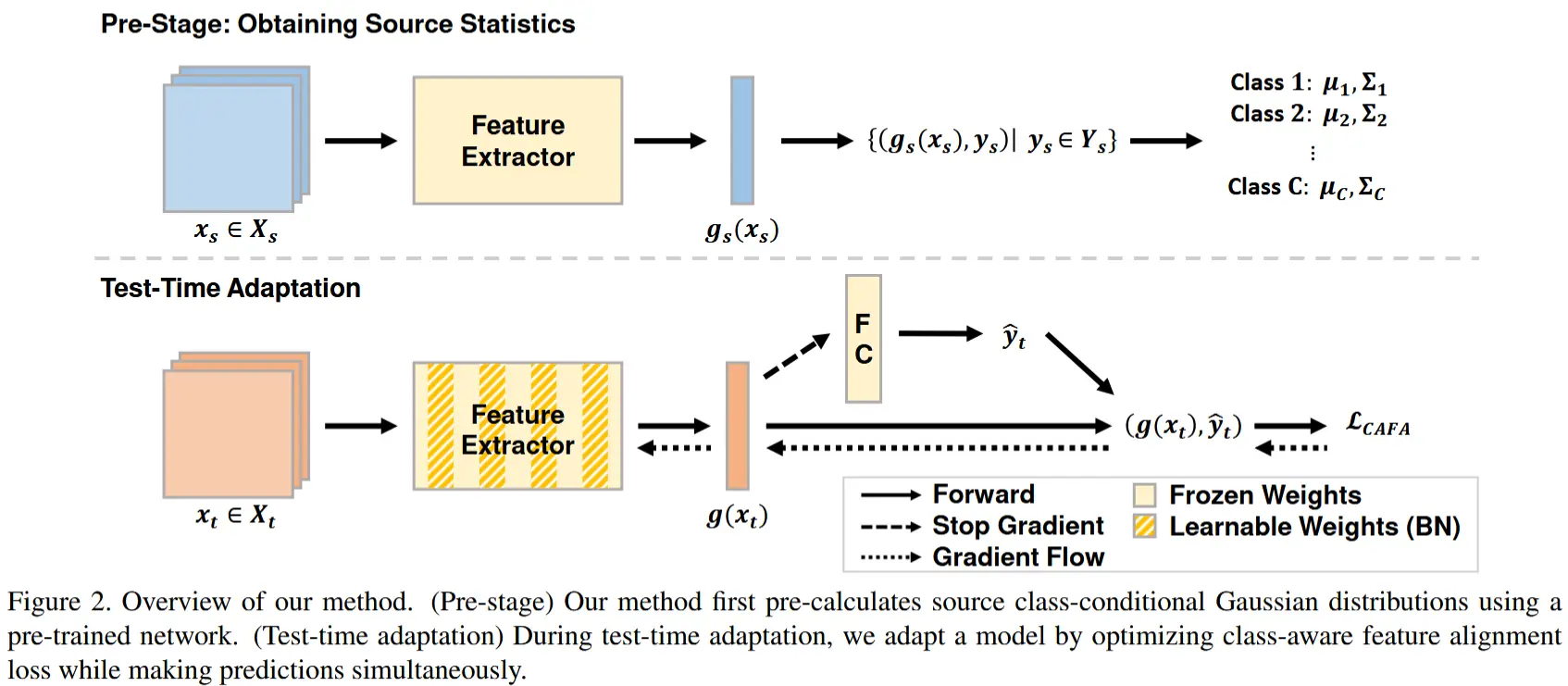
- 论文 - 《FoCTTA: Low-Memory Continual Test-Time Adaptation with Focus》
- 关键词 - 内存高效、延迟高效、TTA、图像分类、剪枝
摘要
- 研究问题
- 测试时持续适应领域偏移(CTTA)
- 现有的TTA方法通常通过更新所有批归一化(BN)层来实现自适应,这种方法存在两个内存效率低下的问题。
- (1)依赖BN层进行自适应需要较大的批量大小,从而导致高内存使用。
- (2)更新所有BN层需要存储所有BN层的激活值以用于反向传播,进一步加剧了内存需求。
- 使得现有解决方案在物联网设备上难以实用。
- 本文工作
- 本文提出了FoCTTA,一种低内存的CTTA策略。其核心思想是自动识别并适应少数对漂移敏感的表示层。
- 从BN层到表示层的转变消除了对大批量的需求;同时,通过仅更新关键适应层,FoCTTA避免了存储过多的激活值。
- 这种聚焦适应的方法确保FoCTTA不仅具有内存效率,还能保持高效的自适应能力。
- 实验结果
- 在相同的内存限制下,FoCTTA在CIFAR10-C、CIFAR100-C和ImageNet-C数据集上的适应精度分别比现有最先进方法提升了4.5%、4.9%和14.8%。在不同批量大小下,FoCTTA平均减少了3倍的内存使用,同时在这三个数据集上的精度分别提升了8.1%、3.6%和0.2%。
