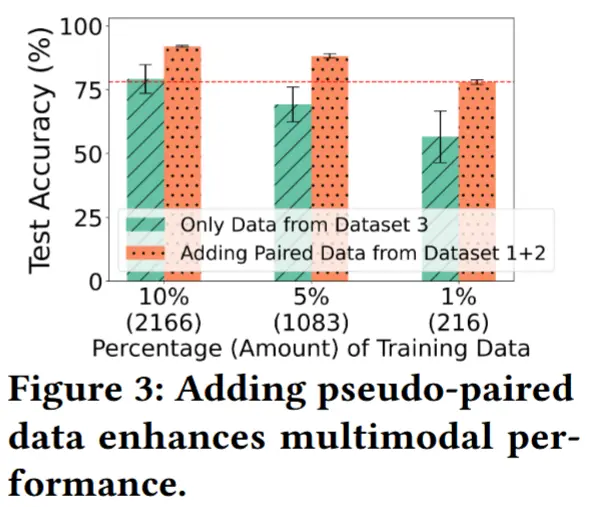
这一案例研究揭示了两个关键见解:
- 绑定不同来源的不完整数据集对于多模态训练是有效的。
- 绑定过程的有效性依赖于数据集之间共享的信息。
4 系统概述
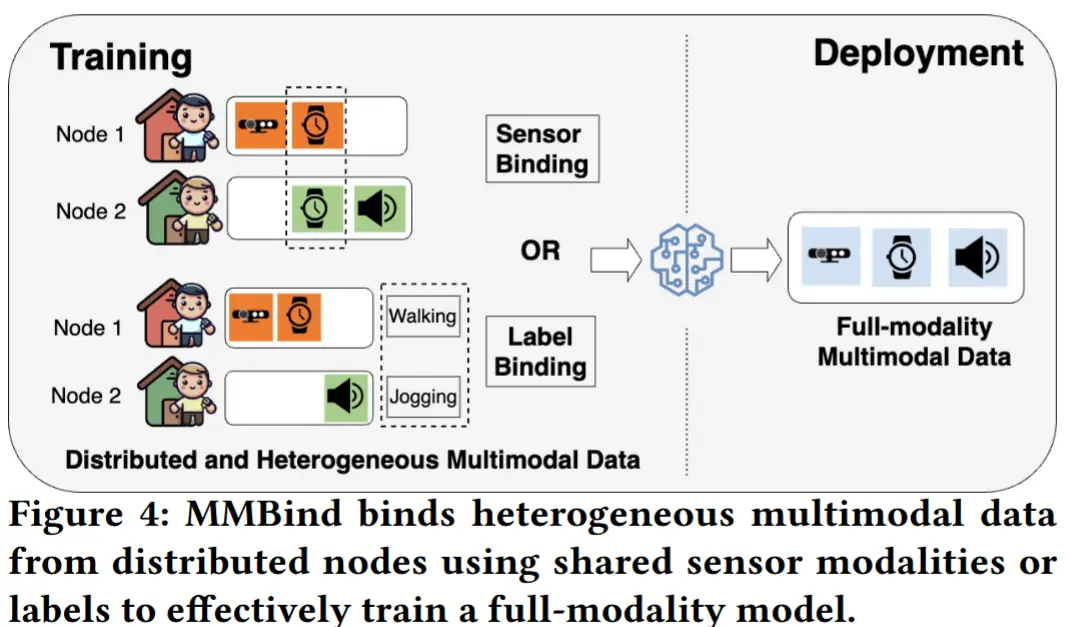
现在介绍 MMBind —— 一种面向分布式和异构 IoT 数据的新型多模态学习框架。其核心思想是通过绑定来自不同来源的数据,构建伪配对的多模态数据,用于模型训练。
4.1 应用场景与挑战
两种典型的应用场景:
- 不同节点上的多模态数据通常具有显著的异构性,表现为模态或标签的缺失。如图4所示,对于传感器模态缺失,可以利用标签进行伪配对。对于标签缺失,可以用共享的传感器模态进行伪配对。
- 将多模态神经网络适配到新增的感知设备也是一项挑战,即对于一个采集好的数据集,新增一个传感器模态,此时MMBind可以利用共享模态配对,有效利用已有数据,减少重新采集的工作量。
挑战:
- 利用异构数据生成数据对 :如何从不完整的数据样本中生成有效的完整模态数据。首先,物联网应用中的传感器数据通常具有高度异构性,其维度和数据模式各不相同。其次,当存在多个重叠模态时,如何选择最优的共享模态对于提升数据配对的有效性至关重要。
- 应对域偏移 :如何处理来自不同且不完整数据源之间不同程度的域差异。这种差异增加了准确量化样本相似性的难度,也使数据配对过程变得更加复杂。
4.2 问题建模
假设有两个由不同节点A和B采集的不完整多模态数据集,即 D_A 、 D_B 。数据集中的样本最多包含 M 种不同的模态( M \geq 2 )。
其中, X_k = \{\mathbf{m}_i \mid \mathbf{m}_i \in \mathcal{M}_k\} 包含了 |\mathcal{M}_k| 种不同的模态,其中 \mathbf{m}_i 表示传感器数据或数据标签。 \mathcal{M}_k \subseteq \{m_1, m_2, \dots, m_M\} 表示节点 k 中的有效数据模态。
