- 论文-《Janus: Collaborative Vision Transformer Under Dynamic Network Environment》
- 关键词-多模态、云边协作、模型分割、动态网络、INFOCOM2025
摘要
- 问题背景:ViTs在计算机视觉任务的性能惊人,但是计算成本较高,在资源受限的边缘设备难以使用。常见的方法是对模型进行剪枝或将原始数据通过波动的网络传输到远程云服务器上执行,但是面临性能下降或高延迟的问题。
- 本文解决办法:提出了Janus
- 意义:这是首个针对动态网络环境下低延迟云端协同视觉Transformer推理的框架。
- 优点:Janus克服了ViTs的内在模型限制,实现了在云端和边缘设备上协同执行ViT模型,同时实现了低延迟、高精度和低通信开销。
- 技术:Janus巧妙地结合了 Token剪枝技术与精心设计的细粒度到粗粒度模型划分策略以及非静态混合剪枝策略。 它通过动态选择最佳剪枝级别和划分点,在精度与延迟之间取得了平衡。
- 实验结果:在多种任务中,相较于基线方法,Janus在不同网络环境下可将吞吐量提升至5.15倍,并将延迟违规率降低多达98.7%。
1 介绍
- 计算机视觉模型部署的两种常见选择
- 设备端计算
- 技术:在这种设置下,设备端推理通常涉及对模型的优化。知识蒸馏、剪枝、量化、神经架构搜索 和轻量级网络等技术被广泛研究,以通过更小的模型占用提供有竞争力的服务。
- 局限性:针对边缘设备的模型优化仍然不可避免地会牺牲准确性,并且从根本上受到设备端稀缺资源的限制。
- 远程云服务器上执行
- 由边缘设备采集的数据会被传输到远程云服务器,利用更强的加速器进行推理。
- 局限:这种方法高度依赖于网络状况,并引入了额外的通信延迟。
- 如下图所示。
- 设备端计算

- Janus
- 定义:一种专为ViT模型设计的云端协同推理系统,能够在动态网络环境下实现低延迟、高精度的推理。
- Janus巧妙地整合了 Token剪枝和模型划分技术 ,并通过精心设计的剪枝和划分策略支持云端协作。
- 具体来说,该系统包括一个协作感知的Token剪枝器 和一个 从细粒度到粗粒度的模型划分器 。为了确定最佳的剪枝级别和划分点,作者设计了一个面向ViT的延迟分析器和一个动态调度器。这些组件使Janus能够在动态网络环境中做出高效的配置选择,解决了ViTs带来的独特挑战。
2 背景和动机
2.1 视觉 Transformers
- ViTs 的核心思想
- 将图像的所有块视为“Token”,并在这些块之间构建多头自注意力机制。这种自注意力机制通过计算输入数据的加权和来工作,其中权重基于图像块之间的相似性进行计算。这使得模型能够判断不同图像块的重要性,从而在预测时捕捉更具信息量的表示。
- ViT 模型组成
- Embedding: 输入图像->分割图像块->展平->线性投影生成嵌入->可学习的位置嵌入->完整输入嵌入向量。
- Transformer Encoder: 输入向量->相同数量、相同长度的输出向量。
- Heads:输出向量->任务特定的神经网络->输出标签。
2.2 cloud-only or edge-only?
- 实验拆解ViT推理延迟的来源
- 场景设定:端到端场景、用户在边缘端使用ViTs进行交互,动态多变的网络条件,评估延迟性能。
- 实验设置
- 硬件:边缘端Jetson Orin Nano、云端NVIDIA Tesla V100
- 推理模型:ViT-B
- 网络类型:4G、5G、WiFi(具体网络延迟和吞吐量见论文)
- 结果
- 如图2所示,a 是不同网络的通信延迟, b 是不同平台的计算延迟,c 是总的端到端延迟。
- 结论:在设备资源多样性和网络条件变化的情况下,仅依赖云端或仅依赖设备端的推理无法始终为ViT推理提供最优解决方案。
- 启发:探索一种协同的云端-设备端解决方案,以实现更强的鲁棒性和适应性。

