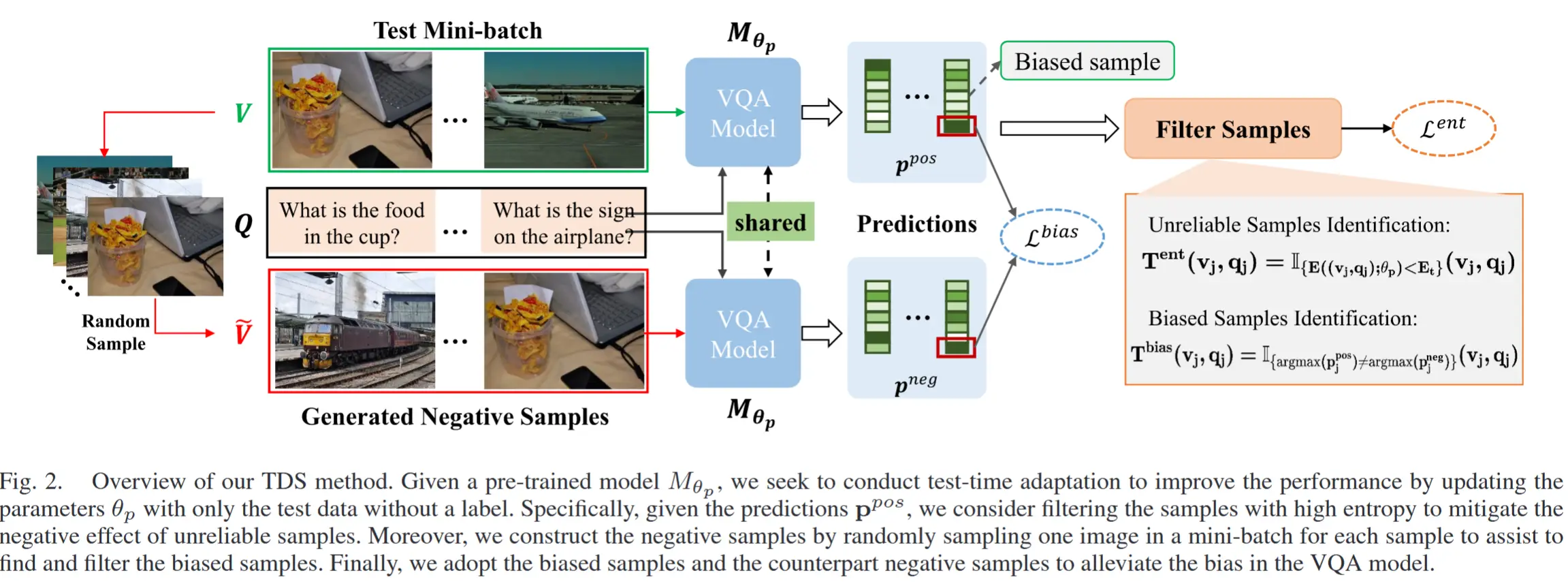
- 论文 - 《TinyTTA: Efficient Test-Time Adaptation via Early-Exit Ensembles on Edge Devices》
- 代码 - Github
- 关键词 - NeurIPS 2024、Early Exit、TTA、微控制器单元MCUs
摘要
- 研究背景
- 边缘智能:深度神经网络被直接部署在这些资源受限的单元上,以限制通信开销、提高效率和隐私性,并支持实时应用。
- 研究意义:测试时自适应 (Test-Time Adaptation, TTA) 被广泛用于适应不断变化的环境,即数据分布偏移,但其 在资源受限硬件环境中的有效性尚未得到充分探索,例如涉及微控制器单元 (MCUs) 的场景。
- 困难:
- 内存开销 :由于对大型预训练网络进行完整的反向传播导致的高内存需求;
- 缺乏对归一化层的支持 :MCU 上通常不支持归一化层操作;
- 批量大小的权衡 :大批次更新会导致内存耗尽,而小批次更新则会显著降低性能。
- 本文工作
- 提出了 TinyTTA ,首次实现了在内存受限设备上的高效 TTA。
- 作者引入了一种新颖的 自集成与批次无关的早退策略 ,用于 TTA。该策略能够 以小批量更新 实现持续自适应 --> 减少内存使用,处理分布偏移,并提升延迟效率。
- 作者开发了 TinyTTA 引擎 ,这是首个支持设备端 TTA 的 MCU 库。
- 实验
- 使用四个基准损坏数据集评估 TinyTTA 在两种边缘设备上的性能:配备 512 MB DRAM 的微处理器 (MPU) Raspberry Pi Zero 2W 和配备 512 KB SRAM 的 STM32H747 MCU。
- 实验结果表明,TinyTTA 将 TTA 的准确性提高了多达 57.6% ,内存使用减少了多达 6 倍 ,并实现了更快、更节能的 TTA。
- TinyTTA 是唯一能够在具有 512 KB 内存限制 的 STM32H747 微控制器上运行 TTA 的框架,同时保持了高性能。
1 引言
-
