- 论文 - 《LLAVIDAL : A Large LAnguage VIsion Model for Daily Activities of Living》
- 代码 - Github
- 关键词 - 日常生活活动ADL、任务交互HOI、多模态、预训练、骨骼
1 引言
-
研究问题:当前大型语言视觉模型在日常生活活动(Activities of Daily Living, ADL )所需的任务上仍存在显著局限性。具体而言,它们在捕捉细粒度动作细节 、复杂的人物交互 (Human-Object Interactions, HOI )以及实现视角不变的动作表示学习方面表现不佳。
-
ADL任务挑战:多视角、细粒度动作与微小运动变化、复杂的任务交互、长时间序列依赖关系。
-
ADL视频与普通视频的差异
- 缺乏严格的时间结构 :一个视频序列中可能同时发生多种行为;
- 行为的非线性展开 :例如一个人在做饭时可能会穿插打电话或喝水等无关动作,从而打断“做饭”这一复合行为的线性流程;
- 视觉动态复杂 :由于场景自然、无剧本,这类视频对现有基于网络视频训练的 LLVM 构成理解难题;
- 缺乏关键模态线索 :不同于专门设计用于理解 ADL 的视频架构,当前 LLVM 缺乏对 3D 骨骼信息或人物交互(HOI)的显式建模,而这些线索对于捕捉细粒度动作细节、构建视角不变的表示至关重要。
-
当前ADL理解上的局限性
- 缺乏针对真实室内环境中采集的多视角 ADL 数据集进行指令微调;
- 模型结构过于简单,仅采用整体性操作,难以捕捉复杂的人类行为模式。
-
本文解决办法
-
半自动化 ADL 视频指令微调数据构建框架
- 作者使用AI进行标注,并且引入新的策略:关注人类行为的局部空间区域、在训练分布中融合时间非结构化特性、利用若监督机制减少幻觉现象。
- 通过该框架,作者构建了ADL-X新数据集,包含视频-指令对、3D骨骼数据、自然语言描述文本。
-
提出首个面向ADL的LLVM模型 - LLAVIDAL
- LLAVIDAL 将同步的多模态输入(包括视频、3D 骨骼、人物交互 HOI)融合到 LLM 的嵌入空间中。
- 为了有效整合多模态信息,作者提出了一种多模态渐进式训练策略MMPro,分阶段将各模态逐步引入训练过程。
-
建立了两个新的基准测试
- ADL 多选题测试 (ADL MCQ):用于评估模型对 ADL 动作逻辑推理能力
- ADL 视频描述生成任务 :用于衡量模型对复杂行为的理解与表达能力。
-
2 背景:训练 LLVM