D_A 和 D_B 为两个异构数据集,其具有以下特性:(1) 在不同的时间和地点由不同的节点采集;(2) 它们的样本在模态上是不完整的;(3) D_A 和 D_B 的样本共享某些共同的模态 {\mathbf{m}_\text{s}} ,可以是传感器数据或类别标签,用来描述分布式节点捕获事件的相似性。
MMBind 被设计用于利用来自异构数据集的不完整多模态样本,以提升对完整模态数据的多模态性能。这种方法称为数据绑定(Data Binding),其中显式地创建包含所有 M 种模态的完整样本 {\mathbf{m}_1, \mathbf{m}_2, \mathbf{m}_\text{s}} ,以联合训练各个模态的编码器 f_{\text{enc}_{m_1}}, f_{\text{enc}_{m_2}}, f_{\text{enc}_{m_\text{s}}} 。相比之下,先前的模型绑定(Model Binding) 方法,如 ImageBind [13],是基于原始的不完整数据样本,将不同模态的编码器对齐到共享模态编码器 f_{\text{enc}_{m_\text{s}}} 的输出嵌入空间中。
4.3 系统架构
MMBind 设计灵感:即使是在不同时间与地点采集的、来自不同模态的分布式数据,只要它们描述的是相似的事件,就可以用于增强多模态训练。
MMBind 核心思想:基于共享模态对不完整的多模态数据进行绑定,并构建伪配对的多模态样本,以学习多模态联合嵌入表示。图 5 展示了 MMBind 的整体系统架构。
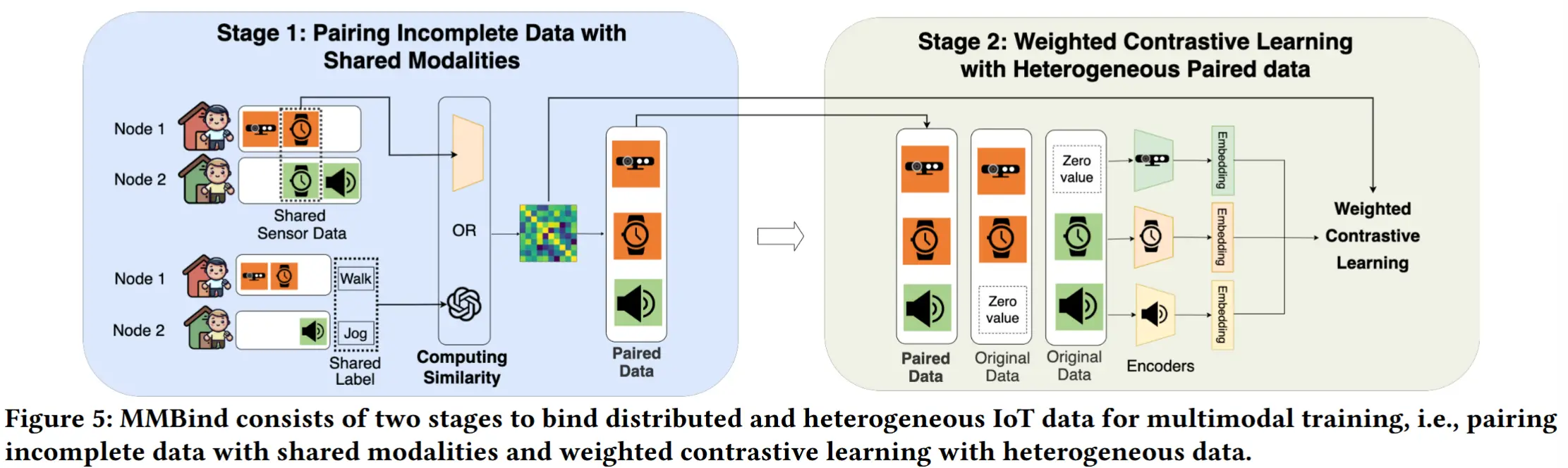
具体而言,MMBind 采用一种新颖的两阶段训练策略:
- 通过共享模态对不完整数据进行配对
- 在异构配对数据上进行加权对比学习
在第一阶段,MMBind 收集所有包含共享模态的数据样本,并训练对应的单模态编码器。随后,MMBind 利用共享模态的特征相似性,在不同不完整数据集中匹配最相似的样本,从而构建出伪配对的多模态样本。最终,每个伪配对样本都会关联一个相应的相似度度量值。
在第二阶段,MMBind 采用了一种自适应的多模态学习架构,能够处理具有异构模态组合的数据。该架构通过使用“dummy inputs”来表示缺失的模态,使得无论是伪配对样本还是原始的不完整多模态数据,都可以参与训练过程。此外,为了应对由于域偏移而导致的不完美配对问题,MMBind 在伪配对的多模态数据上引入了加权对比学习机制。该机制根据数据对之间的相似性,在对比学习过程中为样本分配不同的权重。