1 介绍
- 现有研究不足之处
- 目前主流的CTTA方案选择了计算效率,,但这并不容易转化为内存效率,而内存效率对于物联网应用至关重要。
- 这些方法通过更新所有批归一化(BN)层的仿射参数来适应目标域,尽管仅更新了少量参数,但该策略仍需大量内存才能正常运行。
- 实验证明
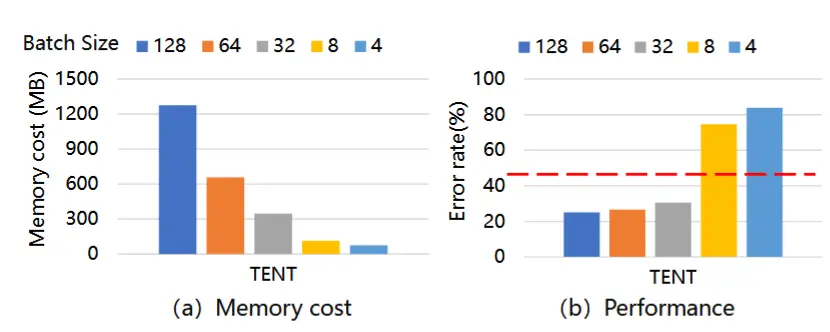
- 图1(a)展示了最早的TTA方法TENT(Wang et al. 2020)的内存使用情况随批量大小增加的变化趋势。
- 如图1(b)所示,基于BN的方法对批量大小非常敏感。在目标域中,它只有在消耗8倍内存的情况下才能保持高于原始预训练模型(36.5MB)的精度。
- 提高内存效率的CTTA方法
- 如表1所示
- TENT通过仅更新批归一化(BN)层来减少自适应过程中的激活值存储。
- MECTA(Hong et al. 2023)进一步在反向传播过程中对缓存的BN层激活值进行剪枝。
- EcoTTA(Song et al. 2023)则完全冻结整个模型参数,仅更新少量额外的元层。
- TTN(Lim et al. 2022)根据每个BN层对领域偏移的敏感性调整由测试时批次更新的BN层权重。
- 这些方案通过减少适应层(或通道)的数量来提高内存效率,从而节省反向传播过程中激活值的存储。然而,它们仍然依赖较大的批量大小来提升适应精度,因此在低内存适应方面仍然不够理想。

- 本文工作