在本节中,将简要介绍训练 LLVM 的通用框架。给定一个输入视频 V_i \in \mathbb{R}^{T \times H \times W \times C} ,使用预训练的 CLIP-L/14 对每一帧进行编码,得到帧级嵌入 f_i \in \mathbb{R}^{T \times h \times w \times D_v} ,其中 D_v 是嵌入维度, h = H/p 和 w = W/p 是根据补丁大小 p 调整后的维度。通过沿各自维度聚合这些嵌入,提取时间特征和空间特征。最终得到的视频级特征 \mathcal{X}_i^v \in \mathbb{R}^{F_v \times D_v} ,其中 F_v 表示时空令牌的数量,是通过拼接聚合后的特征得到的。
这些视频特征被映射到 LLM 的嵌入空间中,使用参数化模块 \mathcal{T}_v 将视觉令牌映射为 Q_v \in \mathbb{R}^{F_v \times K} 。类似地,文本查询被标记化为 Q_t \in \mathbb{R}^{F_t \times K} ,表示来自训练数据的指令查询。LLM 的输入随后按以下方式组合:[USER: \langle Q_t \rangle \langle Q_v \rangle Assistant:]。LLVM 的优化是在因果语言建模目标下进行的:\min_{\theta} L_{CE}(\text{LLM}(\mathcal{T}_v(\mathcal{X}_i^v)), y_i),其中 L_{CE} 表示交叉熵损失, \theta 是 \mathcal{T}_v 的参数, y_i 是目标序列,而 \text{LLM}(\mathcal{T}_v(\mathcal{X}_i^v)) 是 LLM 的预测。
3 ADL 视频-指令对(ADL-X)
ADL-X的视频数据来源于 NTU 数据集[41]的ADL视频记录,并系统性地生成了针对ADL各个方面的问答对。ADL-X 的半自动化数据整理过程采用了三种创新技术,如图2所示。
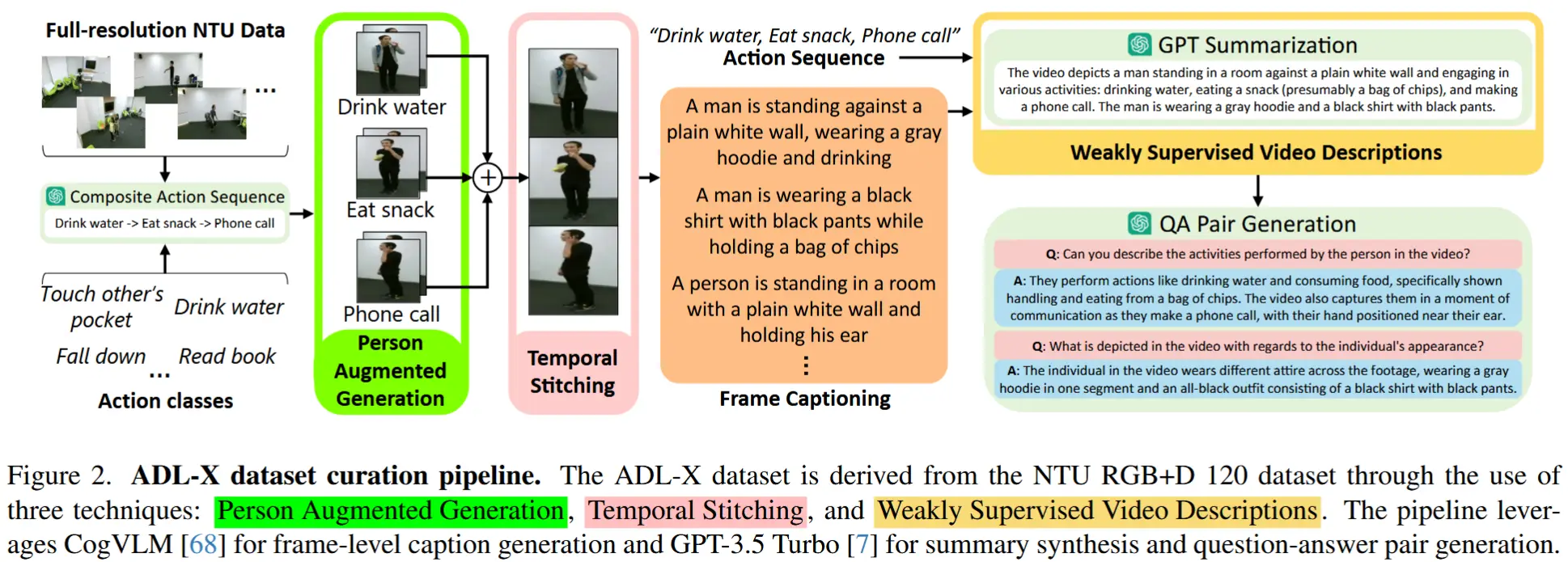
- 人物增强生成PAG
- 动机:ADL 任务需要在空间上关注个体的姿态及其与物体的交互。
- 实现:作者利用骨骼数据裁剪出围绕个体的边界框。
- 结果:减少了视频帧中的背景信息,有效降低了 LLM 在视频描述中生成无关内容的可能性,从而专注于人类动作。
- 时间拼接
- 动机:真实世界的 ADL 视频通常缺乏时间结构。
- 实现:为了模拟 ADL 的内在随机性,通过拼接较短的片段来构建较长的未修剪视频序列。最初,作者使用 GPT 提示生成了 160 个复合动作序列,从 NTU 数据集的 120 个动作(A1, A2, ..., A120)中组合而成。接着从 NTU 数据集中提取对应的短片段进行拼接,确保同一序列中所有片段都属于同一个人。
- 结果:这一过程共生成了 16,206 个拼接视频,每个视频最多包含 7 个动作。
