- 论文 - 《MECTA: MEMORY-ECONOMIC CONTINUAL TESTTIME MODEL ADAPTATION》
- 代码 - Github
- 关键词 - 图像识别、TTA、内存高效、ICLR2023
摘要
- 问题背景
- 持续测试时适应(Continual Test-time Adaptation, CTA)是一种在不断变化的环境中确保模型精度提升的有前景的技术。
- 当前最先进的方法通过计算高效的在线测试时梯度下降来提高分布外模型的准确性,但即使只更新了少量参数,其内存消耗也达到了推理过程的数倍之多。阻碍了CTA在内存受限设备上的广泛应用。
- 解决办法 - MECTA
- 性能分析表明,主要的内存开销来源于反向传播中的中间缓存,其规模随批量大小、通道数和层数增加而扩展。因此,作者提出 减少批量大小,采用 自适应归一化层 以保持稳定且准确的预测,并 启发式地停止反向传播的缓存。
- 另一方面,通过对网络进行 剪枝 来降低优化过程中的计算和内存开销,并 在之后恢复参数 以避免遗忘。
- 实验性能
- 在CIFAR10、CIFAR100和ImageNet三个数据集上,MECTA在内存受限的情况下将模型精度至少提升了6%,并在ImageNet数据集上将ResNet50的内存消耗减少了至少70%,同时保持了相当的精度。
1 介绍
- TTA内存瓶颈
- 图 1 展示了使用批量大小为 64 对 ResNet50 进行Tent/EATA适配的情况,其
model.backward过程的内存消耗是 ImageNet-C 标准推理的 5倍以上。
- 图 1 展示了使用批量大小为 64 对 ResNet50 进行Tent/EATA适配的情况,其
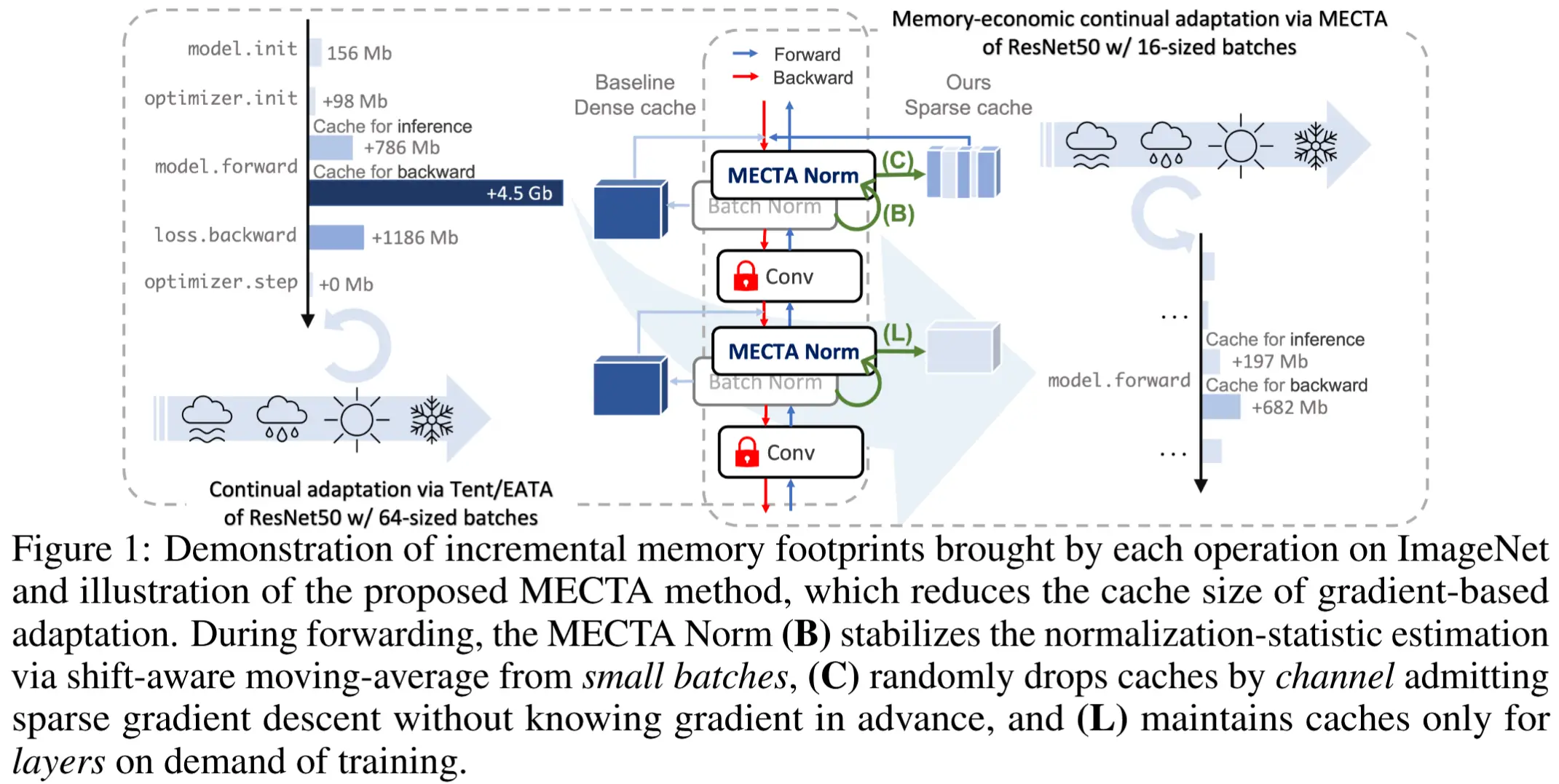
- 本文方法 - Memory-Economic Continual Test-time Adaptation, MECTA
- 如图1所示,MECTA 方法被封装在一个简单的归一化层中,称为MECTA Norm,以减少中间缓存的三个维度:批量大小、通道数和层数。
- 批量:MECTA Norm通过 流式小批量数据 积累分布知识,并使用一个 域迁移感知遗忘门 在小批量和跨域迁移的情况下保持稳定。
- 通道:类似于稀疏梯度下降,引入了测试时剪枝 ,该方法随机移除缓存中间结果的通道,而无需了解梯度幅值。
- 层数:遗忘门还指导层的适应:如果某一层的分布差距足够小,则该层将被排除在内存密集型训练之外。