- 提出FoCTTA,该方法能够在小批量大小和低激活值存储的情况下运行。
- 具体而言,FoCTTA选择更新表示层而非BN层,以使其对批量大小更具鲁棒性。此外,考虑到不同表示层对适应的重要性各异,我们仅更新最重要的前K个表示层,以减少激活值的存储。
- 识别关键层:这通过在预训练后、测试前的一个离线预热训练阶段实现,其中利用模拟的未见分布偏移,通过简单的基于梯度的重要性指标识别出漂移敏感的表示层。
2 问题陈述
2.1 CTTA 的内存开销
在 CTTA 中,模型 f_{\theta} 通常是一个神经网络 f_{\theta}(\cdot) = f_{\theta_L}(f_{\theta_{L-1}}(\cdots(f_{\theta_1}(\cdot))\cdots)),其中第 l 层的参数为 \theta_l。假设参数 \theta_l 包含权重 W_l 和偏置 b_l,该层的输入特征和输出特征分别为 a_l 和 a_{l+1}。给定前向传播公式 a_{l+1} = a_l W_l + b_l,对应的反向传播(批量大小为 1)公式为:
方程 (1) 表明,为了更新可学习层的权重 W_l,必须存储所有 a_l 来计算梯度。因此,对于具有 L 层的模型,在批量大小为 B 的情况下,反向传播的内存成本可以估计为:
其中,m(\cdot) 表示内存需求。从方程 (2) 可知,通过梯度下降进行自适应的内存成本会随着更新的层数 L 和批量大小 B 的增加而增加。需要注意的是,权重 \theta 在自适应过程中是常量,不会占用额外的内存。
