- 论文地址-《From Hours to Minutes: Lossless Acceleration of Ultra Long Sequence Generation up to 100K Tokens》
- 代码地址-GitHub
摘要
- 阻碍LLMs生成超长序列的三个挑战
- 频繁的模型重载、动态的键值(KV)管理以及重复生成。
- 为了解决这些问题,作者提出了 TOKENSWIFT ,一种新颖的框架,旨在显著加速超长序列的生成过程,同时保持目标模型的固有质量。
- 实验效果
- TOKENSWIFT 在不同规模(1.5B、7B、8B、14B)和架构(MHA、GQA)的模型上实现了超过 3倍的加速 。
1 介绍
- 推测解码
- 这种方法采用“先草稿后验证”的策略,在保持无损精度的同时加速生成过程;
- 然而,这些方法通常针对短序列生成进行了优化,例如TriForce和MagicDec分别只能生成256和64个token。如果直接将其生成长度扩展到10万个token,由于键值缓存(KV cache)预算限制,不可避免地会导致失败。
- 此外,即使应用于优化的KV缓存架构(如Group Query Attention, GQA),这些方法对短序列生成的加速效果也仅限于边际增益。
- 研究问题
- 是否有可能在最小化训练开销的前提下,实现类似于短序列推测解码(SDs)的模型无关的无损加速,用于生成超长序列?
- 三个关键挑战:
- 频繁的模型重载 :每次生成token时频繁加载模型会引入显著延迟,这主要是由于内存访问时间而非计算本身造成的。
- 键值缓存(KV Cache)的持续增长 :键值对(KV pairs)随着序列长度的增长而动态扩展,这对维持模型效率增加了复杂性。
- 重复内容生成 :随着序列长度增加,重复生成的问题变得更加明显,导致输出质量下降。
- TOKENSWIFT
- 该框架利用 n-gram检索 和 动态KV缓存更新 来加速超长序列生成。
- 采用 多token生成 和 token重用 的方法,使大型语言模型(即目标模型)能够在单次前向传播中生成多个token,从而缓解频繁模型重载的第一个挑战(第2.2节)。