- 如图1所示,MECTA 方法被封装在一个简单的归一化层中,称为MECTA Norm,以减少中间缓存的三个维度:批量大小、通道数和层数。
2 相关工作
2.1 测试时适应
- 早期需要重新设计训练过程的工作
- 测试时训练(Test-time Training)(Sun等)及其变体(Liu等),它们通过监督和自监督目标联合训练源模型,并在测试时通过自监督目标进行模型适应。
- 自适应风险最小化(Zhang等)、上下文元学习以及条件神经过程(Garnelo等)则训练能够根据测试数据推断上下文信息的模型。
- 近期与训练无关的适应方法
- 通过调整批归一化统计量(Nado等;Schneider等,2020;Khurana等)
- 最小化无监督熵损失(Wang等;Goyal等)
- 最大化多增强预测一致性(Zhang等)
- 分类器调整(Iwasawa & Matsuo)
- 尽管这些方法有效,但它们的应用场景局限于静态测试环境,与实际动态变化的场景形成对比。
2.2 高效的持续测试时适应
- Efficient Continual Test-time Adaptation (CTA) 考虑的则是动态的测试场景
- 相关工作
- Wang等人通过增强监督的方式在计算机视觉领域首次提出了持续设置,但由于对单个样本进行多次推理,这种方法存在较大的计算障碍。
- 基于批归一化(BN)的方法是一种高效的替代方案,只需更新统计量(Nado等;Schneider等)。
- Tent通过每个样本一次反向传播的方式更加高效(Wang等)
- Niu等人通过选择性反向传播提高了样本效率。
- 尽管CTA在计算效率方面取得了进展,但 其内存效率却被忽视,而这一点对于设备端适应尤为重要。
- 相关工作
3 问题定义
令 P(x) 表示从分布集合 \mathcal{P} 中采样的数据分布,而 P_0 是训练分布。假设分布 P \sim \mathcal{P} 要么与 P_0 完全相同,要么显著偏离 P_0 。一个神经网络模型 f_\theta ,其参数化为 \theta ,在训练集 P_0 上预训练。
使用预训练模型,Tent 和 EATA 通过递归更新持续适应模型:
对于步骤 t \in \{1, 2, 3, \dots\} ,其中 \text{Optimize}(\cdot, \cdot) 表示一个通用优化算法,给定初始值 \theta_{t-1} 来最小化第一个变量。在没有标签的情况下,熵函数 H(f_\theta(x)) = \ell_{\text{ent}}(f_\theta(x), f_\theta(x)) 类似于 Tent 中的 自监督交叉熵损失。