2.2 CTTA 中更新的参数
现有 CTTA 方法在测试时更新预训练模型 f_{\theta}(y|x),以更好地逼近目标分布 p(y|x)。参数 \theta 通常被划分为可适应权重 \theta^a 和冻结权重 \theta^f,其中可适应权重 \theta^a 通过最小化无监督损失 \mathcal{L}(x; \theta^a \cup \theta^f), x \sim p_t(x) 来更新。不同 CTTA 方法在参数划分 \{\theta^a, \theta^f\} 和损失函数 \mathcal{L} 的选择上有所不同,而可适应权重 \theta^a 的选择会影响内存成本。本文专注于识别能够实现低内存开销且不牺牲自适应精度的可适应权重 \theta^a。
3 方法
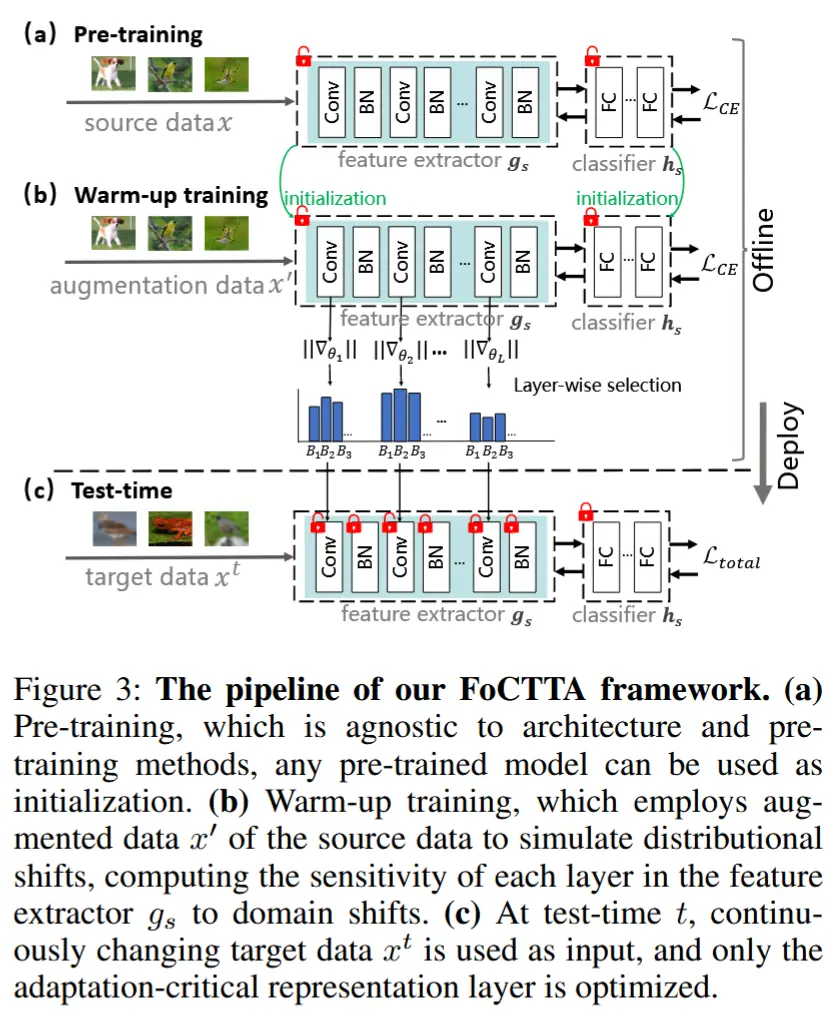
图 3 描述了 FoCTTA 的工作流程。
3.1 为 CTTA 更新表示层
如前所述,CTTA 的核心问题之一是确定可适应参数 \theta^a。受源假设迁移(source hypothesis transfer)概念的启发,本文将注意力集中在 CTTA 的表示层上。模型 f_{\theta}(y|x) 可以分解为特征提取器 g_s 和分类器 h_s,其中 f_{\theta}(y|x) = h_s(g_s(y|x))。对于 CTTA 来说,只需更新特征提取器 g_s 即可。由于更新特征提取器可以减少可适应层的数量,因此这种方法具有实现内存高效 CTTA 的潜力。