传统的 TTA 方法存在若干局限性,使其难以应用于边缘设备:
- 1)高内存开销 :由于反向传播的需要,带来显著的内存开销。
- 2)混合分布偏移的支持不足 :现有研究很少考虑混合分布偏移,并且通常对表现出不同分布偏移的样本统一更新网络。这种方法不仅会导致针对不同程度分布偏移的准确性差异,还会增加计算开销,因为理论上小范围偏移的样本可能不需要更新整个网络。
- 3)归一化层的缺失 :最有效的 TTA 策略通常涉及对归一化层的调整,但在实践中,当为 MCUs 开发模型时,这些层通常与卷积层融合,以减少计算和内存需求。
- 4)大批次大小的依赖 :基于归一化的 TTA 的有效性通常依赖于较大的批次大小,并且当批次较小时,现有方法性能显著下降,而受限硬件(如 MCUs)通常只能处理单一批次的数据。
-
本文工作 - 名为 TinyTTA 的新型 TTA 框架
- 解决 高内存开销 & 混合分布偏移 - 自集成和早退
- 自集成: 将预训练网络的后续层 分组为子模块,近似每个子模块以模拟完整网络的能力。
- 早退: 早退策略结合这些子模块,允许样本从不同的子模块退出,而不必在测试时遍历整个预训练网络。
- 优点:减轻遍历后续层的开销,并减少进一步传播的需求。
- 解决 归一化层缺失 & 大批次依赖 - 权重标准化
- 权重标准化: 通过模拟归一化层的效果来实现与批次无关的 TTA,同时减轻了实现归一化层的复杂性。
- 构建了一个操作符库,命名为 TinyTTA 引擎 ,以支持在 MCUs 上的实际部署。
- 解决 高内存开销 & 混合分布偏移 - 自集成和早退
2 相关工作
Modulating
-
内存密集型 TTA
- 微调型 TTA:通过更新整个模型架构来实现自适应,导致了极高的内存使用量。(CoTTA、Test-Time Training)
- 调制型 (Modulating) TTA:这类方法调整归一化层,同时冻结其他组件,然而由于模型仍然需要对完整结构进行反向传播,调制型 TTA 的内存使用量与微调型 TTA 类似。(TENT、NOTE、SoTTA)
-
内存高效型 TTA
- EATA:通过过滤高熵数据以最小化优化缓存;