参数高效适应
由于测试时效率至关重要,关注最先进的 CTA 解决方案:EATA 和 Tent,两者都采用了 one-step 梯度下降作为优化策略(公式 (1))。因此,\text{Optimize}_{\theta \in \Theta_t}(EH, \theta_{t-1}) = \theta_{t-1} - \eta \frac{\partial}{\partial \theta} \mathbb{E}H,其中学习率为 \eta 。为了高效地训练模型,我们将参数空间限制在原始参数空间的一个子空间中,记为 \Theta_t = \widetilde{\Theta} \subset \Theta 。本文遵循 Tent 和 EATA 的做法,使 BN 层中的参数可训练。
批归一化层
设输入到第 l 层的特征批量为 x^l ,维度为 B \times C^l \times H^l \times W^l ,其中 B 是批量大小, C^l 是通道数, H^l 和 W^l 是高度和宽度。用 [N] 表示集合 \{1, \cdots, N\} 。对于 (n, i, j, k) \in [B] \times [C^l] \times [H^l] \times [W^l] 和一个小常数 \epsilon_0 ,BN 层被定义为两个连续的 通道级操作:
其中 \mu^l_i, \sigma^{l^2}_i 分别是通道 i 中 x^l 的平均值和方差。输出张量 a 也称为激活。对于Tent和EATA,只有仿射参数 \gamma 和 b 才能训练。
4 方法
在本节中,将详细介绍改进基于梯度的适应方法内存效率的提出方法。首先,简单的推导表明,为了计算仿射层的梯度,中间表示需要存储以计算仿射层的梯度,从而导致巨大的内存开销。假设第 n 个样本的损失为 \ell_n 。根据公式 (2),关于第 i 个通道的仿射权重 \gamma_i^l 的梯度是:
因此,为了计算梯度,每个 BN 层必须存储维度为 B \times C^l \times W^l \times H^l 的归一化表示 z^l (缓存),直到 \partial \ell_n / \partial a_{i,j,k}^l 可用。对于一个 L 层网络,仅推理时仿射层的内存消耗为 R_{\text{fwd}} = \max_{l \in \{1, \dots, L\}} B \times C^l \times W^l \times H^l 。相比之下,反向传播对应的中间内存消耗为 R_{\text{bwd}} = \sum_{l=1}^L B \times C^l \times W^l \times H^l \geq R_{\text{fwd}} 。