我们进一步推进这一想法,提出以下问题:通过选择性地更新表示层,能否实现高精度的 CTTA?也就是说,我们认为表示层的重要性在 CTTA 中是不同的,因此只需要更新最关键的层。尽管层重要性和逐层微调在网络剪枝中已被广泛研究,但这些观察和假设主要针对同一领域内的监督学习。 目前尚不清楚是否适用于无监督的域偏移自适应。
为此,我们进行了一项实证研究,以了解各个表示层对 CTTA 的重要性。具体而言,我们选择了三种常用的层重要性度量标准:梯度范数、\ell_1 范数以及权重范数。这些度量通常用于无域偏移的监督训练,并从中选择前 K 个最重要的层(K=5)进行自适应。我们在标准 CTTA 基准上的多种模型和数据集上进行了测试。图 2 显示了结果。我们得出以下观察结果:
- 表示层的重要性在 CTTA 中有所不同。 不同度量标准所指示的重要性在各层之间存在差异。例如,梯度范数表明重要的表示层是浅层(靠近输入的层),\ell_1 范数显示深层更重要,而权重范数则表明关键的表示层在整个模型中分布。
- 梯度范数指示 CTTA 中的层重要性。 在三个数据集上,我们一致观察到,通过梯度范数选择的重要表示层能够达到最高的精度。 而由其他两种度量标准识别的重要层甚至导致性能低于未进行自适应的模型。