5 MMBIND 的设计
5.1 基于共享模态配对不完整数据
在第一阶段,MMBind 的目标是基于共享模态的相似性,将具有不同模态的分布式数据进行配对。
5.1.1 共享模态编码器训练
为了提高数据配对的有效性和可扩展性,我们的核心思想是测量共享模态数据的特征嵌入相似性,而不是直接比较高维原始传感器数据。因此,我们通过重构训练一个单模态特征编码器,将共享模态数据压缩到潜在空间中。这种潜在空间比原始数据分布更具结构化,语义上相似的样本被紧密地分组在一起,而语义不相似的样本则被放置得更远。
如图 6 所示,MMBind 首先将共享模态的所有数据(即 D_A 和 D_B 中的 \mathbf{m}_\text{s} )合并起来,训练一个单模态编码器 f_{\text{enc}_\text{s}}(\cdot) 。具体来说,以自监督的方式使用 autoencoder 来训练单模态编码器。该自动编码器由一个编码器 f_{\text{enc}_\text{s}}(\cdot) 组成,它将数据压缩到一个较小的潜在空间中,随后是一个解码器 f_{\text{dec}_\text{s}}(\cdot) ,用于从潜在嵌入中重构原始输入数据。重构损失定义为解码器输出与原始输入数据之间的 L2 距离。假设重构后的数据为 \mathbf{m}'_\text{s} = f_{\text{dec}_\text{s}}(f_{\text{enc}_\text{s}}(\mathbf{m}_\text{s})) ,则重构损失表示为:
通过训练过程,编码器学会将输入数据中语义上重要的特征压缩到一个较小的潜在空间中,同时有效过滤掉无关特征。
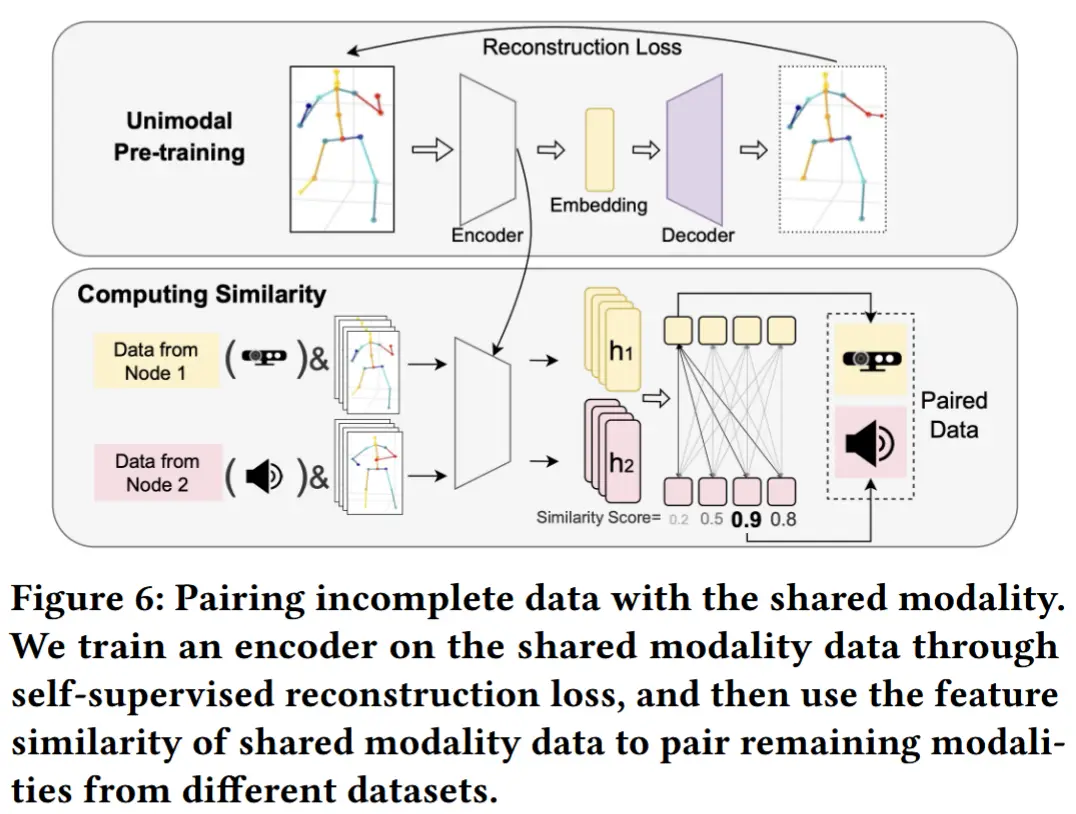
同样,当标签作为共享模态时,我们可以直接利用预训练的大语言模型(LLMs)来衡量自然语言标签的语义相似性,从而避免训练单模态编码器的需求。在本文中,我们主要关注标签能够充分描述数据相似性的场景。然而,类别标签有时无法完全捕捉事件的相似性,导致数据关联不一致。在这种情况下,我们可以通过在结构化格式中添加额外的元数据(如受试者的性别、环境和使用的设备)来增强标签。然后,LLM 根据标签的语言 tokens 识别出语义上最相似的样本,并计算它们的相应相似度。