- 弱监督 ( WS ) 视频描述
- 初步设想:首先,以每秒 0.5 帧的速率使用 CogVLM [68] 为视频中的每一帧生成图像字幕;其次,通过一次 LLM 调用将这些帧级字幕合成到一个连贯的视频描述中。
- 引起问题:此步骤容易引入幻觉内容,可能降低数据集的质量。
- 解决:采用弱监督方法,将从短片段中获得的动作序列输入 GPT-3.5 Turbo 模型,引导其生成结构化、连贯的描述。
- 生成 QA 对
- 实现:将上述描述输入 GPT-3.5 ,针对各种与ADL 相关的类别生成问题。这些类别包括:视频摘要、执行的动作、空间细节、人-物交互、其他视频特定问题。
- 结果:整理了一个包含 100K 视频指令对的数据集,命名为 ADL-X 。
4 ADL-X 的多模态
动机:引入额外的模态信息 M_m(如 3D 骨骼数据 M_s 和 人-物交互信息 M_o)对于提升对 ADL 的理解具有重要意义。(因为 ADL 主要涉及人体关键部位或关节的运动,这些模态有助于学习 view-invariant representations 和理解它们在动作中所经历的轨迹)
如何整合进LLVM中LLM输入空间?作者设计的策略如图3所示,包括:
- 使用专门的模态-语言编码器提取特征;
- 在 QA 对中加入模态特定信息以增强语义表达;
- 利用模态特定语言描述对 LLM 输入进行上下文化处理。

4.1 M_m 作为特征
为了将新模态数据整合到 LLVM 的输入中,将模态特定数据从 M_m 映射到 \mathcal{X}_i^m ,并与视觉特征 \mathcal{X}_i^v 结合。至关重要的是,从骨骼数据和人-物交互(HOI)中提取的特征 \mathcal{X}_i^m 必须与语言域对齐,以便于它们与 LLM 嵌入的集成。
骨骼特征
使用一个骨骼-语言模型 SkeletonCLIP [63] 从骨骼数据 M_s 中提取特征并将其作为输入提供给 LLVM。SkeletonCLIP 是一个双编码器框架,结合了骨骼主干网络和冻结的 CLIP 文本编码器。
骨骼主干网络在 NTU 片段上预训练,并通过交叉熵监督来微调(实现骨骼-语言对齐)。最终提取的骨骼特征表示为 \mathcal{X}_i^s \in \mathbb{R}^{F_s \times D_s} ,其中 D_s 表示骨骼特征的维度。这些特征被用作 LLVM 的输入令牌。
人-物交互特征
提取人-物交互特征的过程分为两个步骤,这两个步骤均利用现成的模型,无需额外训练即可有效完成任务。如下:
- 动作条件下的目标检测