2.3 协同ViT推理的挑战
- CNN 视觉模型
- 对于CNN视觉模型,常常使用 模型划分 的方法来应对协同推理的挑战,这是因为CNN中自然的下采样操作为中间数据尺寸缩减创造了机会,从而在协同推理过程中降低了数据传输延迟。
- 而 ViT 并没有自然的下采样,输出数据的大小保持相对一致,因此,现有的模型划分方法无法直接应用于Transformer架构,因为缺乏显著的数据缩减。
- 启发:传统的模型划分策略无法直接适用。这要求我们探索新的方法,例如结合Token剪枝 和细粒度到粗粒度的模型划分策略 ,以实现数据缩减和通信延迟的优化,从而为ViT提供高效的云端-设备协同推理解决方案。
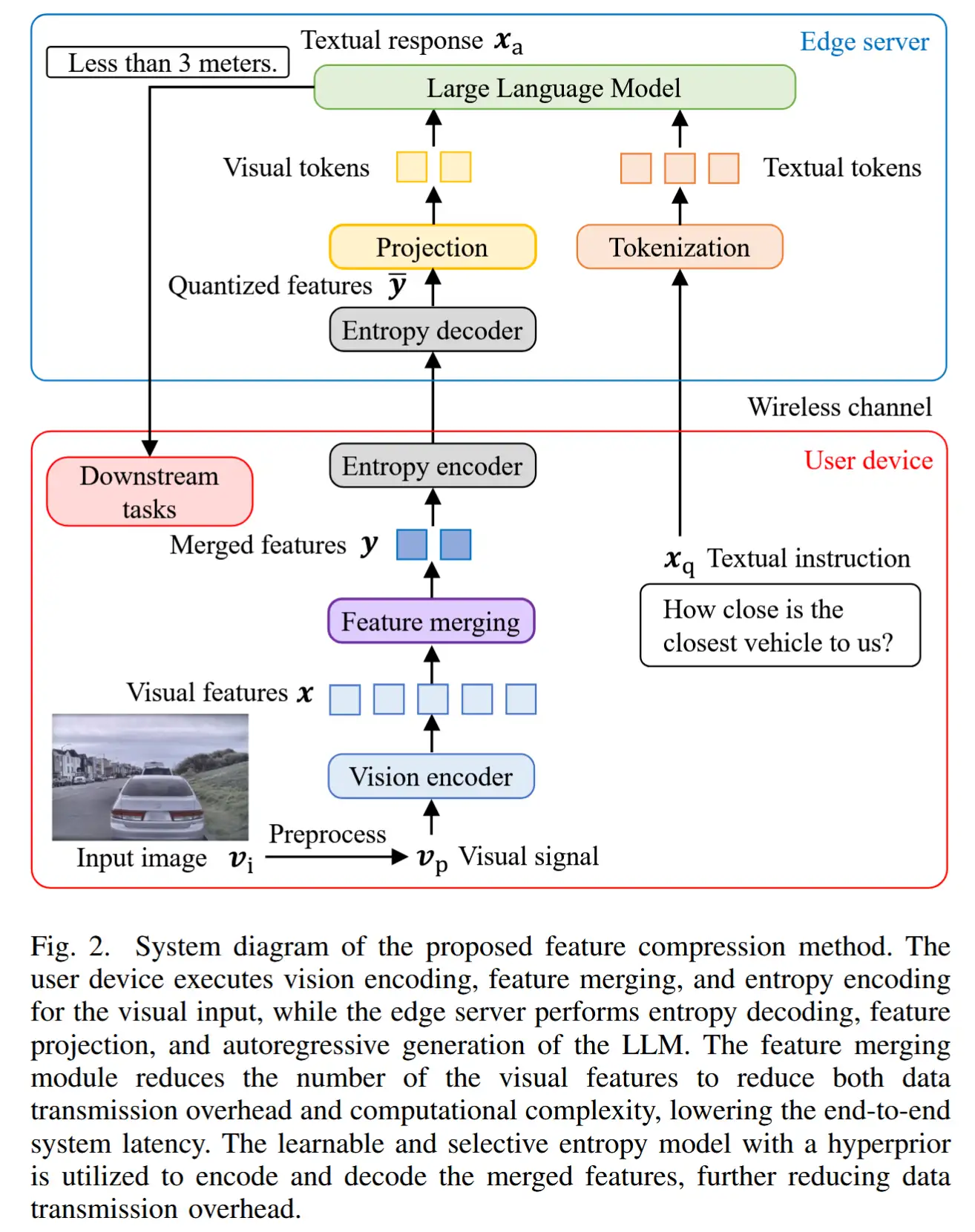
3 系统设计
- Janus系统如图3所示,包括离线阶段和在线阶段
- 离线阶段,部署了一个轻量级线性分析器(§4.3),用于预测在各种条件下的推理延迟。
- 在线阶段,动态调度器(§3.4)实时运行,利用分析所得的洞察信息,根据目标服务级别协议(SLA)对延迟的要求以及网络环境,确定最佳的划分点和剪枝级别。在动态调度器的指导下,协作感知的Token剪枝器(§3.1)与细粒度到粗粒度的模型划分器(§3.2)协同工作,有效地对ViT模型的推理进行剪枝和划分,分布于设备端和云端计算环境中。随后,执行引擎(§4.1)负责协调推理过程并管理分区之间的通信。