- MECTA:通过停止反向传播缓存来减少内存需求。
- 然而,这些方法的分析 仍停留在理论层面,实际应用中并不高效,且其内存使用量已被证明与调制型 TTA 类似。
- 即使是目前最高效的 TTA 方法 EcoTTA [13],尽管通过蒸馏预训练模型(使用更浅层的模型)在 GPU 上实现了内存效率,但 仍然依赖于更新归一化层,而这些层在 MCU 上并不被支持。
-
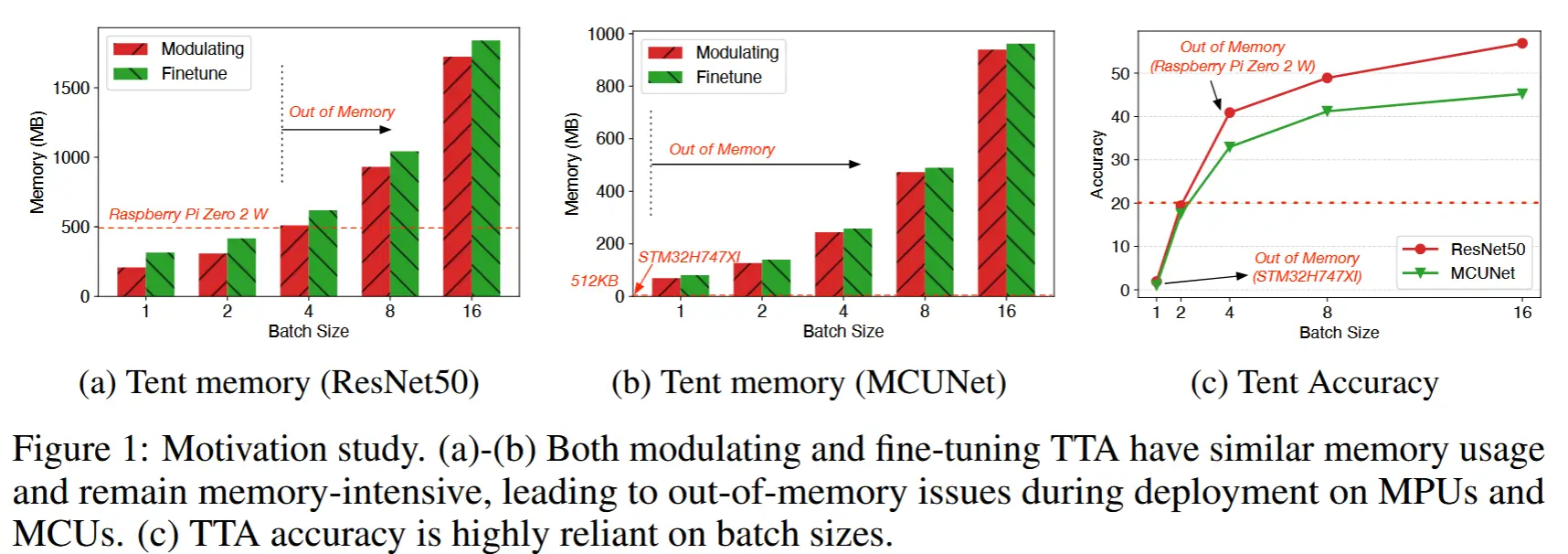
不同批次大小下的 TTA
- 如图 1c 所示,大多数 TTA 方法的成功依赖于较大的批次大小,因为这为归一化调整提供了更可靠的统计信息。
- 一些方法尝试通过不同的归一化技术来实现小批量(batch size = 1)的高效自适应,例如:Group Norm (GN)、Layer Norm (LN) 、Adaptive Batch Norm (AdaptBN)。
- 然而,所有这些方法在 TTA 性能上仍然表现较差,并且需要更新大量归一化层,这在计算上成本高昂。
- 早退机制
- 早退策略已被探索用于降低各种机器学习架构中的计算成本,特别是在实时和资源受限的应用中。
- 然而,大多数早退方法并未设计用于应对 MCU 中典型的分布偏移或小批次约束。
3 TinyTTA
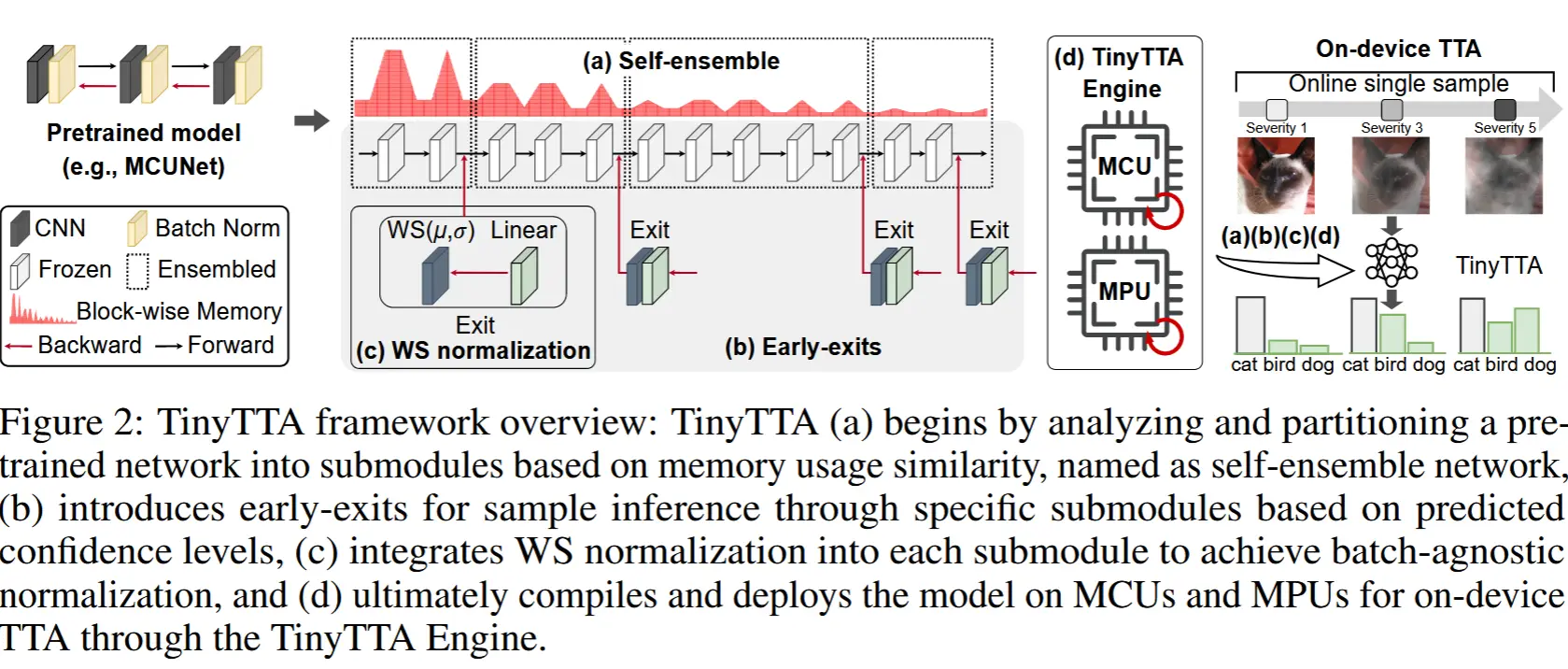
- TinyTTA 框架(图2),包含四个模块
- 自集成网络 :将网络划分为多个子模块,每个子模块近似于完整模型的能力;
- 早退机制 :根据预测置信度水平允许样本通过特定子模块进行推理,优化不同子模块的内存和计算效率,同时处理不同程度的分布偏移;
- 权重标准化 (WS) :集成到每个子模块中,以实现与批次无关的归一化;
- TinyTTA 引擎 :一个支持设备端 TTA 的 MCU 库。
3.1 自集成网络
-
核心思想:通过将网络层划分为子模块,并对相似的后续层进行分组,来实现自集成预训练模型,从而使每个子模块近似于完整模型的能力。
-
关键难点:确定所需的分区数量以及如何有效地将网络划分为子模块
-