为了减少内存开销,一个直接的想法是通过丢弃 \{z^l\}_{l=1}^L 中相应的条目来减少 B 、 C^l 和 L ,但是这将消除相应的梯度,很容易破坏学习过程。下面,将讨论减少 B 、 C^l 和 L 维度的准确性保证缓存减少的障碍和解决方案。
4.1 动态分布上的自适应统计估计 (Reduce B)
(困难) 足够的样本数量对每个 BN 层的准确统计估计( \mu 和 \sigma^2 )至关重要,减少批量中的样本会偏置归一化的统计量。
(解决-EMA) 指数移动平均(EMA) 被广泛用于通过记忆流式批次来减轻偏差。为了保持校准统计量上的梯度属性,作者在测试时实现 EMA 归一化。
(公式化) 令 \phi 表示 BN 层中均值和方差的复合元组 [\mu, \sigma] 。 \phi_t 表示第 t 次迭代的运行统计量,而 \hat{\phi}_t 是来自第 t 批次的统计量。EMA 统计量为
参数 \beta \in [0, 1] 控制记忆长度,因此充当遗忘门。
(自适应遗忘门) 传统上, \beta 在运行时是固定的,但这无法适应动态分布 P_t 的估计。直观地讲,当模型在一个单一领域中稳定运行时, \beta 应该较小,以尽可能多地保留数据点,从而支持准确的统计估计。相反,当分布发生变化时,\beta 应该较大,以避免两种不同统计量的混合。遵循这一直觉,引入了一个自适应校准 \beta 的遗忘门,即 \beta_t = h(\phi_{t-1}, \hat{\phi}_t) ,其中 h(\cdot, \cdot) 捕获分布偏移。对 h(\cdot, \cdot) 的非参数启发式定义如下:
其中 D(\cdot, \cdot) 是一个适当定义的距离函数,用于衡量分布偏移。 KL(\phi_1 \| \phi_2) 定义为 \log \sigma_2^2 - \log \sigma_1^2 + \frac{1}{2\sigma_2^2} (\sigma_1^2 + (\mu_1 - \mu_2)^2) - \frac{1}{2} ,假设两个高斯分布分别由 \phi_1 和 \phi_2 参数化。该距离函数受到 Li 等人(2017)的启发,作者表明,如果 \phi_1 和 \phi_2 来自不同的域,则它们的 KL 散度较大(基于高斯假设)。此外, \beta_t^l 是逐层估计的,因为不同层的分布将向不同程度偏移。直观地讲,当校准 \phi_t^l 后,浅层较好对齐时,深层也应该更好地对齐。