给定一个由一系列修剪后的视频片段组成的拼接 ADL 视频(记为 \text{clip}_j ),首先从每个片段中均匀采样 8 帧,并使用预训练的 BLIP-2 模型生成这些帧中观察到的不同物体列表。然后,结合真实动作标签和 GPT-3.5 识别与给定动作最相关的对象。
- 对象定位和跟踪
第二步中,对第一步识别出的目标进行空间定位和时间演化(跟踪)。
空间定位: 使用一个预训练的开放词汇目标定位模型 ObjectLM。输入目标列表和视频,对于每个采样的帧,ObjectLM 检测目标的边界框,并从这些边界框内的图像区域提取目标特征。第 t 帧中 n 个目标的特征表示为 \mathcal{X}_o^t \in \mathbb{R}^{n \times D_o} ,其中 D_o 表示维度。
帧间追踪/时间演化: 对于第 t 帧中的每个目标,计算其特征向量 \mathcal{X}_o^t 与第 t+1 帧中同一类别所有特征向量之间的余弦相似度。然后,将第 t 帧中的目标与第 t+1 帧中具有最高相似度得分的目标关联起来。这一匹配过程对每帧中的所有目标重复进行,从而在整个采样帧序列中为每个相关目标建立轨迹。因此,对于在 8 帧中检测到的 n 个相关目标,目标特征被组织成以下模板: [\langle \mathcal{X}_o \rangle = \langle \mathcal{X}_o^1 \rangle \, \langle \mathcal{X}_o^2 \rangle \, \dots \, \langle \mathcal{X}_o^n \rangle] ,其中 \mathcal{X}_o^j \in \mathbb{R}^{8 \times D_o} 表示视频中每个被追踪的相关目标的特征,即 HOI 特征。
4.2 M_m 作为 QA 对
3D 骨骼关节坐标或相关目标轨迹坐标连同相关的动作序列一起输入到 GPT-3.5 Turbo 中,生成 ADL-X 视频中骨骼运动或人-物交互(HOI)的一般描述。然后,将该描述重新输入到 GPT-3.5 Turbo 中,生成两个 QA 对,以提供骨骼和目标运动的详细解释。这些 QA 对随后被添加到文本查询集 Q_t 中,用于微调 LLVM 的指令。
4.3 M_m 作为上下文信息
为了整合人体骨骼或人-物交互的上下文信息,在训练 LLVM 时,将模态特定的信息附加到输入文本查询 Q_t 中。
- 对于骨骼模态 M_s ,首先识别出五个关键的关节,因为它们对运动有显著贡献。
- 对于目标模态 M_o ,利用视频中相关目标的轨迹坐标。
通过 GPT-3.5 Turbo,基于这些关节或轨迹生成运动描述,特别关注它们随时间演化。生成的描述记为 Q_t^m = \{s, o\} ,其中 s 表示骨骼描述, o 表示人-物交互描述。这些生成的描述随后被附加到文本查询 Q_t 中,将其丰富为上下文信息。最终得到的增强查询 Q_t^\text{new} = [Q_t^m \, Q_t] 被用于指令微调。