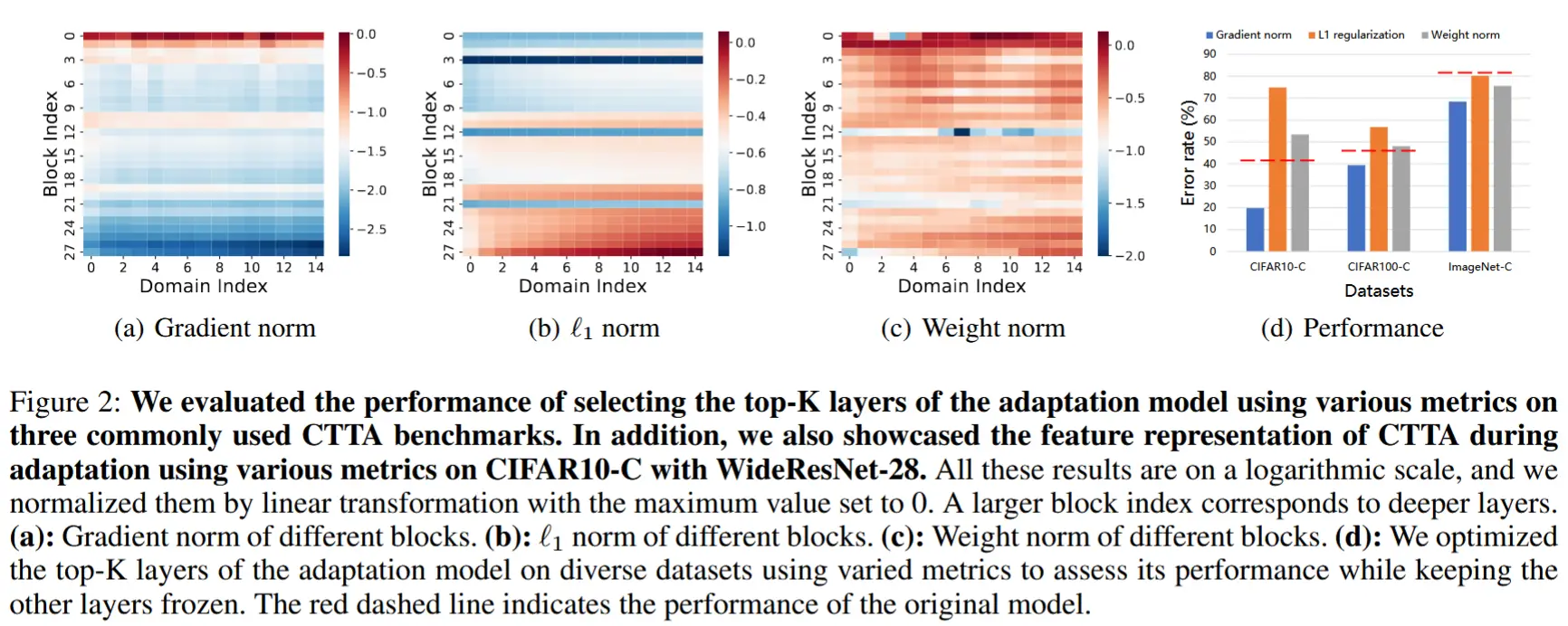
总结:在 CTTA 的上下文中,层的重要性也有所不同,并且梯度范数作为 CTTA 的有效重要性度量标准。
3.2 识别关键表示层
核心操作:为了识别对领域偏移敏感的重要表示层,作者在预训练后、测试前引入了一个额外的“预热训练”阶段。该阶段通过增强原始训练数据来模拟领域偏移。
具体而言,对每个原始数据点 x 创建一个增强版本 x',使其共享相同的语义信息。如图 3 所示,在预热训练阶段,冻结预训练模型的分类器 h_s,使用增强数据 x' 作为输入,通过交叉熵损失优化特征提取器 g_s,并收集每批中 g_s 的每一层的梯度范数。
每层的平均梯度范数量化了该层的重要性:
其中,B_N 表示第 N 批的批量大小,\theta_l 和 \nabla_{\theta_l} 分别是第 l 层的参数和梯度。向量 s 的长度为 L,存储了预训练模型中所有层的重要性。 然后,排序,选择更重要的层。在实践中,选择是通过 \alpha \|s\| 进行的,其中,\alpha 是一个可调超参数,用于平衡内存开销和精度。需要注意的是,预热训练是在测试之前进行的。此外,它在测试时不需要访问源数据集 (X^S, Y^S),并且对原始模型的架构和预训练方法是无关的。
3.3 CTTA 目标
在测试时自适应过程中,FoCTTA 仅优化目标域中至关重要的适应层,保持其他层不变。与EATA中一致,利用自适应模型预测的熵来识别可靠的样本以进行后续模型优化。因此,在线自适应损失函数被定义为:
其中,\hat{y} 是测试图像的预测输出,p(\cdot) 表示 softmax 函数。符号 \mathbb{I}_{\{\cdot\}} 表示指示函数,而 H_0 是预定义的超参数。
此外,为了防止由于长期持续自适应而导致的灾难性遗忘和误差积累,在优化公式 (4) 时向损失函数中添加了一个正则化项。最终的损失函数被定义为:
其中,\lambda 是一个正标量,用于控制损失函数中两项的比例。M = \alpha \|s\| 表示需要更新的层的数量。\tilde{x}_m 和 x_m 分别表示自适应模型和原始模型的第 m 层输出。我们的评估表明,只需要更新一小部分(1.0%)的表示层即可。
4 实验
4.1 实验设定
- 数据集:CIFAR10-C CIFAR100-C ImageNet-C
- 实验细节
- 预训练模型:WideResNet-28、WideResNet-40、ResNet-50
- 在预热训练阶段,对所有源数据应用了多种数据增强技术,例如颜色抖动、填充、随机仿射变换、中心裁剪、反色和随机水平翻转。
- 评估设置
- 在内存限制下,测试每种方法的错误率。
- 在相同批量大小下,计算每种方法的错误率和内存消耗,包括模型参数和激活值的存储大小。我们通过使用 TinyTL 提供的官方代码展示内存效率。
- 基线:Source、Continual Tent、CoTTA、EcoTTA、EATA、SAR、SWA、LAW