4.2 通过随机剪枝缓存实现稀疏梯度 (Reduce C)
(困难) 丢弃 z 中通道 i 的缓存将使该通道对应的梯度消失,并可能导致相应的仿射参数欠拟合。因此,简单地修剪通道可能会引发严重的问题,尤其是在某些通道对分布外(OOD)泛化至关重要时。然而,在计算梯度之前很难预测哪些梯度是如此重要而不能被修剪。
(随机剪枝策略) 因此,需要 一种不依赖反向传播 的高效修剪策略。为此,作者提出了一种无条件的修剪策略,通过每次迭代生成一个随机掩码 M,其中 q \times 100\% 的掩码条目为零,其余为一。给定输入张量 z 到仿射层,使用 \tilde{z}_{n,i,j,k} = M_{i} z_{n,i,j,k} 对缓存进行掩码处理,如公式 (3) 所示。
(优点)
- 由于前向传播不受影响,仍然可以在网络的完整大小上进行预测,同时保留高质量的语义特征。
- 修剪显著降低了中间缓存和梯度的内存使用量。重新计算的掩码类似于现代优化器中的渐进学习范式,像 SGD 或 Adam 这样的动量技术可以补充缺失的梯度。
- 该方法缓解了灾难性遗忘问题,因为只有仿射权重的一部分被更新,而低幅度参数未被更新。具体来说,给定梯度 g_t ,模型差异 \|\theta_t - \theta_0\| = \|\sum_t g_t\| \leq \mathcal{O}(\sum_t \|g_t\|) 将会减少一些零梯度 \|g_t\| ,这可以被视为 EATA 中的一种隐式抗遗忘正则化。
4.3 按需训练层(Dynamic L)
(观察) 大多数测试时的适应过程将在单一环境中持续很长时间。例如,自动驾驶汽车在晴天运行的时间很长,会产生数千张图像。长时间连续地将模型适应于同一环境不会持续提升模型性能,反而会浪费资源。
(收敛停止适应) 因此,建议在优化收敛时停止反向传播,并根据需求重新启动它。可以重用公式 (5) 中的分布偏移来指导适应决策。具体来说,使用一个阈值 \beta_{\text{th}} 来做出决定。由于逐层决策,任何一层都可以在完全执行网络之前或所有层的优化收敛之前停止训练,从而节省大量内存。
