- 论文 - 《TEST-TIME ADAPTATION AGAINST MULTI-MODAL RELIABILITY BIAS》
- 代码 - Github
- 关键词 - 多模态、Test-Time Adaptation、音频、视频、ICLR2024
摘要
- 研究背景
- 现有的 TTA 方法主要集中于单模态任务,忽略了多模态场景的复杂性。
- 本文工作
- 深入研究了多模态测试时自适应,并揭示了一个新的挑战,称为可靠性偏差(由于模态内分布偏移而导致的不同模态之间的信息差异)。
- 提出了 REliable fusion and robust ADaptation (READ)。
- 一方面,不同于现有的主要利用归一化层的 TTA 范式,READ 采用了一种新的范式,以自适应的方式调节模态间的注意力,从而支持针对可靠性偏差的可靠融合。
- 另一方面,READ 提出了一种新的目标函数用于鲁棒的多模态自适应,其中高置信度预测的贡献可以被放大,而噪声预测的负面影响得以缓解。
- 此外,作者引入了两个新的基准数据集,以促进在可靠性偏差下的多模态 TTA 的全面评估。
1 引言
- 如图1
- 一旦某些模态受到分布偏移的影响,模态间的信息差异会被放大,从而导致跨模态的可靠性偏差。
- 如图 1(a) 分布偏移:自动驾驶汽车的某些传感器在实际场景中可能会遇到不同情况,导致某些模态的域偏移。
- 如图 1(b) 多模态可靠性偏差:由于分布偏移,一些受干扰的模态会丢失任务特定信息,在跨模态融合中相较于未受干扰的模态会出现可靠性偏差。
- 如图 1(c) 性能下降:受到可靠性偏差影响的视频模态相较于音频模态的识别准确率较低。无论是基于普通注意力的融合(AF)还是后期融合(LF)方式,其预测准确性都低于单模态的结果。相比之下,所提出的自适应注意力融合(SAF)能够实现可靠的融合,从而保证多模态场景下的性能提升。
- 如图 1(d) 不稳定的熵:一旦更具信息量的模态受到干扰,准确预测将变得困难。因此,多模态预测的熵会变得不稳定。换句话说,高置信度预测的比例会下降,而噪声可能会主导预测结果。
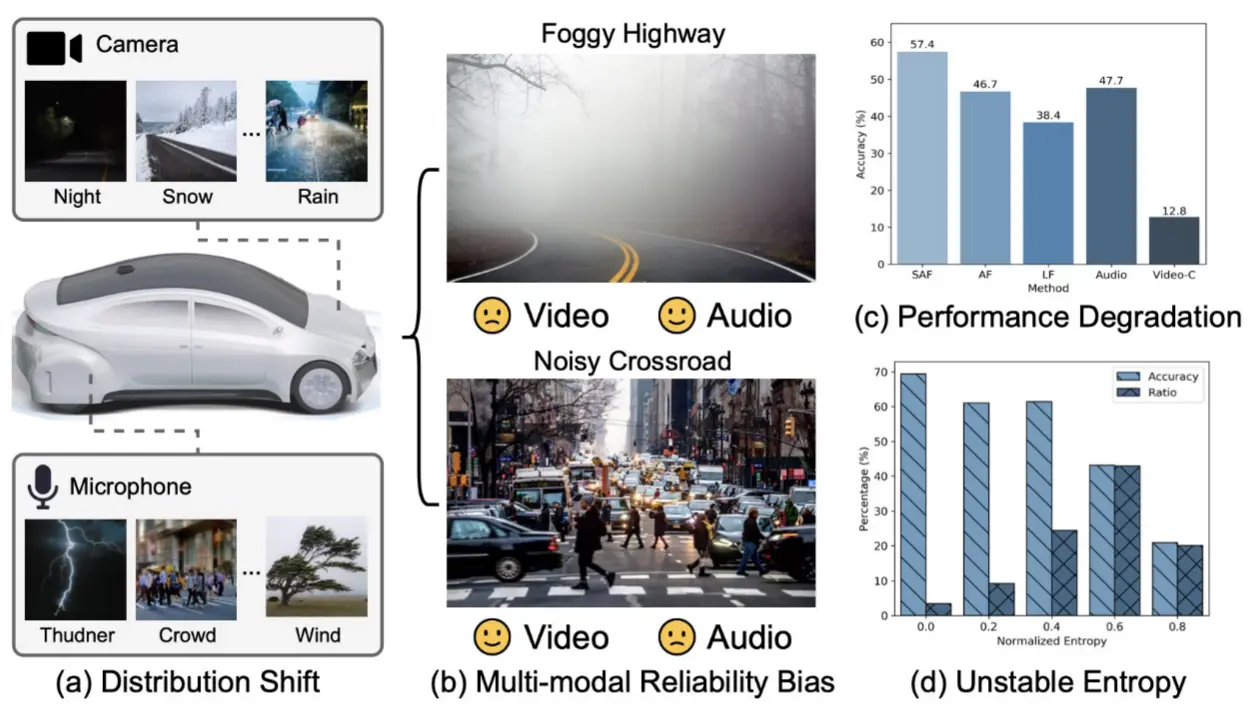
- 可靠性偏差
- 这个概念由本文基于上述观察提出,指的是由模态内分布偏移引发的不同模态间的信息差异。