- 随着生成过程的推进,在每次迭代中动态更新部分KV缓存,减少KV缓存加载时间(第2.3节)。
- 最后,为了减轻重复输出的问题,作者应用 上下文惩罚机制 来约束生成过程,确保输出的多样性(第2.4节)。
2 TOKENSWIFT
2.1 概述
- 整体架构如图所示。
- TOKENSWIFT 使用自草稿(self-drafting)生成一系列草稿token,然后通过基于树结构注意力机制(tree-based attention mechanism)将这些草稿token传递给目标(完整)模型进行验证(更多关于树结构注意力机制的细节请参见附录E)。这一过程确保最终生成的输出与目标模型的预测保持一致,从而有效实现无损加速。
- TOKENSWIFT 不需要单独训练草稿LLM,只需要训练γ个线性层,其中γ + 1表示单次前向传播中预测的logits数量。
- 在验证过程中,一旦从具有完整KV缓存的目标模型中获得目标token,会直接将草稿token与目标token依次比较,以确保整个过程是无损的。
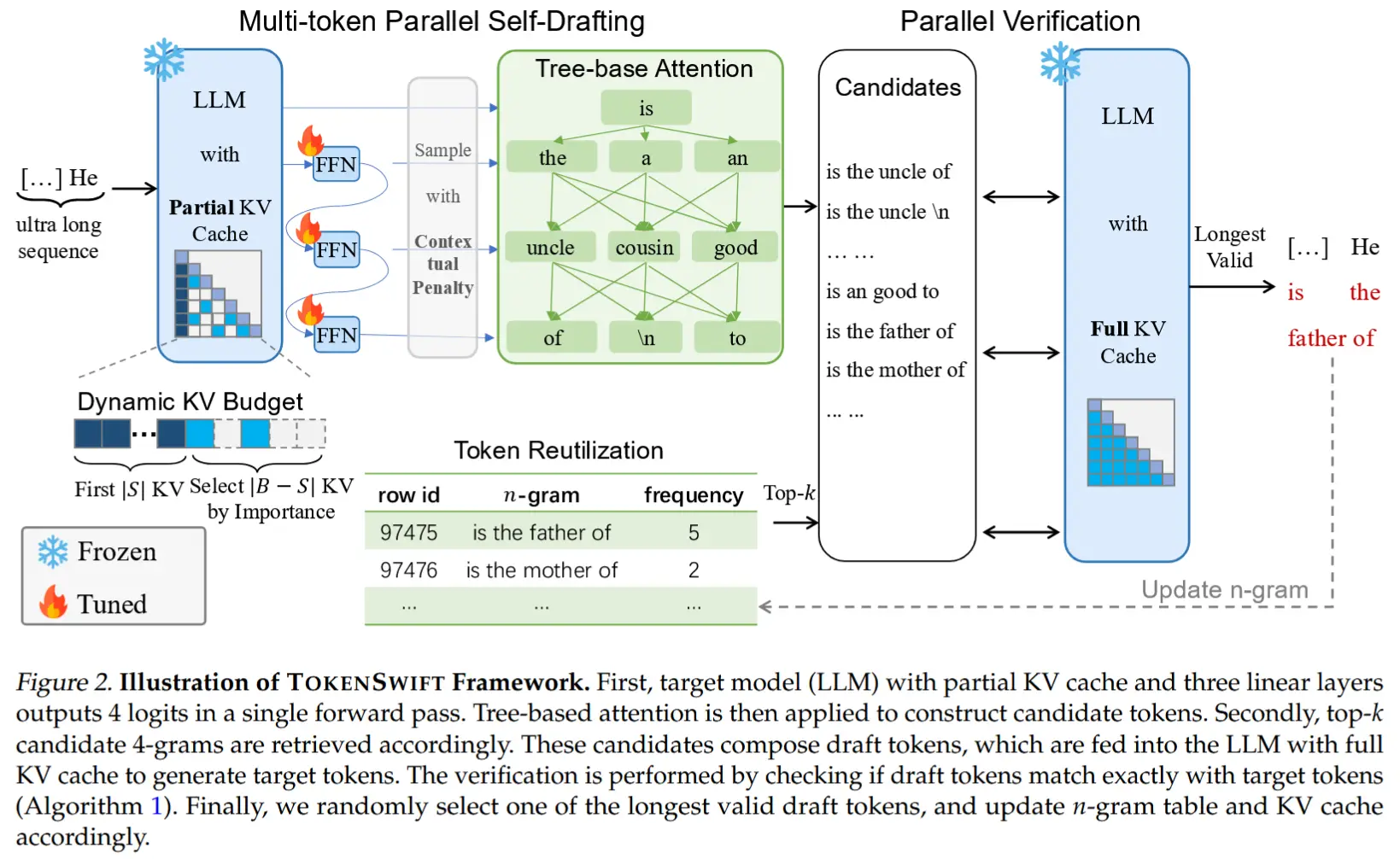
2.2 多token生成 & token再利用
- Multi-token Self-Drafting
- 核心思想:预测头之间引入自回归结构,更符合LLM自回归本质。
- 作者通过引入γ个额外的线性层,使LLM能够在单次前向传播中生成多个草稿token。然而,实验发现,这些额外的线性层之间不应相互独立。
- 具体来说,作者提出了以下结构:
h_1 = f_1(h_0)+h_0,\ \ h_2 = f_2(h_1)+h_1,\ \ h_3 = f_3(h_2)+h_2, \\ l_0, l_1, l_2, l_3 = g(h_0), g(h_1), g(h_2), g(h_3),
- 其中,h_0 表示LLM的最后一个隐藏状态,f_i(·) 表示第i个线性层,h_i 表示第i个隐藏表示,g(·) 表示目标模型的语言模型头(LM Head),l_i 表示输出的logits。
- 这种结构更贴近模型的自回归(AR)本质。此外,这一调整不会带来额外的计算成本。
- Token Reutilization