依据:神经网络中的相邻层往往表现出较高的特征相似性+这些层通常具有相似的内存消耗。
-
实验分析
- 实验方法:测量预训练模型 ResNet50 各层在 TTA 过程中的内存使用情况,同时比较微调型 TTA 和调制型 TTA 之间激活值和权重的内存使用情况,目的是识别具有相似内存消耗的层。
- 实验结果分析
- 内存使用主要由激活值驱动,而权重消耗的内存在相比之下可以忽略不计,因此本文重点关注激活值内存以实现自集成;
- 在两种方法中,激活值的内存消耗相似,并且 主要集中在初始层,这些层通常捕获输入的关键信息;
- 某些相邻层组(具体来说是第 1-15 层、第 16-28 层、第 29-44 层和第 45-52 层)显示出相似的激活值大小。

-
设计自集成网络
- 将 具有相似内存消耗的层分组为子模块(即第 1-15 层为子模块 1,第 16-28 层为子模块 2,第 29-44 层为子模块 3,第 45-52 层为子模块 4),用于后续的早退机制,并 仅更新早退点的头部,冻结子模块以提高内存使用效率。
- 事实上,此过程 不需要对子模块进行反向传播,从而消除了对激活值内存的需求。
3.2 早退机制
- 核心思想:将输入依次通过级联的子模块,并在每个阶段计算一个置信度水平,若置信度超过预定义的阈值则在当前子模块退出,此时模型更新仅针对前面的子模块进行。
(符号说明)
假设我们得到了 K 个子模块,记为 \Theta = \{\theta^k\}_{k=1}^K。每个子模块进一步与退出点/分类器相关联,记为 \Phi = \{\phi^k\}_{k=1}^K,并通过一个线性层实现。对于第 i 个实例,每个子模块的输出首先计算如下:
其中, z_i^k \in \mathbb{R}^C 表示从第 k 个子模块中学到的潜在表示,而 p_i^k 表示经过 softmax 层后的第 k 个子模块分类器对 C 类别的预测概率。
给定预测概率 p_i^k ,可以使用熵来估计置信度水平,公式如下:
这里的 p_j^k 应该是指 p_{i,j}^k ,表示第 i个实例属于第 j 类的概率。
如果对于每个子模块 k , H(x_i) 小于预设阈值 \gamma^k ,这将导致实例的早退,并且也允许前序子模块进行自适应调整。否则,将继续使用后续子模块处理该实例。