- 现有的 TTA 方法无法解决问题,原因如下:
- 1)仅通过更新归一化层的参数无法完全调和分布偏移,因此不可避免地会引入跨模态的可靠性偏差。
- 2)如图 1(d) 所示,当代表性模态受到干扰时,噪声预测将主导自适应过程。因此,简单地最小化所有预测或仅高置信度预测的熵可能会导致模型在测试数据上的过拟合或欠拟合。
- 3)后续4.2节实验实证。
- 本文方法 - 可靠融合与鲁棒自适应(READ)
- 通过以下两个模块解决了可靠性偏差的挑战:
- 不同于通过复用归一化层来调和模态内分布偏移,作者提出以自适应方式调节基于注意力的融合层,以在测试时实现可靠的跨模态融合。
- 设计了一个新的目标函数用于鲁棒的多模态自适应。(功能:放大高置信度预测的贡献+防止噪声预测主导自适应过程)
- 通过以下两个模块解决了可靠性偏差的挑战:
2 相关工作
2.1 测试时自适应
- 完全 (fully) 测试时自适应范式,可以分为以下几类:
- 1)在线 TTA 方法,通过一些无监督目标(如预测的熵最小化)利用即将到来的测试样本来更新特定模型参数(通常是归一化层)。
- 2)鲁棒 TTA 方法,考虑了一些具有挑战性和实际意义的自适应设置,例如标签偏移、单样本、混合域偏移等。
- 3)持续 TTA 方法,旨在解决测试过程中持续且变化的分布偏移。
- 4)TTA beyond recognition,专注于图像分类以外的应用,例如多模态分割、姿态估计等。
- 本文聚焦于多模态在线 TTA ,与本文工作最像是 MM-TTA ,但是存在以下区别:
| 差异 | MM-TTA | READ |
|---|---|---|
| 问题/动机 | 协调 2D-3D 联合分割任务的域间分布偏移 | 处理现有研究忽略的模态可靠性偏差挑战音频+动作识别 |
| 方法/范式 | 更新归一化层来实现自适应 | 以自适应方式调节基于注意力的融合层 |
| 目标函数 | 一种基于噪声过滤的交叉熵损失,其伪标签是基于一组慢速-快速模型选择的 | 一种新颖的置信度感知目标函数 |
2.2 不平衡多模态学习
一些近期研究发现,多模态学习可能无法比单模态方法取得更好的性能。问题的本质可以归结为模态之间的差异/不平衡。
- 相关研究