(算法) 算法 1 中总结了所提出的方法,其中 MECTA 方法包括三个超参数以权衡准确性和内存。值得注意的是,MECTA 方法完全封装在一个 MECTA Norm 层中,可以轻松嵌入到像广泛使用的网络中。

4.4 与过去工作的对比
以前减少内存占用的尝试主要集中在参数稀疏性上,并减少了存储模型参数和梯度的开销。然而,与反向传播所需的缓存相比,参数或梯度的开销相对较小。相反,本文关注的是缓存的巨大开销,本文方法可以轻松与传统的参数稀疏性结合使用。
本文的通道剪枝和按需层训练类似于梯度稀疏性或坐标下降法,这两种策略在反向传播之前隐式地修剪梯度,从而避免了大缓存的使用。
除了梯度稀疏性之外,梯度检查点(Gradient Checkpointing, GC)是一种更通用的减少内存占用的方法。GC仅缓存部分层的输入,并根据需要重新计算中间特征。其最佳内存减少约为原始成本的 1/\sqrt{L}。尽管GC和本文的方法都可以显著减少内存,但本文的方法更具优势,因为 MECTA 能够按需减少内存,并且在计算效率上更高。
5 实验
5.1 实验设定
- 数据集:CIFAR10-C、CIFAR100-C、ImageNet-C(15种损坏、5种严重级别)
- 预训练模型:ResNeXt29-32×4d、ResNet50
- 基线方法:EATA、Tent、BN、梯度检查点
- 实验场景:终身学习(lifelong learning)场景,数据批次以流式方式依次到达
- 评估指标
- 准确率 (%)
- 缓存大小 (Mb):由于模型参数和优化器的内存消耗通常是固定的或与中间变量的大小呈线性相关,因此本文重点关注中间变量的张量大小。具体来说,实验计算仿射层的张量内存消耗,即公式 (3) 中的缓存 z^l。
5.2 OOD 性能基准
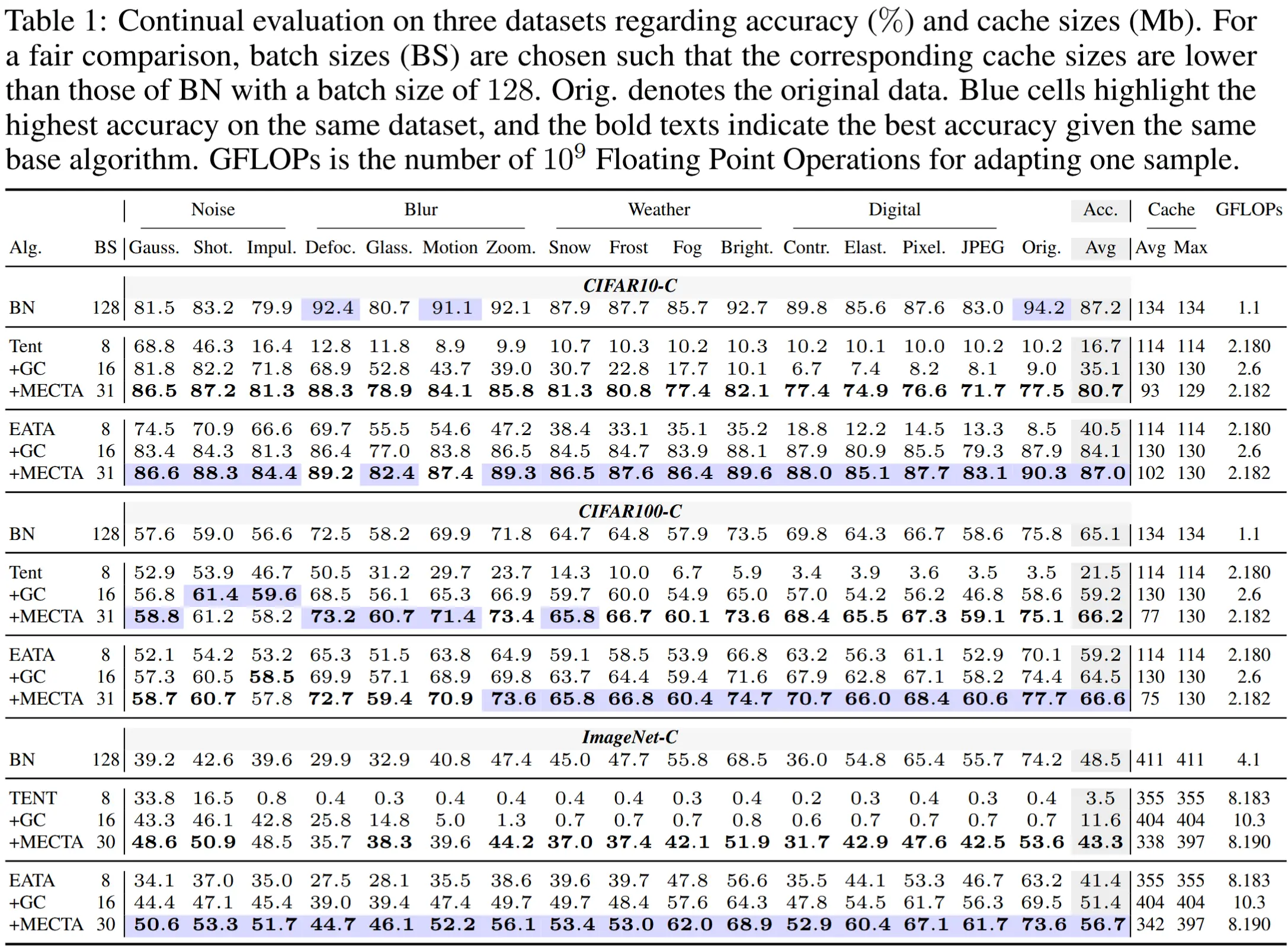
- 在相同缓存约束下的比较 - 表 1
- 实验设计:在缓存大小受限的情况下评估模型的准确性。为此,我们让无梯度方法(例如 BN)使用较大的批量大小(128),而基于梯度的方法从 {4, 8, 16, 32} 中选择较小的批量大小,以确保后者的最大缓存大小小于前者。
- 实验结果
- MECTA 在缓存约束下提高了准确性
- MECTA 比梯度检查点(GC)更高效
- 使用相同批量大小的比较 - 表 2
- 实验设计:与其他基线方法对比,包括:TTT(Sun 等, 2020)、TTA(Ashukha 等, 2021)、MEMO(Zhang 等, 2021)以及 CoTTA(Wang 等, 2022a)。所有方法仅调整 BN 层。