4.2 性能比较
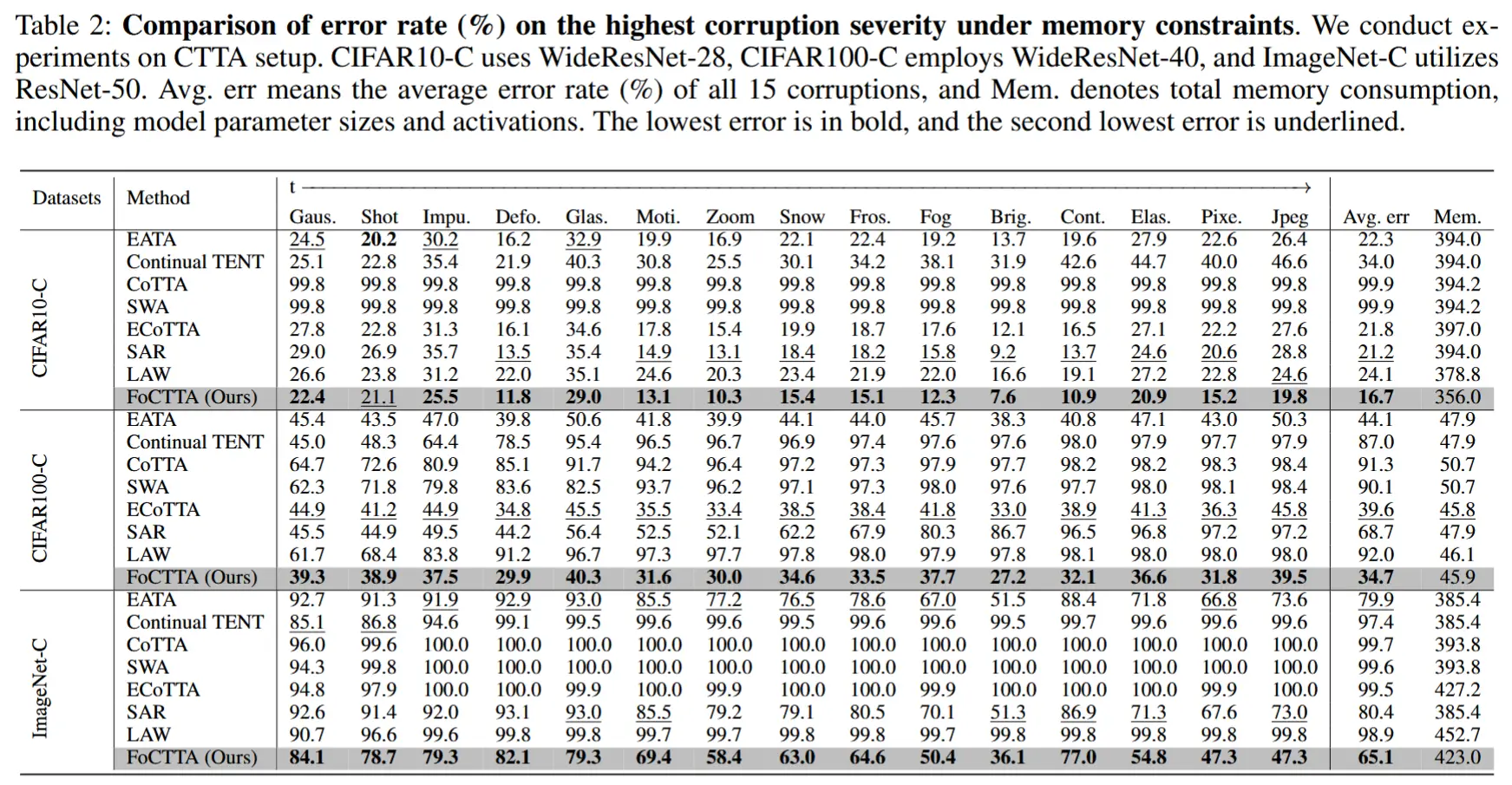
- 内存约束下的性能评估
- 如表2所示,通过调整批量大小使所有方法的内存消耗具有可比性,从而在内存限制条件下评估精度。
- 对于更新所有BN层或所有参数的方法需要使用较小的批量大小以满足内存限制,导致性能显著下降甚至崩溃。
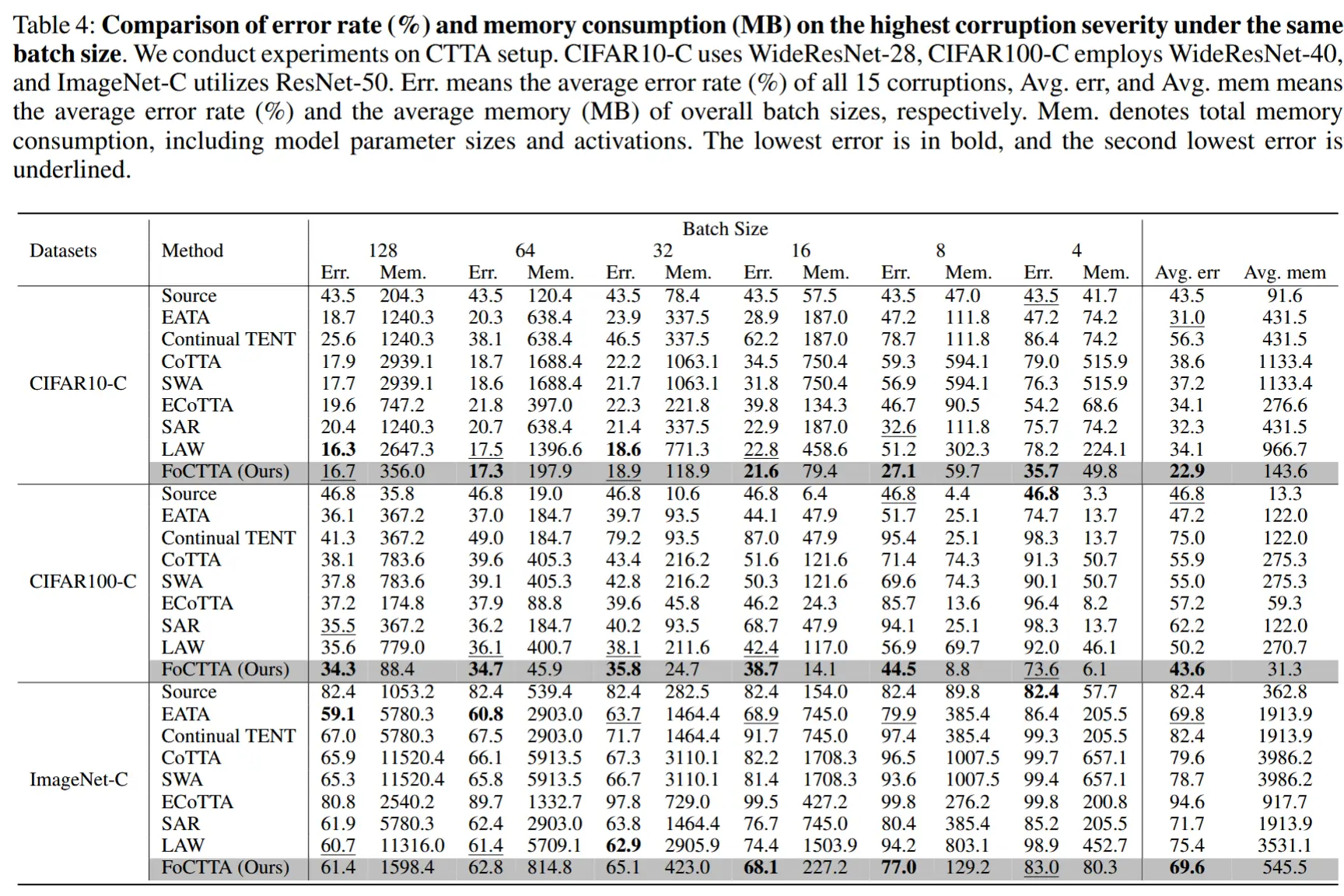
- 相同batchsize下评估
- 表 4 展示了在 CTTA 设置下,不同批量大小、模型和数据集上的在线测量平均错误率和内存消耗。
- FoCTTA 在 CIFAR-10C、CIFAR-100C 和 ImageNet-C 上分别实现了 三倍的内存消耗减少 。
- 在内存效率显著提升的同时,FoCTTA 的平均精度分别提高了 8.1%、3.6% 和 0.2% 。
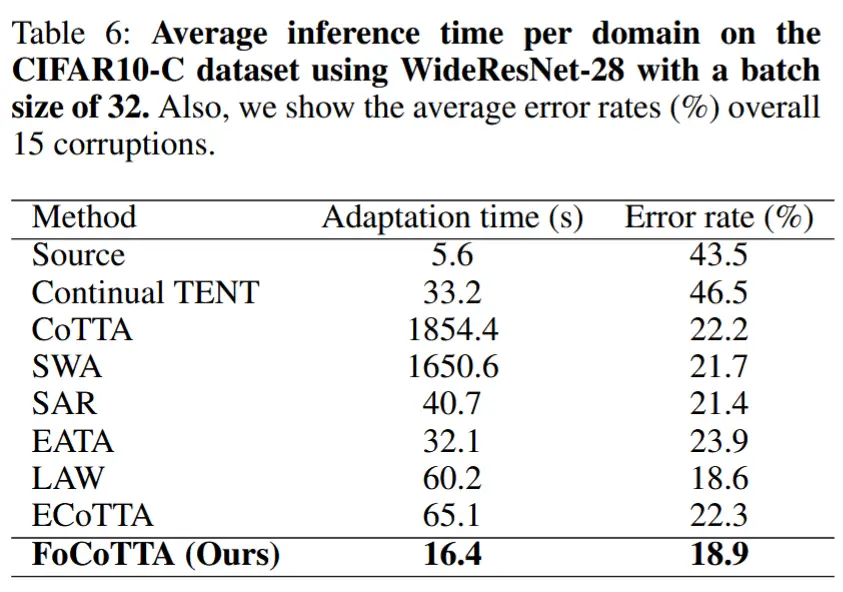
- 适应时间
- 表 6 展示了不同方法在每个领域的平均适应时间,以及在 15 种损坏类型上的平均错误率。
- FoCTTA 的适应时间显著低于现有最先进方法。相较于 CoTTA,FoCTTA 将适应时间减少了 113 倍 。相较于最快的适应方法 EATA,FoCTTA 将适应时间进一步缩短了 2 倍 。
4.3 消融
- 表 3 展示了移除 FoCTTA 中单个设计组件对其性能的影响。