5 多模态渐进训练 MMPro
通过将 QA 对和上下文信息整合到 Q_t 中,使用传统的 LLVM 训练方法。然而,同时集成时间同步的多模态数据( \mathcal{X}_v 、 \mathcal{X}_s 和 \mathcal{X}_o )面临挑战,主要是由于不同模态之间的冲突梯度。
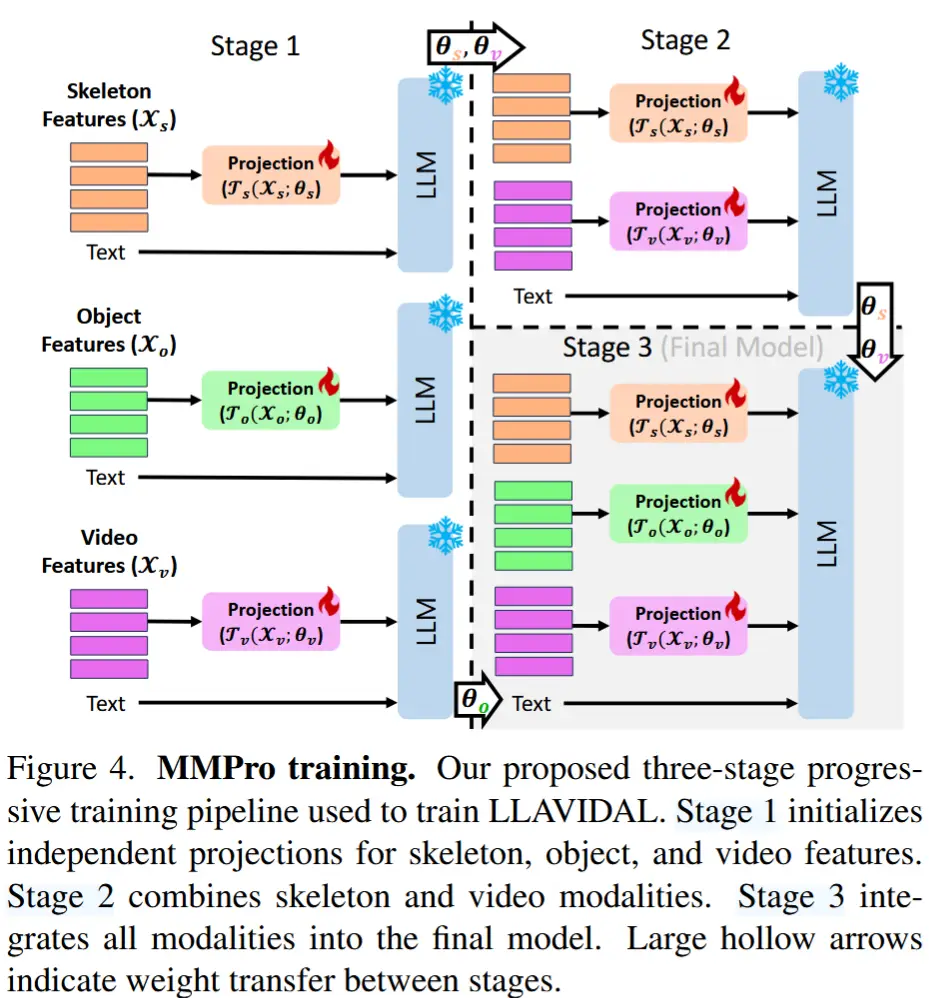
为了解决这一问题,作者采用了模态特定连接器(connectors),将每个模态与 LLVM 的输入空间对齐。为了缓解多模态训练的复杂性,为 LLAVIDAL 采用了一种多模态渐进(MMPro)训练策略。这种方法通过逐步增加模态特定连接器,按照预定义的 growth schedule 逐步提升训练复杂度,从而促进有效的多模态融合。
MMPro 训练被组织为 |\eta| 个等间距阶段,每个阶段包含 \frac{\text{Total iterations}}{|\eta|} 次迭代。在 LLAVIDAL 训练中,通过连接器将三种模态(视频、骨骼和人-物交互)整合到 LLM 的嵌入空间中,因此 \eta = 3 。
第 1 阶段:独立对齐
在第 1 阶段,特定模态与 LLM 嵌入空间进行对齐。具体而言,视频、骨骼和人-物交互特征分别通过线性投影层 \mathcal{T}_m 投影到 LLM 的嵌入空间,并且每个模态 m = \{v, s, o\} 具有各自的参数 \theta_m ,最终生成 LLM 输入令牌表示:
其中, Q_m \in \mathbb{R}^{F_m \times K} 。LLM 的输入由 Q_t 和 Q_m 的拼接组成,结构如下:[USER: \langle Q_t \rangle \langle Q_m \rangle Assistant:]。
模态集成顺序确定方法基于课程学习(Curriculum Learning) 的原则。课程学习是一种受教育学启发的机器学习策略,通过从简单任务逐步过渡到复杂任务来组织训练过程。MMPro 训练策略采用了一种增量难度递增的方法。指导集成顺序的复杂度衡量标准来源于第 1 阶段优化得到的自回归损失。研究结果表明,不同模态之间的集成难度存在梯度变化,其中视频和骨骼数据相对更容易与语言嵌入空间对齐,而人-物交互(HOI)则较为困难。因此,在 LLAVIDAL 中,模态按照骨骼、随后是 HOI 的顺序进行集成,遵循课程学习中逐渐增加难度的原则。
第 2 阶段:架构扩展与同时对齐