- Wang 观察到不同模态具有不同的收敛速度。基于这一观察,Peng 进行了深入分析,发现某些模态在特定场景下包含更多任务相关的信息,信息量更大的模态可能会主导学习过程,从而在优化过程中如果对各模态平等对待,会阻碍其他模态的拟合。
- Wang 使用辅助网络通过考虑模态的过拟合行为来惩罚模态,从而实现更好的模态融合。
- Peng 设计了一种梯度调制策略,根据模态对网络优化的贡献自适应地调整不同模态的梯度。
- Zhang 从不确定性学习的角度来看,提出了一种具有理论保证的鲁棒多模态融合方法,该方法估计每个模态的确定性,并据此实现加权的跨模态融合。
- 本文聚焦于测试时跨模态的可靠融合,其设置与现有的不平衡多模态学习研究显著不同。具体而言,现有研究主要关注在标记的源域下学习不平衡模态,而本工作旨在利用未标记的多模态测试对在测试时对源模型进行自适应。
3 方法:可靠融合与鲁棒自适应
在本节中,详细阐述了所提出的方法,称为可靠融合与鲁棒自适应(READ),用于多模态测试时自适应以应对可靠性偏差。如图 2 所示,READ 包括一个自适应注意力模块,用于实现不同模态间的可靠融合,以及一个置信度感知的损失函数,用于鲁棒的测试时自适应。
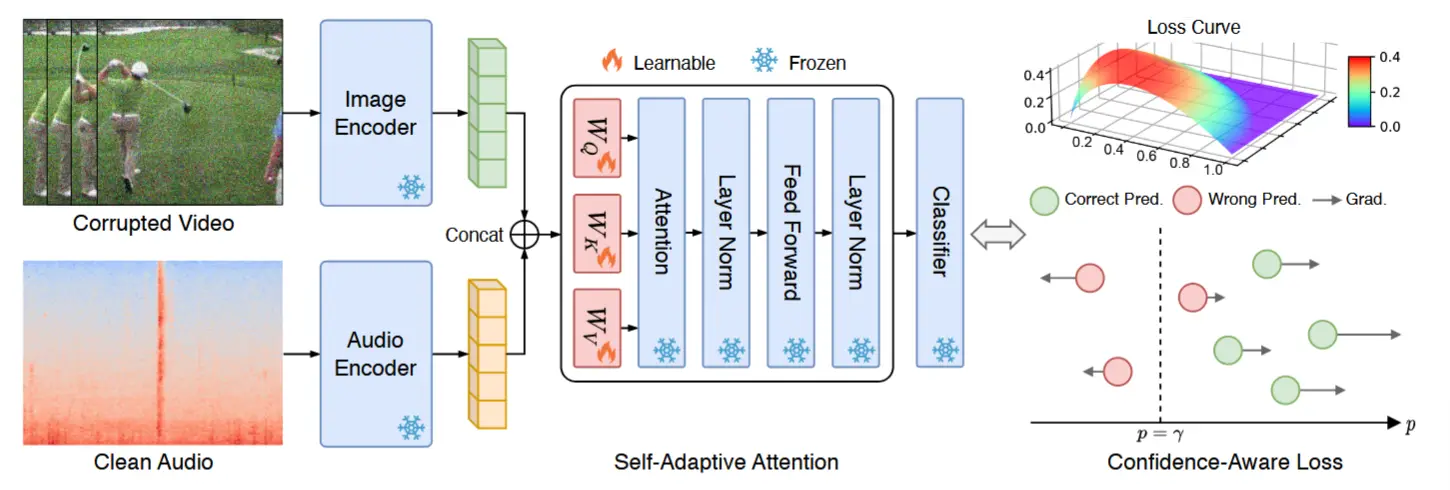
图2为READ的运行流程:
- 在自适应过程中,有偏差的模态(受干扰)和无偏差的模态(干净)被输入到两个特定模态的编码器中,其输出嵌入在标记级别进行拼接以进行融合。
- 在跨模态融合过程中,注意力以自适应的方式在标记嵌入之间计算,并作为融合的可靠性依据。
- 随后,通过分类器对融合后的嵌入进行处理,得到多模态预测结果。
- 置信度感知的损失函数会通过增加梯度来放大高置信度预测的贡献,同时通过反转梯度来减轻低置信度预测的影响。放大的效果和减轻的效果均与预测的置信度成正比。
接下来,分别介绍符号和问题的定义、自适应注意力模块、置信度感知的损失函数。
3.1 符号与问题定义
这里是对 TTA 问题的符号定义,多模态视角。
为了便于表述,以双模态为例进行说明。为清晰起见,用 F_{\Theta_s} = \{f_{\Theta_s}^a, f_{\Theta_s}^v, f_{\Theta_s}^m, C_{\Theta_s}\} 表示在标记训练集 \{s_i^a, s_i^v, y_i\}_{i=1}^{N_s} 上训练的源模型,其中:
- f_{\Theta_s}^a 和 f_{\Theta_s}^v 是分别为模态 a 和 v 设计的 Transformer 编码器;
- f_{\Theta_s}^m 是多模态融合层;
- C_{\Theta_s} 是分类器;
- s_i^h 包含一组标记 \{s_{ij}^h\}_{j=1}^{T_h} \ ( h \in \{a, v\} )。
在训练过程中,源模型 F_{\Theta_s} 会(过度)拟合训练数据的分布,即 P(s) 。因此,在推理/测试阶段,一旦由于天气变化、传感器退化等原因导致分布偏移,F_{\Theta_s} 的性能将大幅下降。换句话说,P(s) \neq P(x) ,其中 x 是未标记的测试多模态数据。
TTA 旨在通过在线更新模型 F 的参数(从 \Theta_s 更新为 \Theta ),快速调和即将到来的测试样本的分布偏移。为此,大多数方法最小化以下目标函数:
其中:
- L_{\text{tta}} 是损失函数;
- \tilde{\Theta} \subseteq \Theta 表示自适应模型 F_\Theta 的可学习参数(通常是 BN 或 LN 层的参数);
- p 是 F_\Theta 对测试时多模态对 (x^a, x^v) 的预测结果,即:p = C_{\Theta_s}(f_{\Theta^m}(z^a, z^v)),
其中 z^a = f_{\Theta_a}(x^a) 和 z^v = f_{\Theta_v}(x^v) 。
在未标记设置下,大多数 TTA 方法通常使用熵最小化目标作为 L_{\text{tta}} 。
3.2 可靠融合
(常用的晚期融合) 为了融合不同模态的信息,一种广泛使用的方法是 晚期融合 (late-fusion-based) 方式。数学上,给定测试时的嵌入 (\mathbf{z}^a, \mathbf{z}^v) ,通过晚期融合获得的多模态预测 \mathbf{p}^\text{lf} 可以表示为:
(不足) 其中, \text{mean} 表示标记级别的均值操作,C_\Theta^a 和 C_\Theta^v 是两个模态特定的分类器。显然,晚期融合方式无论模态是否可靠,都会平等地对待每个模态,对可靠性偏差问题非常敏感。