- 核心思想:维护一个生成文本中频繁出现的短语,作为额外的草稿token。
- 由于使用线性层生成草稿token的接受率相对较低,作者提出了一种名为 token重用(token reutilization) 的方法,以进一步减少模型重载的频率。Token重用背后的思想是,某些短语可能会频繁出现,并且它们很可能在后续生成中再次出现。
- 维护一组元组 \{ (G,F)\} ,其中 G = \{x_{i+1}, ..., x_{i+n}\} 表示一个n-gram,F 表示该n-gram在生成的token序列 S = \{x_0, x_1, ..., x_{t-1}\} 中到时间步 t (t ≥ n) 为止的对应频率。在按照第2.4节所述获得 \{p_0, ..., p_3\} 后,会检索以token argmax p₀ 开头的频率最高的 k 个n-gram,作为额外的草稿token。(时间局部性)
- 尽管这种方法可以应用于具有长前缀的任务,但其效果受到有限解码步数的限制,这减少了接受n-gram候选的机会。
- 此外,由于长前缀文本并非由LLM自身生成,生成文本与真实文本之间存在分布差异。因此,这种方法特别适合用于生成超长序列。(超长序列生成中,前缀文本的影响会逐渐减弱,分布差异的影响减弱)
2.3 动态KV缓存管理
- 基于Xiao等(2024)的研究成果,作者在草稿生成过程中 保留了初始的|S|个键值对(KV pairs)在缓存中,同时逐步淘汰较不重要的KV对。(韩松团队提出的 注意力汇聚attention sink 现象)
-
具体来说,作者设定了一个固定的预算大小|B|,确保在任何给定时间,KV缓存可以表示为:
KV = {(K_0, V_0), ..., (K_{|S|}, V_{|S|}), (K_{|S|+1}, V_{|S|+1}), ..., (K_{|B|-1}, V_{|B|-1})} -
其中前|S|个键值对保持固定不变,而从位置|S|到|B|-1的键值对则按照重要性递减的顺序排列。
-
随着新token的生成,较不重要的KV对会逐渐被替换,替换过程从位置|B|-1的最不重要KV对开始,并逐步向位置|S|推进。一旦替换操作超出了|S|的位置,会重新计算所有先前token的重要性得分,并选择最相关的|B|-|S|个键值对来重建缓存。