3.3 权重标准化
(核心思想) 为了完全省略归一化层的使用,并在 MCU 上实现精确且内存高效的 TTA,本文首次在 TTA 中 引入权重标准化 (Weight Standardization, WS) 作为传统归一化层的替代方案。
(具体描述) 在每个子模块的线性层之前添加一个 WS 层。因此,每个子模块的退出点/分类器 \phi^k 包含一个 WS 层和一个用于 C 类分类的线性层。 本文方法仅调整 \phi^k(即 WS 统计量和一个线性层),同时冻结其他组件 \theta^k。这避免了小批次大小导致的模型崩溃问题,并最大限度地减少了内存使用。
(不同之处) 与传统的归一化方法(如 Batch Normalization) 和组归一化 (Group Normalization)主要关注重新中心化和重新缩放激活值不同,权重标准化 (WS) 的目标是对权重进行平滑处理。这种方法带来了更优的损失函数曲面和改进的参数更新。此外,WS 实现了与批次无关的归一化,因为它不受批次大小的影响。
(符号定义) WS 操作定义如下:
其中,\mu_w 和 \sigma_w 分别表示权重矩阵 W 在所有通道和维度上的均值和标准差,计算公式如下:
其中,w_{i,j} 表示权重矩阵中第 i 行第 j 列的元素。这种归一化直接应用于早退 CNN 层 \phi^k。重要的是,WS 不会在 CNN 层中引入额外参数,并且支持不同批次大小下的 TTA。
在推理过程中,WS 仅基于权重计算,无需实时累积批次统计信息,从而实现与批次无关的自适应调整。 这使得它适用于小批次大小,进一步确保了 TTA 过程中的内存和计算效率,使其适合在 MCU 上部署。从实现角度来看,为了在 MCU 部署时避免使用不被大多数硬件支持的批归一化层,作者在 TinyTTA 引擎(见第 3.5 节)中引入了一个新的 CNN 层,该层集成了 WS 归一化。
| 特性 | Batch Normalization (BN) | Weight Standardization (WS) |
|---|---|---|