在训练的第 2 阶段,LLAVIDAL 的架构扩展以包含额外的模态特定连接器。这些连接器有助于视频和骨骼数据与 LLM 嵌入空间的同时对齐。此阶段的参数 \theta_v 和 \theta_s 继承了第 1 阶段优化得到的权重初始值。因此,输入到 LLM 的格式如下:[USER: \langle Q_t \rangle \langle Q_v \rangle \langle Q_s \rangle Assistant:]
其中, \langle Q_t \rangle 、 \langle Q_v \rangle 和 \langle Q_s \rangle 分别表示文本、视频和骨骼查询的嵌入。这种结构化的输入格式确保了在 MMPro 训练策略的第 2 阶段中,视频和骨骼模态能够有针对性地集成。
第 3 阶段:所有模态的融合
在 LLAVIDAL 的最终集成阶段,所有模态都被纳入其中。视频和骨骼的训练参数 \theta_v 和 \theta_s 在第 2 阶段的基础上进一步优化,而 HOI 的参数 \theta_o 则从第 1 阶段的训练初始化。此时,输入到 LLM 的内容还包括一个额外的对象模态,格式为:[USER: \langle Q_t \rangle \langle Q_v \rangle \langle Q_s \rangle \langle Q_o \rangle Assistant:]
如图4所示,这种集成方法将视频、对象和骨骼模态与 LLM 嵌入对齐,增强了模型准确处理和理解 ADL 的能力。
6 实验
6.1 实验设置
- 模态编码器
- 视觉:CLIP-L/14
- HOI目标特征:OWLv2
- 骨骼特征:SkeletonCLIP
- 大模型:Vicuna
- 数据集
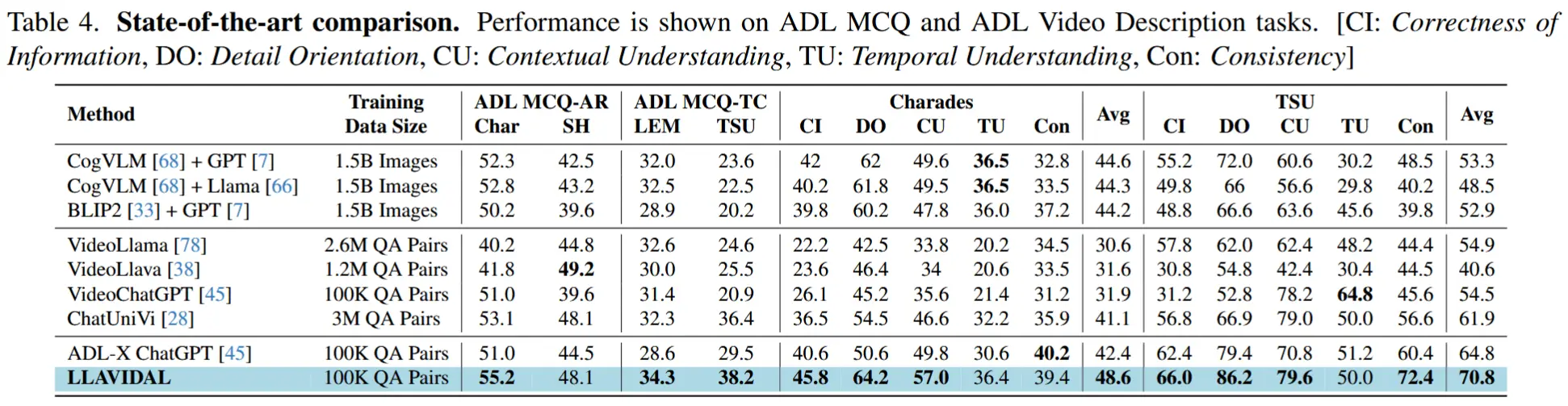
- 作者引入的两个新的基准测试:ADL MCQ-AR、ADL MCQ-TC。前者涉及用于动作识别的多项选择问答,后者侧重于预测时间序列中缺失的动作。
- ADL MCQ-AR使用了 Charades 和 Toyota Smarthome 数据集。
- ADL MCQTC使用了 LEMMA 和 Toyota Smarthome Untrimmed(TSU) 数据集。
- 除了上述两个基准任务,作者还使用Charades和TSU进行了ADL视频描述任务。
- 请注意,所有的评估都是零样本执行的。
6.2 与SOTA比较
- 包括MCQ-AR、MCQ-TC、以及ADL视频描述任务。
- 对于描述评估,参考 [45],将生成的描述与真实描述进行对比,并通过 LLAMA 在Information Correctness、Detail Orientation、Contextual Understanding、Temporal Understanding和Consistency等维度上打分,分数上限为 100。