5.1.2 生成伪配对数据
在单模态预训练之后,共享模态的编码器作为衡量数据集 D_A 和 D_B 之间相似性的基准。MMBind 然后利用共享模态的特征相似性来配对这些数据集。具体来说,将 D_A 和 D_B 中共享模态的数据样本输入到共享模态 \mathbf{m}_s 的特征编码器中。我们有:
接下来,计算来自 D_A 和 D_B 的共享模态特征 \mathbf{h}_s^j 和 \mathbf{h}_s^k 之间的成对余弦相似性,得到一个相似度矩阵 \mathbf{A} \in \mathbb{R}^{|D_A| \times |D_B|} 。使用成对余弦相似性作为配对度量,因为这是深度学习模型中衡量特征表示相似性的常见方法。
然后,MMBind 通过匹配不同数据集之间最相似的样本来构建伪配对多模态样本。例如,对于 D_A 中的第 j 个数据样本,记为 X_A^j = (\mathbf{m}_1^j, \mathbf{m}_s^j) ,我们在 D_B 中搜索具有最高共享模态 \mathbf{m}_s 特征相似性的样本,即:
这里, \arg\max 表示在 a_j 中达到最大值的索引。因此,从 D_B 中对应的配对样本将是 X_B^{p_j} = (\mathbf{m}_2^{p_j}, \mathbf{m}_s^{p_j}) 。此外,每个伪配对多模态样本也将与相应的相似度度量 a_{jp_j} 关联。这一过程适用于 D_A 中的每个第 j 个数据样本和 D_B 中的每个第 k 个数据样本:
随着对两个数据集中的每个样本重复配对过程,合并后的伪配对数据集 D_P 将总共包含 |D_A| + |D_B| 个数据样本,即:
当配对大规模数据集或共享模态的特征嵌入维度较高时,通过遍历每对样本的余弦相似性来进行配对可能会非常耗时。为了解决这个问题,我们可以探索基于组的配对方法或者主成分分析(PCA)等技术,进一步加速数据配对过程。
5.1.3 配对考虑事项
在执行数据配对之前,还需考虑一些关键因素。
绑定模态的选择