| 归一化对象 | 中间激活值 | 模型权重 |
| 依赖批次统计信息 | 是,依赖当前批次的均值和方差 | 否,完全独立于批次统计信息 |
| 适合的场景 | 需要较大批次大小(batch size > 1) | 单样本推理(batch size = 1)或小批次场景 |
| 内存和计算开销 | 高,需要存储和更新批次统计信息 | 低,仅需对权重进行标准化 |
| 硬件支持 | 需要硬件支持复杂的归一化操作 | 更轻量化,适合资源受限设备(如 MCU) |
3.4 训练与推理
(训练方法) 为了便于子模块参数 \theta^k 和早退模型参数 \phi^k 的学习,作者在训练数据集上引入了所有模型的并发训练。给定源数据后,作者将数据同时通过预训练模型和带有早退分支的子模块,并计算损失以优化模型。
(损失函数) 第一个损失 \mathcal{L}_1 的目标是 从子模块和早退模块中推断出准确的预测,这可以表示为所有类别的交叉熵 (Cross-Entropy, CE) 损失。第二个损失 \mathcal{L}_2 的目标是通过将子模块的输出对齐到预训练模型的输出来实现可靠的自集成。该过程可以公式化为:
其中,\tilde{z}_k 表示从子模块中学到的特征,而 z_k 表示从预训练模型中得到的特征。最终损失由这两个损失组成:
其中,\lambda 控制两个损失之间的权衡。训练过程在离线阶段完成,无需在设备上进行额外的训练开销,类似于标准 TTA 设置 [6]。
第一个损失函数是交叉熵,确保每个子模块早退时预测准确。
第二个损失函数类似蒸馏,确保每个子模块输出对齐预训练模型。
(推理方法) 在 TTA 推理阶段,TinyTTA 不使用任何源数据。模型首先计算第一个子模块输出的熵,并将其与预定义的熵阈值进行比较。根据这一比较结果,决定是否继续将特征输出传递到自集成模型的后续子模块。值得注意的是,在训练完成后,只有子模块和早退分支被部署到设备上。部署后,设备上只会更新早期退出分支,而模型的其余部分保持冻结状态,从而确保了高 TTA 准确性和低内存使用。
3.5 TinyTTA 引擎