(改进-自适应注意力)因此,作者提出了自适应注意力模块,用于动态整合来自不同模态的信息。具体而言,首先在标记级别将模态特定的嵌入 \mathbf{z}^a 和 \mathbf{z}^v 拼接起来,然后投影到查询、键和值矩阵中。形式上,
其中,W_{\Theta_h} 和 B_{\Theta_h} ( h \in \{Q, K, V\} )是从源模型继承并在测试时更新的投影矩阵和偏置项,而 [\cdot; \cdot] 表示标记级别的拼接操作。之后,注意力图可以计算如下:
其中,\mathbf{A}_{r,t} 的单元表示 z^h ( h \in \{a,v\} ) 中第 r 个标记与第 t 个标记之间的相似度值,而 d 是标记的潜在维度。
注意:原始的注意力机制通常保留从源模型继承的参数,并在模态之间执行信息整合。而本文以自适应的方式重新利用跨模态注意力融合层。换句话说,W_{\Theta_h} 和 B_{\Theta_h} ( h \in \{Q, K, V\} ) 的参数将被更新,以便适应测试时的分布。得益于注意力调节,模型会更多地关注无偏差的模态,从而在测试时实现可靠的跨模态融合。
(预测) 最后,通过自适应注意力融合层获得的预测可以表示为:
3.3 鲁棒自适应
(问题) 解决了可靠性偏差的跨模态融合,接着考虑 分布偏移的鲁棒自适应。
(常见方案-熵最小化) 一种可行的解决方案是采用广泛使用的熵最小化目标,要么应用于所有预测,要么仅应用于高置信度的预测。
(多模态场景下的新挑战) 正如引言中讨论的那样,一旦某些信息量大的模态受到干扰,整体的任务相关信息会大幅减少,预测准确性可能会下降。此时,无论是原始的熵最小化目标还是噪声过滤目标,都会对噪声预测过拟合或对干净预测欠拟合,从而导致自适应效果下降。
(提出解决办法) 作为一种补救措施,作者提出了一种 新的置信度感知损失函数,用于鲁棒自适应。形式上,给定一个大小为 B 的小批量测试预测,损失函数设计如下:
其中, p_i 是预测 \mathbf{p}_i^\text{saf} 的置信度,即 p_i = \max \left( \delta \left( \mathbf{p}_i^\text{saf} \right) \right) , \delta 是 softmax 操作,而 \gamma 是在所有实验中固定的置信预测划分阈值。