-
- KV pairs的重要性得分
-
根据查询(Q)和键(K)之间的点积结果(即 QKᵀ )来计算KV对的重要性得分,并以此对它们进行排序。
-
在 Group Query Attention (GQA) 的情况下,由于每个键(K)对应一组查询 Q = \{Q_0, ..., Q_{g-1}\} ,因此直接计算点积是不可行的。与像 SnapKV (Li等,2024c)这样的方法不同,本文不会复制键(K)。相反,对查询(Q)进行分组处理,如公式(2)所示:
importance \ score_i = \sum^{((i+1)·g)-1}_{j=i·g} Q_j·K_i -
对于位置 i ,组 Q_i 中的每个查询 Q_j 都会与同一个键 K_i 进行点积操作,然后将这些点积结果汇总以获得最终的重要性得分。这种方法在节省内存的同时保留了注意力机制的质量,确保每个查询都能被有效利用,而不会引入不必要的冗余。
-
2.4 上下文惩罚和随机 N-gram 选择
- 上下文惩罚
-
为了减轻生成文本中的重复问题,作者探索了多种采样策略。然而,随着序列长度的显著增加,重复的可能性也显著提高。因此,作者决定对生成的token施加额外的惩罚,以进一步缓解重复问题。
-
具体来说,引入了一个固定大小的惩罚窗口 W ,并对最近生成的 W 个token(截至当前位置生成的token)施加惩罚值 \theta ,如公式所示:
p_i = \frac{exp(l_i / (t·I(l_i)))} {\sum_j exp(l_j / (t·I(l_j))'} \\ I(l) = \theta \ \ if \ l \in W \ \ else \ 1.0, / \theta \in (1,\infty) -
其中 t 表示温度,l_i 和 p_i 表示第 i 个标记的 logit 和概率。
-
核心思想:仅对最近的token施加惩罚,而不是对整个生成历史进行全局惩罚。这种方法能够在抑制重复的同时,保留更多的词汇多样性,从而更好地适应超长序列生成的需求。
-
- 随机n-gram选择