为了在像 MCU 这样的边缘设备上实现 TTA,作者提出了 TinyTTA 引擎,如图 4 所示。TinyTTA 引擎的流程包含多个步骤:
- 在模型加载后,其前向计算图被构建。
- 在编译阶段,通过算子融合对操作进行优化,同时自动微分(autodiff)过程构建了更新所需的反向计算图。
- 在自动微分之后,反向计算图通过融合和量化程序进一步优化,以缓解执行期间的资源限制。
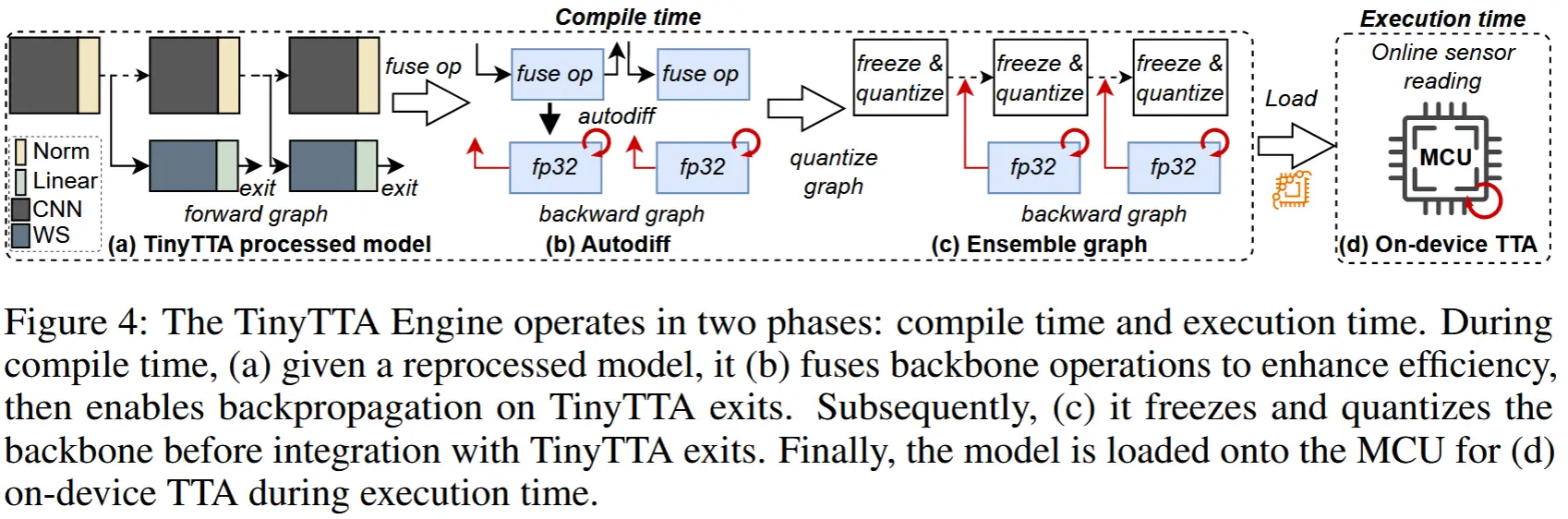
TinyTTA 引擎的核心在于其能够在设备上执行反向传播的能力。作者在广泛使用的 MCU 库 TFLM 的基础上开发了 一个基于浮点运算的反向传播算法 来构建 TinyTTA 引擎。TinyTTA 引擎专门满足了常见深度神经网络(DNN)算子(如 ReLU、全连接层、Softmax、最大池化、平均池化、卷积和深度可分离卷积)的反向计算需求。为了进一步优化内存效率,作者开发了一种逐层更新策略以减少内存使用,并结合利用堆内存的动态内存分配机制。具体来说,基于解释器框架的 TinyTTA 引擎能够通过仅在某一层需要更新时动态选择保存中间激活值来减少内存占用(详见附录)。
4 实验设置
-
分布偏移数据集
- 领域偏移数据集 CIFAR10C [23] 和 CIFAR100C [24]
- 领域泛化数据集 OfficeHome [25] 和 PACS [26]
-
实现细节
- 在 MPU(通过 Raspberry Pi Zero 2W)和 MCU(使用 STM32H747)上进行了实验。
- MPU 上使用三种 SOTA 移动模型:EfficientNet 、MobileNetV2 和 RegNet 。
- MCU 上使用了 SOTA 模型 MCUNet ,这是唯一能够在 MCU 的 512 KB 内存限制下运行的模型。
-
基线方法
- TENT :通过熵最小化优化批量归一化层的仿射参数;
- CoTTA :通过学生模型和教师模型之间的一致性损失更新所有模型参数,并随机恢复预训练模型;
- EATA :一种内存高效的基线方法,采用样本选择标准识别非冗余样本,并通过最小化熵损失更新模型;