3.1 具有混合剪枝策略的协作感知Token剪枝器
- 设计
-
在ViT的不同层之间采用混合剪枝级别。
-
使用“declining rate”这一术语来衡量推理过程中模型中Token被剪枝的 rate,并将其表示为α。对于模型的每一层,剪枝的Token数量随着层数的增加而减少(因为作者认为边缘端激进的剪枝可以减少延迟和计算量,而云端资源充足,更注重准确率)。
-
具体来说,作者采用指数形式来控制Token剪枝的程度。第l层减少的Token数量表示如下:
\Delta x_l = \begin{cases} \lfloor 2\alpha(N-l) \rfloor & \text{if } \alpha \neq 0, \\ 0 & \text{if } \alpha = 0, \end{cases} \tag{1} -
declining rate α 在特定的范围 \alpha \in [0, \alpha_{max}] 内以 t 的增量增加。当 \alpha = 0 时,不进行修剪。\alpha_{max} 的最大值由以下约束条件确定:
\sum_{l=1}^{N} \lfloor 2^{\alpha_{\max}(N-(l-1))} \rfloor \leq x_0 - 1 \tag{2}- 其中 x_0 是模型中Token的初始数量。这确保了Token的累积缩减量不会超过阈值 x_0−1。N 是ViT模型中Transformer层的总数,l \in [1,N] 表示Transformer中的层。
-
declining rate α 使用指数衰减是作者实验的出来的,与线性declining 相比精度损失几乎相同,但是延迟降低更加显著。
3.2 细粒度到粗粒度划分点生成
- 观察
- 延迟的减少主要来自于传输数据量的缩减。
- 在递减剪枝策略中,前部经历了更多的数据缩减,从而显著减少了数据传输延迟,而后部的数据缩减较少,导致数据传输延迟的减少也较小。
- 基于这一关键观察,决定更多地关注前部的层。
- 设计
-
在细粒度到粗粒度划分策略中,模型前部设置更多的候选点,而后部设置较少的候选点。形式上,候选划分点集合 C 被定义为两个集合的并集:
\begin{equation} C = \{0, N+1\} \cup \{ s_i \mid s_i = s_{i-1} + \lceil \frac{i}{k} \rceil, \ s_1 = 1,\ i \geq 2 \text{ and } s_i \leq N \}. \tag{3} \end{equation}- 对于第一个集合,表示 Cloud-only 和 Edge-only 处理。
- 对于第二个集合,该过程从 s_1 = 1 开始,并继续确定候选分割点,直到 s_i 超过 N 。这里,i 是候选分裂点的索引,参数 k 控制它们的数量,k 调节候选分割点之间的间距。
-
图4展示了一个使用12层ViT模型且 k 设置为3的例子,带叉的索引表示在应用划分策略后不再考虑的划分点。
-
这种方法有助于缩小候选划分点的搜索空间,从而减少动态调度器(第3.4节)的执行时间,并最终降低整体系统开销。
-