- 在作者的实验中,观察到提供给目标模型进行并行验证的草稿token通常会产生多个有效的组。基于这一观察,作者随机选择一个有效的n-gram作为最终输出。通过利用验证过程中出现的多个有效n-gram,确保最终输出既具有多样性又保持准确性。
- 算法

3 实验
3.1 实验设置
- 模型:括 YaRN-LLaMA2-7b-128k 、LLaMA3.1-8b 和 Qwen2.5-(1.5b,7b,14b)。均使用 Base版本 (非Instruct版本)
- 数据集与训练细节
- 训练数据:使用PG-19数据集,截断超过8K tokens的样本。
- 配置:额外的解码头数量设为3。
- 推理配置
- 单张NVIDIA A100-SXM4-80GB GPU
- 生成长度:100K tokens
- Prompt设置:从PG-19测试集随机样本中选取提示,长度为 2K、4K或8K tokens
- 核心指标
- 接受率
-
定义 :衡量生成过程中被目标模型接受的草稿token比例。
-
计算:
\alpha = \frac{\sum^T_{i=1} a_i}{(\gamma+1)·T'} -
其中 a_i 表示第 i 个时间步接受的 Token 数量,\gamma + 1 表示每个时间步生成的 Draft Token 数量,T 表示时间步的总数。
-
- 加速比
-
定义 :自回归(AR)生成与TOKENSWIFT生成的单token平均延迟比值。
-
计算
x = \frac{latency_{AR}}{latency_{TOKENSWIFT}}
-
- Distinct-n(Li等, 2016)
- 作用 :衡量生成文本的多样性(即重复程度)
- 计算方式 :统计生成文本中不同n-gram的比例,值越高表示重复越少、多样性越好。
- 接受率
- 基线
- TriForce:原始版本采用静态KV缓存更新策略,无法有效加速100K token的生成,引入动态KV缓存更新机制改进。
- Medusa: 结合TOKENSWIFT的验证机制。
3.2 主要结果
- 总体性能
- 基于5次实验的平均值与标准差,实验结果为下面表3和表4。
- TOKENSWIFT 在所有生成长度(20K-100K tokens)和模型架构(MHA、GQA)上均显著优于基线方法。同时,对不同前缀长度(prefill length)的输入表现出稳定的加速效果。