- 实验结果:
- MECTA 在相同批量大小下具有内存效率
- MECTA 减轻了遗忘问题

5.3 定性分析
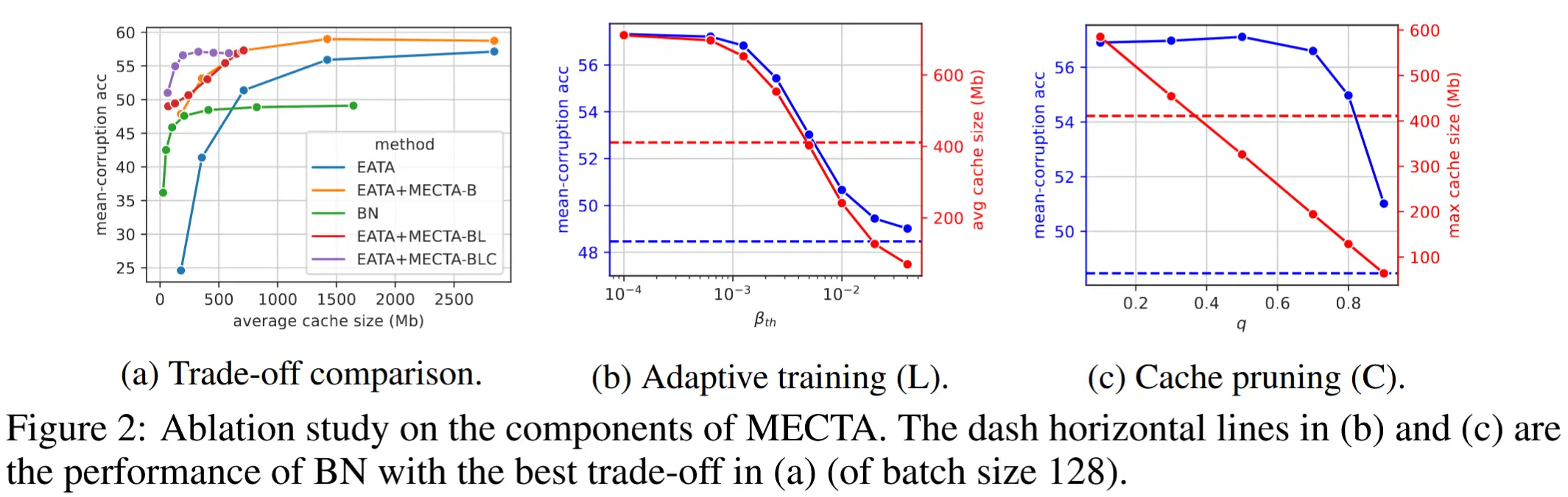
- MECTA 各组件对内存-准确性权衡的影响
-
实验设计:将各组件命名为 MECTA-X,X表示使用了第四节中的三个子组件B、C、L。
-
图 2a 展示了在 mean-corruption acc 上的总体比较结果。
-
实验结果:
- BN 在批量大小为 128 时达到最佳准确性,此时缓存大小约为 400 Mb。然而,准确性远低于 EATA 的最佳表现。
- EATA 对大批次(对应大缓存)的需求源于小批次(例如 8 或 16)下的性能较差。而 MECTA-B 通过引入自适应遗忘和记忆机制,显著提升了小批次适应的准确性。
- MECTA-L 和 MECTA-C 将内存-准确性权衡推向了低成本区域。
- MECTA-BLC 进一步显著提高了效率:在极小的缓存大小(少于 100 Mb)下仍能实现最佳准确性。
-
- 消融
-
L 自适应层训练
- 在图 2b 中,当 \beta_{th} 较小时,所有层都会被训练,因此缓存大小大于高效的 BN 适应方法。增加 \beta_{th} 会降低整个适应过程中的平均缓存大小。
-
C 通道剪枝
- 图 2c 显示,剪枝可以线性减少最大缓存大小,从而限制了整个适应生命周期中的最大内存需求。通过这种内存缩减,剪枝仅会轻微牺牲准确性,降低幅度不到 1%。
-
B 自适应遗忘
- 无参数记忆提升了每域准确性
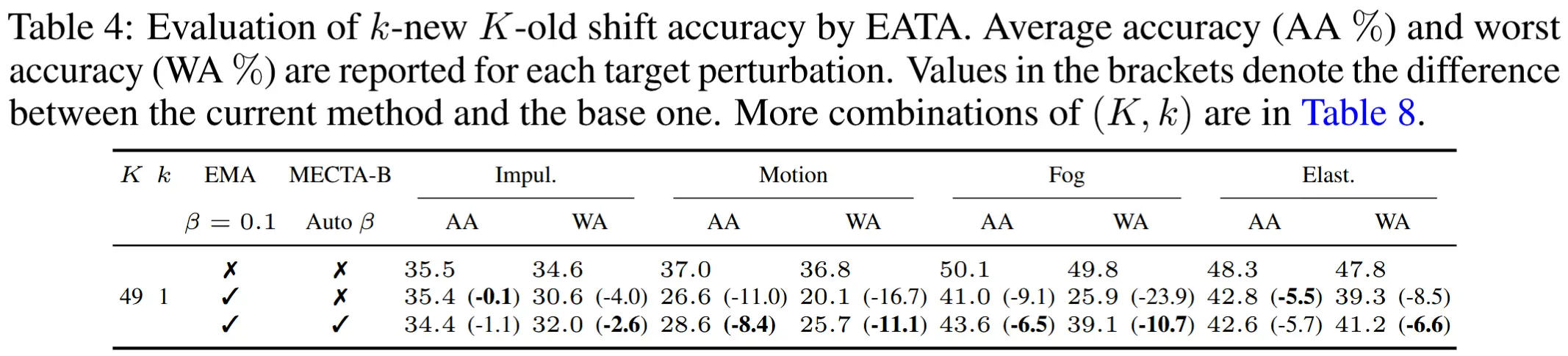
- 表 3 展示了在完整扰动集上使用所有扰动、批量大小为 16 的每域准确性,相比之下,MECTA-B 是无参数的,并且在所有损坏和原始数据上的表现均优于 EMA。
- 遗忘提升了分布偏移的稳定性
- 实验设计:为了量化分布偏移准确性,我们假设模型首先经历来自旧域的 K 个批次,然后接收来自新域的 k 个批次。分布偏移准确性是模型对 k 个新批次样本预测正确的比例。在此实验中,作者使用 ResNet50 在 ImageNet 上的一个扰动子集进行密集评估,包括 Impul、Motion、Fog、Elast。
- 如表 4 所示,MECTA-B 的自适应遗忘机制通过自动检测域偏移并利用短期记忆,显著提升了分布偏移的稳定性,避免了传统方法(如 EMA)因分布记忆引入的性能下降问题。
- 无参数记忆提升了每域准确性
-