3.3 轻量级线性分析器
- 鉴于不同划分点和递减率之间的权衡各不相同,需要综合考虑延迟约束、网络条件以及预期延迟,以选择最合适的配置。延迟约束由用户给定,网络条件已被广泛研究,而预期延迟是一个未知问题。
- 观察
- 实验:对不同的ViT模型,随机对ViT的层进行剪枝,并观察每一层Transformer的延迟。
- 图5展示了实验结果,显示了每层不同输入Token数量下的平均层推理延迟。
- 结论:无论是边缘设备还是云服务器,每一层的推理延迟与其输入Token数量之间均呈现出强烈的正线性关系。

- 设计
- 基于上述观察,提出了一种简单但有效的线性模型作为分析器。
- 该分析器采用线性函数作为预测模型,以每层的输入Token数量为输入,并输出预测的推理延迟。
- 优点:符合实际行为模式,减少分析器计算开销,简化了预测模型的生成过程。
3.4 动态调度器
- 静态的token剪枝和模型划分未考虑网络条件的变化,因此设计一个动态的调度器。
- 调度算法如下图
- (2-4行)探索declining rates α。
- (6-7行)利用分析器中的预测模型,算法预测设备端运行 x_l 个 token 的延迟,以及服务器端运行同一层的云端延迟。
- (9行)在当前估计带宽(B)下,根据输入数据大小计算通信延迟。
- (12行)在冷启动期间,使用离线阶段网络带宽的平均值作为粗略估计。随后,算法确定使整体延迟最小的划分点。
- (13-15行)判断确定的划分点是否满足延迟要求。

4 Janus 运行时
本节介绍 Janus 运行时和原型的实现。
4.1 执行引擎
- Janus系统的执行组件由 Jdevice 和 Jcloud 组成
- 在 Jdevice 中,分析器和动态调度器都被部署在设备端。当一个推理任务到达时,系统会读取模型类型和延迟要求,由分析器和调度器给出部署参数,一起传输到 Jcloud 。其产生的中间输出在传输到 Jcloud 之前使用标准的LZW压缩算法进行压缩。
- 在 Jcloud 中,它首先接收关于模型类型、划分点和递减率的信息,并准备定制的云端ViT模型。然后,它接收并解压来自 Jdevice 的中间输出。以该中间结果作为输入,云端模型运行以获得最终的推理结果。
5 评估
实验设计
- 第一个问题 :通过在真实动态网络轨迹上进行模拟实验,测试不同 ViT 推理任务的表现(§5.2)。
- 第二个问题 :通过对网络条件进行敏感性分析来回答(§5.3)。
- 第三个问题 :通过真实部署进行开销分析(§5.4)。
5.1 实验设置
- 视觉数据集和任务
- 帧级图像识别任务 :基于 ImageNet-1k 数据集
- 视频级视频分类任务 :基于 Kinetics-400 数据集
- 视频存储在边缘设备中,并以视频片段(clip)为单位输入系统。
- 采用 Kinetics-400 的推理协议:每段视频采样 10 个片段,每个片段裁剪一次。
- 网络跟踪数据集
- 在5G mmWave uplink performance dataset [22] 进行模拟实验。
- 数据集包含三种测量场景:静态、步行和驾驶,覆盖 5G 和 4G LTE 网络。
- 动态网络条件包括由于遮挡和移动性等挑战场景引起的高波动。
- 模型:对于帧级图像任务实验使用ViT-L@384 [4]、视频级视频分类任务使用Spatiotemporal MAE 中的 ViT-L。
- 基线
- 仅设备端(Device-Only) :所有处理仅在边缘设备上完成。
- 仅云端(Cloud-Only) :所有计算卸载到云端,本地数据通过 LZW 算法压缩后传输到云服务器。
- 混合(Mixed) :根据分析器动态选择“仅设备端”或“仅云端”,以基于动态网络条件最小化预测延迟。
- 对于所有基线方法,应用 SOTA 方法 ToMe [27] 报告的最大固定 Token 剪枝级别:
- ViT-L@384:每层剪枝 23 个 Token。
- Spatiotemporal MAE 的 ViT-L:每层剪枝 65 个 Token。
- 评估 Janus 和基线方法的性能使用以下指标:
- 延迟要求违规率 :未满足延迟约束的推理百分比。
- 推理精度 :正确分类的帧/片段百分比。
- 平均吞吐量 :每秒推理的帧数/片段数(FPS/CPS)。
- 延迟偏差率 :测量延迟与要求延迟之间的百分比差异 max(0, \frac{Latency_{measured} - Latency_{requirement}}{Latency_{requirement}})
5.2 Janus 性能
- 总体性能,图7
- 不同网络场景下SLO违规率和平均吞吐量。