作者从数学上证明了为什么该损失函数能够实现鲁棒自适应,此处省略。
(优势) 得益于 \mathcal{L}_{ra} 的有利性质,鲁棒自适应得以实现。一方面,模型不会对低置信度预测过拟合,从而防止噪声主导自适应过程。另一方面,模型会更多地关注高置信度预测,从而有益于优化。
(最终目标函数) 结合自适应注意力模块和置信度感知损失函数,可以得到多模态测试时自适应的最终目标函数如下:
其中,\widehat{\Theta} = \{\Theta^Q, \Theta^K, \Theta^V\} \subseteq \Theta , \mathcal{L} = \mathcal{L}_{ra} + \mathcal{L}_{bal} ,并且 \mathcal{L}_{bal} = \sum_{k=1}^K \delta \left( c^k \right) \log \delta \left( c^k \right) 是一个负熵损失项,用于使预测平衡,类似于 Yu 等(2023b)和 Zhou 等(2023),其中 c^k = \sum_{i=1}^B \delta \left( \mathbf{p}_i^\text{saf} \right) , K 是类别数。
4 实验
4.1 实验设置
-
基准构建:
- 基于 Kinetics 和 VGGSound 构建了 Kinetics50-C 和 VGGSound-C,参考前人为视频模态引入15种干扰,为音频模态引入6种干扰,5个严重程度级别。
-
预训练模型选择:
- 选择了 CAV-MAE 作为骨干网络。
- 在 Kinetics50 和 VGGSound 数据集的训练集上微调 CAV-MAE,得到相应的源模型。
- 注意:Kinetics50 和 VGGSound 的训练集是源域,而 Kinetics50-C 和 VGGSound-C 是目标域。
-
测试时自适应过程:
- 在测试时自适应阶段,READ 使用 Adam 优化器在线更新源模型的特定参数。
- 初始学习率为 0.0001,每个 mini-batch 大小为 64,单个 epoch 内完成更新。
- 置信度阈值 \gamma 在公式 (6) 中固定为 e^{-1} 。
4.2 与 SOTA 比较
- SOTA : Tent、MMT、EATA、SAR
- 表1:Kinetics50-C 视频模态损坏(严重性级别 5)