- EcoTTA :目前最内存高效的方法,冻结原始网络参数,使用 AdaptBN [30] 归一化层并更新附加的元网络以实现内存高效的测试时间自适应。
-
评估指标
- 准确性、内存使用、延迟和能耗。
5 实验结果
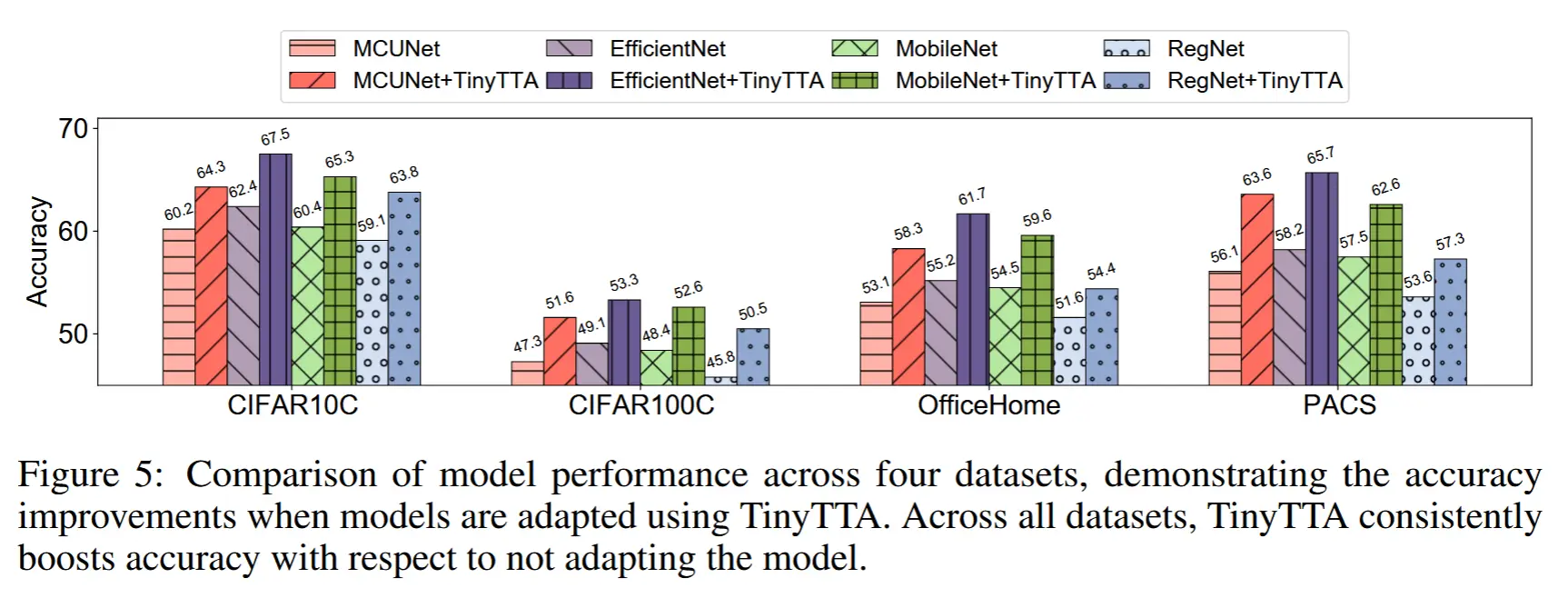
5.1 TinyTTA vs. source model on MPUs
- 如图5 - 准确率
- 注意批次大小为1,小批次设定下大部分TTA方法都会失效。
- TinyTTA 相较于源模型表现显著提升,平均提升 4.3% 的准确率。
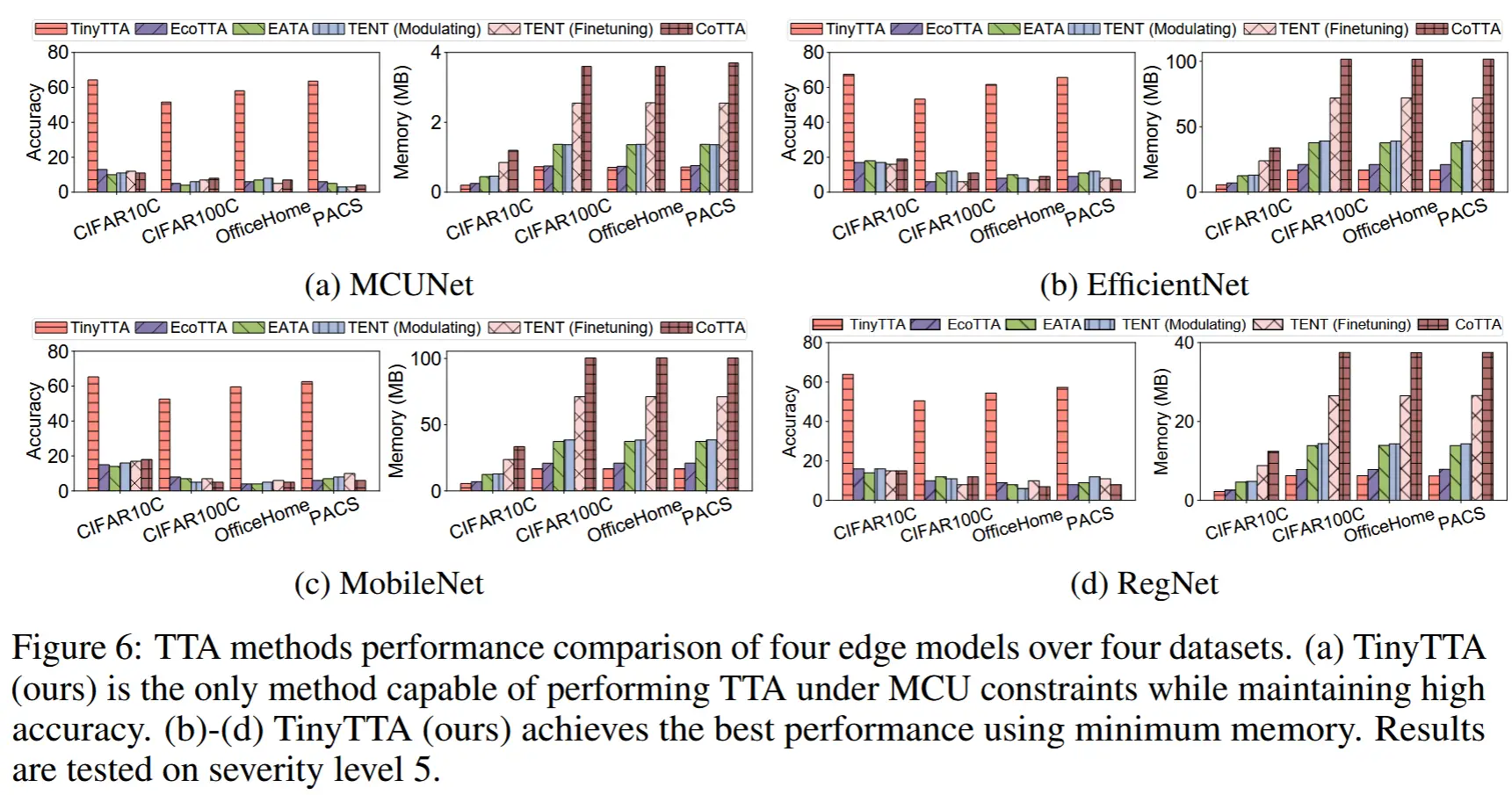
5.2 TinyTTA vs. SOTA on MPUs
- 图6 - 准确率 & 内存
- 将 TinyTTA 与 MPU 上四个不同数据集和四个模型架构中的其他 SOTA 基线进行了比较,批次大小为1。
- 结果非常明显,无论是准确率还是内存使用量,TnyTTA 都取得了最优的性能。
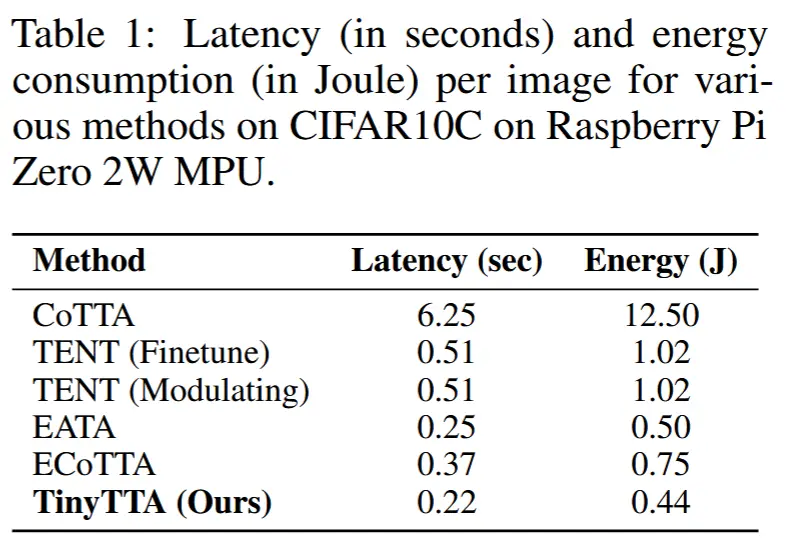
- 表1 - 延迟 & 能耗
- 比较了不同 TTA 方法在 Raspberry Pi Zero 2W MPU 上的延迟和能耗,使用的数据集是包含 50,000 个样本的 CIFAR10C。
- 依旧遥遥领先。
5.3 TinyTTA on MCUs
- 表2 - 准确率 & SRAM & Flash & 延迟
- TinyTTA 在极端资源受限的边缘设备 (512 KB 片上内存 的 MCU)上的性能。
- 实验结论:仅需几十 KB 的额外内存即可实现低延迟和低能耗的设备端自适应。

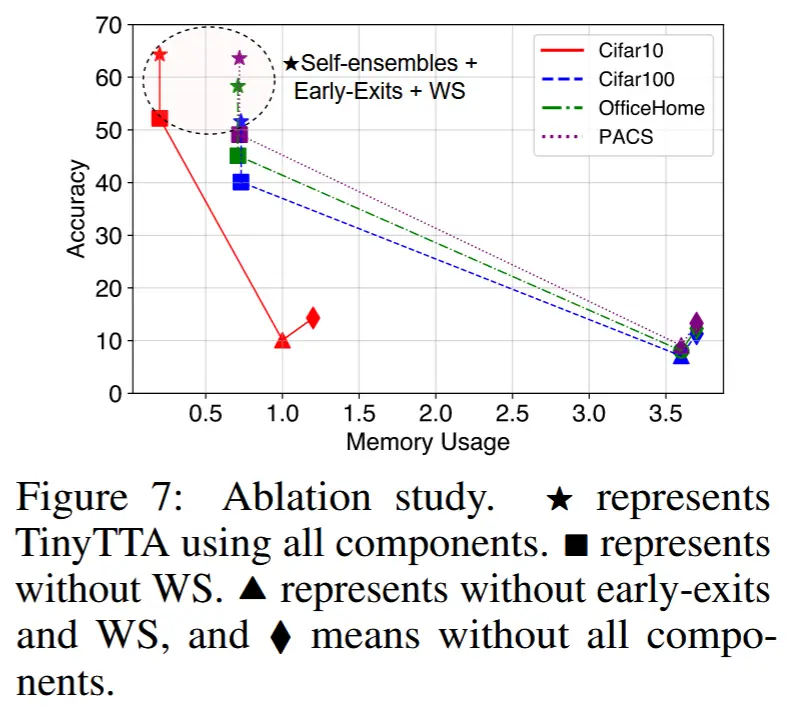
5.4 消融
- 图7
6 总结
本文介绍了 TinyTTA,它首次在 MCU 等资源受限的边缘设备上支持 TTA。通过引入自集成框架、提前退出策略和权重标准化,我们的方法克服了传统 TTA 方法的局限性,在边缘设备上实现了高效且具有竞争力的设备端 TTA。我们还提供了一个新的库 TinyTTA 引擎,以解锁 MCU 上各种应用的 TTA 开发。