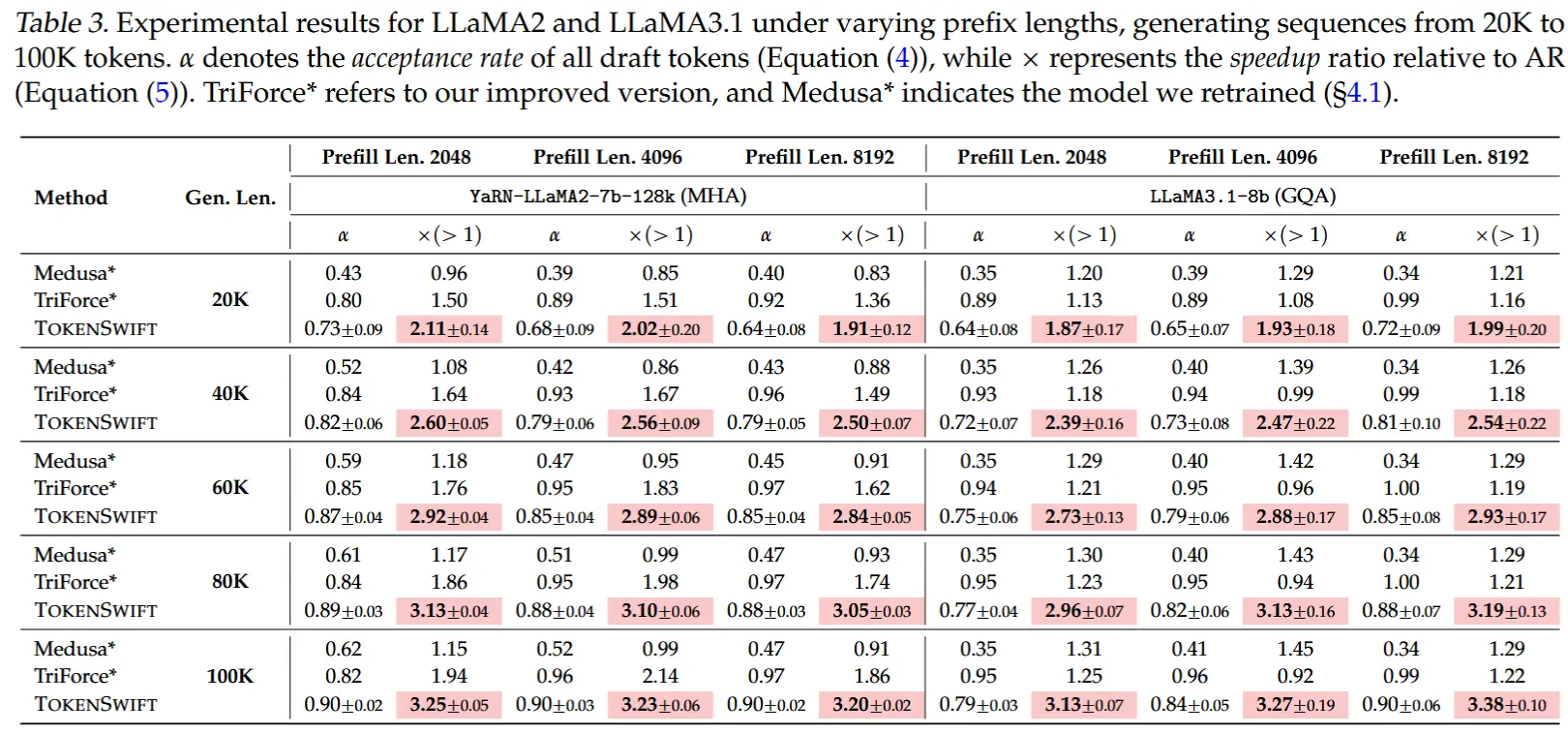
- 生成长度对加速效果的影响
- 趋势 :生成越长,加速比(Speedup)越显著。
- 关键驱动因素
- 动态KV缓存修剪 :自回归(AR)因序列延长导致KV缓存加载时间剧增,而TOKENSWIFT通过动态修剪有效缓解此问题。
- 接受率提升 :随生成长度增加,n-gram候选池扩大,多样性和准确性提高(图3),从而提升草稿token的接受率。
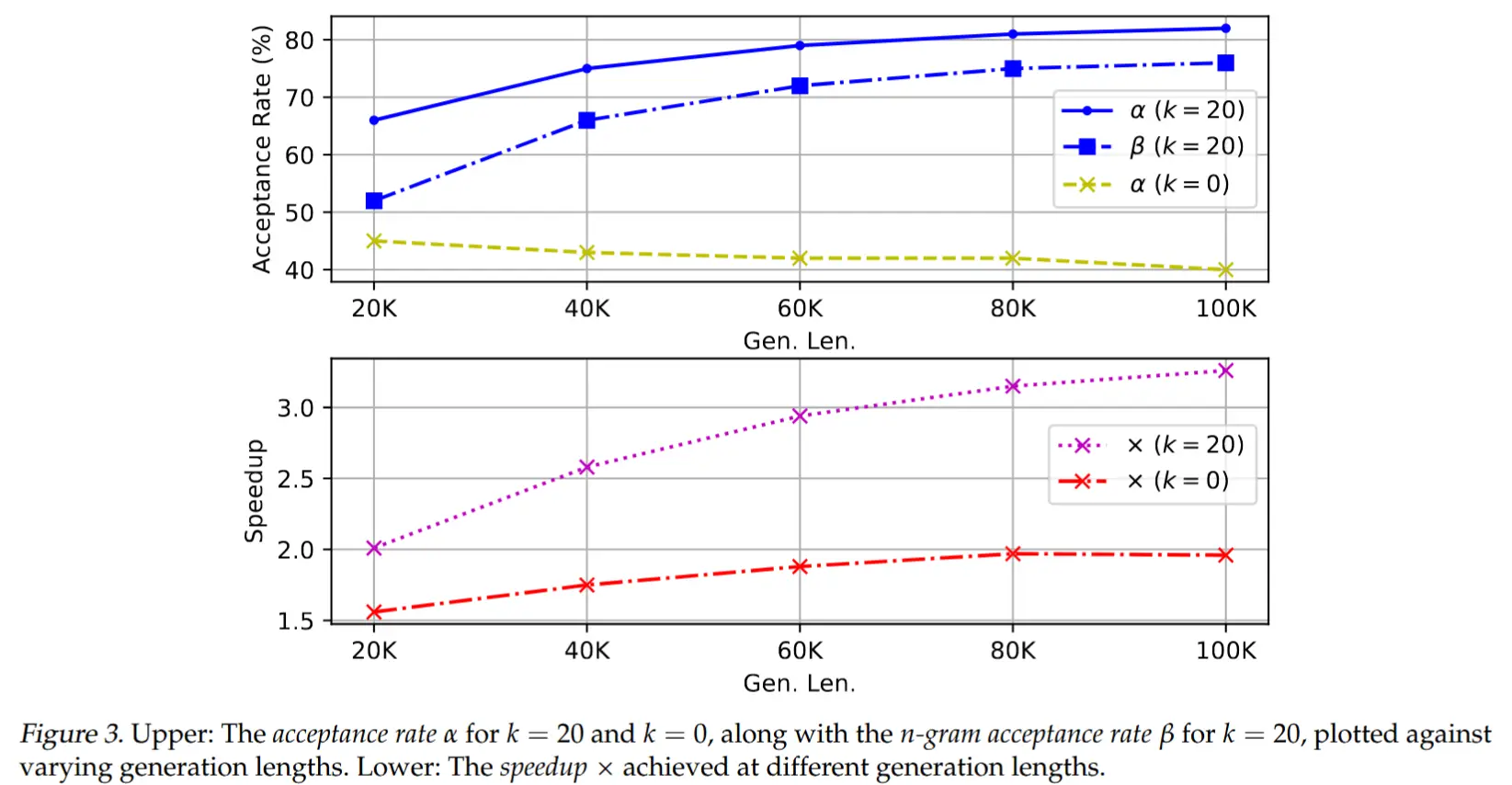
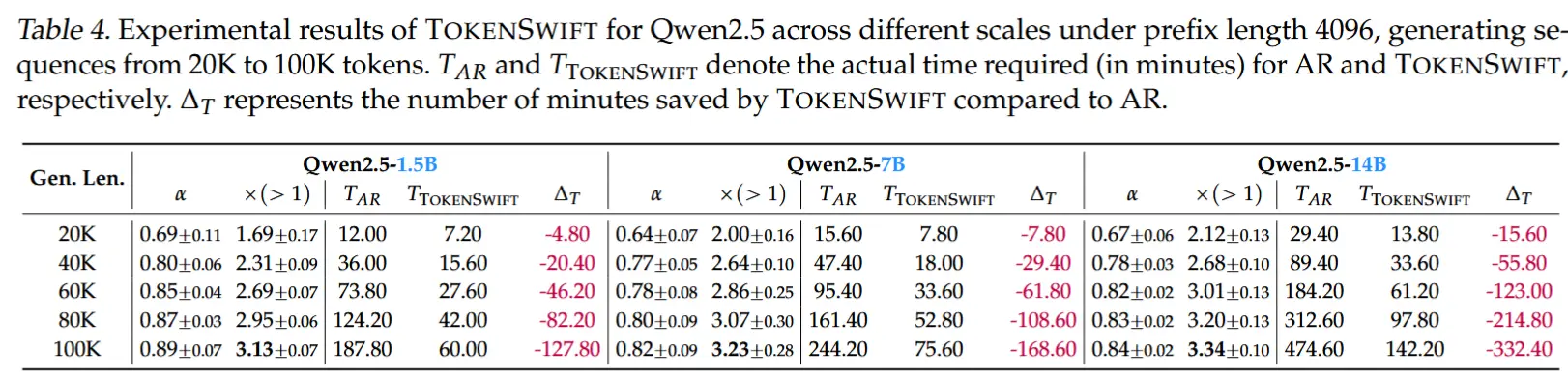
- 模型规模的影响
- 大模型受益更明显 :模型参数量越大,频繁加载模型的延迟越高(如14B模型),TOKENSWIFT的加速优势更显著。
- 跨规模稳定性 :在1.5B、7B、14B等不同规模模型上均保持高效加速(表4)。
3.3 消融实验
略
4 总结
- 问题与挑战 :
- 针对超长序列生成(如10万token)的三大核心挑战:
- 频繁模型重载导致的延迟
- 动态键值(KV)缓存管理复杂度
- 重复内容生成导致的质量下降
- 针对超长序列生成(如10万token)的三大核心挑战:
- 方法创新 :
- 多token生成与重用 :通过自草稿机制(self-drafting)和n-gram检索,减少模型重载频率。
- 动态KV缓存更新 :基于重要性评分的缓存修剪策略,平衡内存效率与生成质量。
- 上下文惩罚机制 :通过局部窗口惩罚抑制重复,提升输出多样性。
- 实验成果 :
- 加速效果 :在LLaMA3.1-8B等模型上实现3倍以上加速 ,将10万token生成时间从5小时缩短至90分钟。
- 跨模型通用性 :支持MHA、GQA等架构,且模型规模越大(如14B),加速收益越显著(节省超5.5小时)。
- 质量保障 :通过严格验证机制确保无损生成,Distinct-n指标显示重复率显著降低。
- 实际意义 :
- 为复杂推理、长文本生成等实际应用提供高效解决方案,突破超长序列生成的算力瓶颈。