- 理解改进的原因
- 为了理解 Janus 带来这些优势的原因,作者提取了LTE 网络条件下图像识别任务的一个代表性时间段进行进一步说明。
- 上图表示 4G LTE 网络在特定时间段内的带宽轨迹,下图对应网络环境下的吞吐量表现。
- 网络条件很好时(step<12),Janus 选择将所有计算卸载到云端,并且不进行任何剪枝。(在 5G 网络条件下改进较少的原因)
- 带宽较低时(12< step < 24),Janus 通过云端-设备协同推理,在各种网络条件下表现出更稳定的吞吐量。
- 带宽良好时(step > 24),Janus 利用节省下来的延迟,通过使用较小的剪枝级别来维持精度,同时适当在云端和设备之间划分模型。

5.3 敏感性分析
- 图9 (a) 和图9 (c) 展示了在带宽增加的情况下,不同任务的推理延迟变化。
- 图9 (b) 和图9 (d) 提供了动态调度器在这些网络条件下选择的递减率(declining rate)和划分点(split points)的见解。

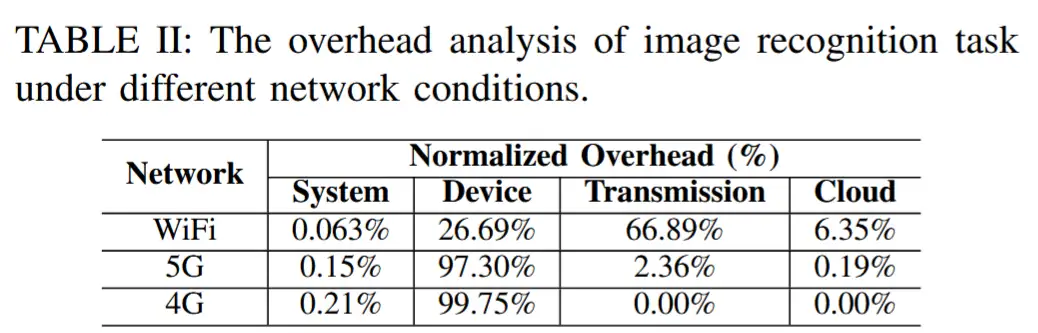
5.4 开销分析
- 作者基于原型系统进行了开销分析。Janus 的端到端(E2E)延迟主要来自四个模块,包括系统开销、数据传输、设备计算和云端计算。这些模块在实际场景中的时间消耗分解如表 II 所示。
6 总结
在本文中,我们介绍了 Janus,这是一种用于动态网络上低延迟 ViT 推理的云设备协作计算系统。Janus 通过创新地调整令牌修剪技术以及精心设计的修剪和模型拆分策略,满足了严格的延迟要求并提供了高精度。该设计完美地捕捉了底层计算基础设施的特征和 ViT 模型的内在属性。此外,作者开发了一个轻量级分析器,可以准确预测各个候选点的计算延迟。利用这一见解以及量身定制的修剪器和拆分器,作者提出了一种高效的调度策略,以实现低计算复杂度的协作推理。基于真实设备和网络场景的广泛评估证明了 Janus 在实现低延迟和保持高精度方面的有效性。相信,Janus 的发展不仅揭示了模型感知视频分析系统的新机遇,而且还对新兴的基于 Transformer 的 AI 应用程序的未来服务堆栈产生了重大影响。