伪配对数据集的质量在很大程度上取决于共享模态的特征是否能够准确衡量不同样本之间的语义相似性。因此,MMBind 的性能高度依赖于所选择的共享模态。当不同的数据集 D_A 和 D_B 拥有多个重叠模态时,仔细选择用于数据绑定的共享模态 m_s 显得尤为关键。
在此,我们总结了适用于 MMBind 数据配对的理想共享模态应具备的两个主要特性:
- 共享模态本身应能有效区分下游任务中的不同事件。
- 共享模态应在不同域之间具有良好的泛化能力。
绑定超过两个数据集
上述方法可以轻松扩展,通过连续的数据绑定整合多个不完整的数据集。当存在多个数据集时,不同数据集之间并不需要采用相同的共享模态。
然而,尽管引入伪配对数据通常比完全不进行配对能提升性能,但性能提升并不总是与配对样本数量成正相关。在整合多个数据集时,必须考虑它们之间的异构性。例如,由于传感器位置等差异,配对后的数据集之间可能存在显著的数据分布差异。
5.2 基于异构配对数据的加权对比学习
在第二阶段,我们的目标是利用伪配对数据和原始不完整数据来训练特征编码器,以学习多模态联合表示。
5.2.1 异构模态组合的自适应多模态学习
MMBind 采用了一种能够处理异构模态组合的自适应多模态学习架构。MMBind 同时利用伪配对的多模态样本和原始的不完整多模态样本进行模型训练。聚合后的训练数据集包含以下模态组合的样本:(\mathbf{m}_1, \mathbf{m}_s)、(\mathbf{m}_s, \mathbf{m}_2) 和 (\mathbf{m}_1, \mathbf{m}_2, \mathbf{m}_s)。对于缺失模态的样本,我们将使用零值占位符(dummy representation),使得我们的训练数据集为:
其中 \tilde{X}_A = (\mathbf{m}_1, 0, \mathbf{m}_s)、\tilde{X}_B = (0, \mathbf{m}_2, \mathbf{m}_s)、\tilde{X}_P = (\mathbf{m}_1, \mathbf{m}_2, \mathbf{m}_s)。
这种多模态学习架构的优势如下:
- 充分利用原始不完整样本和伪配对样本。
- 通过增加训练数据中模态组合的多样性,使全模态多模态模型更具鲁棒性。
5.2.2 基于配对相似性的加权对比学习
在同时利用伪配对数据和原始不完整数据的基础上,我们的目标是训练不同模态的特征编码器,确保它们的输出嵌入在统一的特征空间中对齐。此外,还需要特别考虑在第一阶段数据配对过程中生成的伪配对样本之间存在的不同程度的相似性。
为了实现这一目标,对不同模态的单模态特征进行对比学习。如图 7 所示,这将使同一多模态样本中的单模态特征在特征空间中更加靠近,同时将来自不同样本的单模态特征分开。为了适应不同编码器输出嵌入的不同维度,我们使用多层感知机MLP将特征映射到相同的维度。经过归一化处理以确保它们位于单位超平面后,我们得到嵌入 \mathbf{z}_q \in \mathbb{R}^F ,其中 q = 1, \dots, M ,并且在我们的实验中 F = 128 。
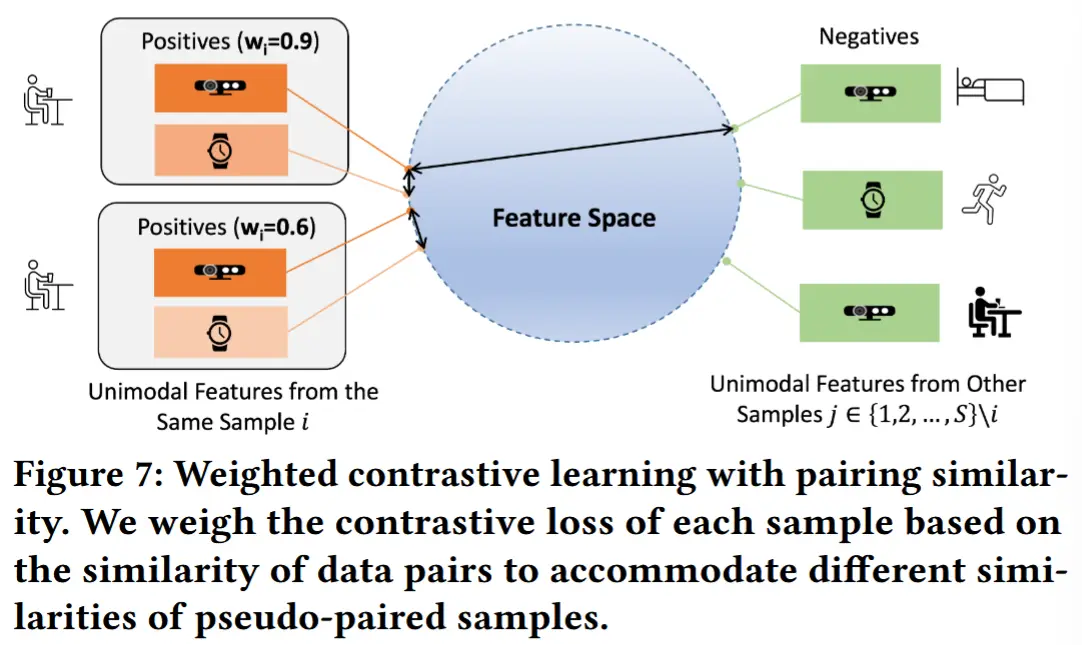
此外,为了有效应对伪配对样本之间的多样性相似性,MMBind 在伪配对多模态数据上执行加权对比学习。在之前的对比学习方法中,正样本来源于自然配对的多模态样本,对应于同一事件。然而,MMBind 的数据配对依赖于共享模态的特征相似性,这可能导致次优的配对结果,尤其是在异构数据集之间存在显著域差异的情况下。
为了解决这一挑战,我们提出将正样本对之间的相似度程度纳入对比学习中。具体来说,我们引入权重来根据数据对的相似性调整每个样本的对比学习损失,从而适应不同伪配对样本的贡献差异。加权多模态对比学习的损失函数为:
其中, (\mathbf{z}_q^i, \mathbf{z}_p^i) 表示来自同一配对样本 \mathbf{X}^i 的模态 p 和 q 的正样本,而 (\mathbf{z}_q^i, \mathbf{z}_p^j) 表示来自不同样本 \mathbf{X}^i 和 \mathbf{X}^j 的负样本。此外, w_i 表示分配给第 i 个配对数据样本 \mathbf{X}^i = (\mathbf{m}_1^i, ..., \mathbf{m}_M^i) 的权重,其值等于归一化的配对相似度 a_i 。 \mathcal{S} 表示聚合数据集 D_S 中数据样本的索引集合。因此,通过加权多模态对比学习,模型被训练为学习多模态联合嵌入,同时强调相似性较高的数据样本。这种方法有助于减轻误配对样本的影响,提升整体模型性能。