- “Stat.”是“Statical” ;Dyn.”是“Dynamic”;
- “LN”、“LF”、“AF” 和 “SAF” 分别表示层归一化、晚期融合、基于注意力的融合 和 基于注意力的自适应融合。

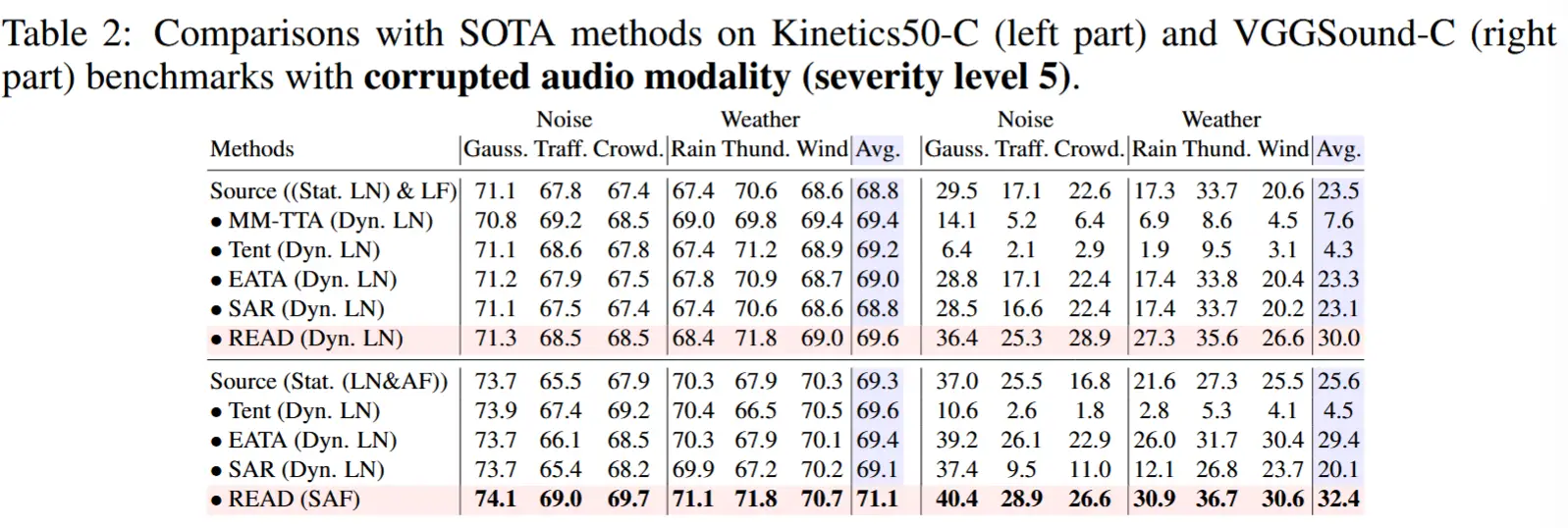
- 表2:Kinetics50-C(左)和 VGGSound-C(右)音频模态损坏(严重性级别5)
- 表3:VGGSound-C 视频模态损坏(严重性级别 5)
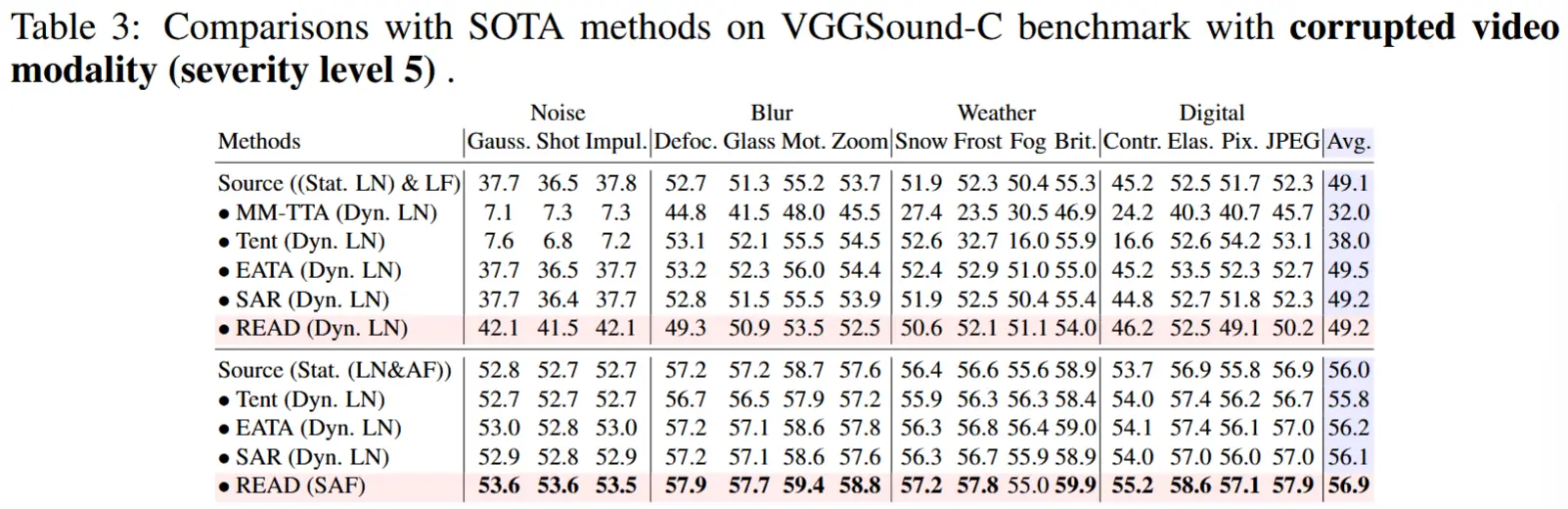
实验结论:
-
晚期融合对可靠性偏差最敏感:
- 可能是由于对每个模态的平等对待。
-
基于注意力的融合提升了鲁棒性:
- 与晚期融合相比,基于注意力的融合能够提升对可靠性偏差的鲁棒性。
- 然而,使用普通注意力融合的 TTA 方法在某些情况下仅能带来微小的性能提升,这表明仅靠更新归一化层参数的广泛使用的 TTA 范式无法简单解决可靠性偏差问题。
-
置信度感知损失的贡献:
- 提出的置信度感知损失函数能够为晚期融合和基于注意力的融合都带来性能提升。
- 结合提出的 SAF(自适应注意力融合)策略和该损失函数,可以确保抗噪能力,从而学习可靠的注意力用于融合。
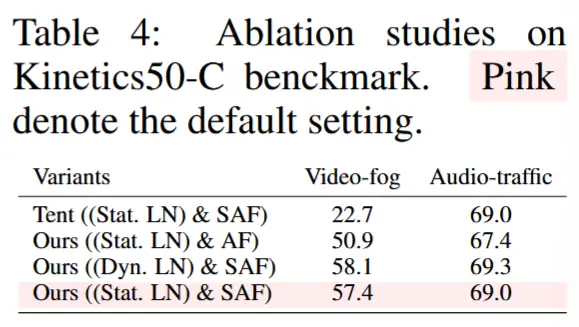
4.3 消融实验
在本节中,所有实验均在 Kinetics50 数据集上进行,除非另有说明,否则视频模态会受到雾噪声干扰(严重程度为 5),音频模态会受到交通噪声干扰(严重程度为 5)。
- 消融研究 - 表 4
- 使用 SAF 的 Tent 并不能始终提升鲁棒性,归因于多模态 TTA 中噪声主导的预测问题。
- 提出的损失函数能够提升现有主要更新归一化层的 TTA 范式的鲁棒性。
- 将归一化层更新机制应用于 SAF 可以略微提升性能
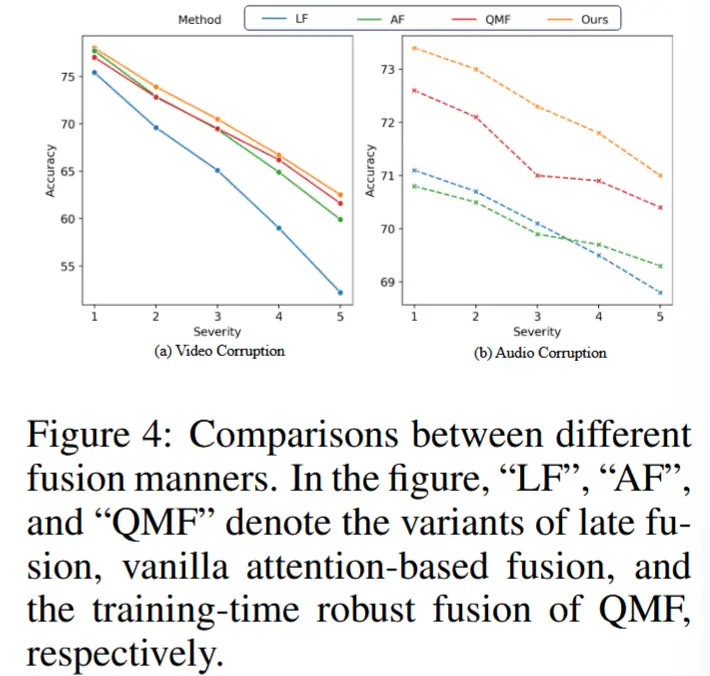
- 测试时可靠融合的优越性 - 图 4
- QMF是最近的 SOTA 方法,通过采用精心设计的训练流程估计每个模态的置信度,这种范式自然可以用于处理可靠性偏差。
- 本文方法在音频和视频模态上都比 QMF 更具鲁棒性,尽管后者改变了源域的训练过程。
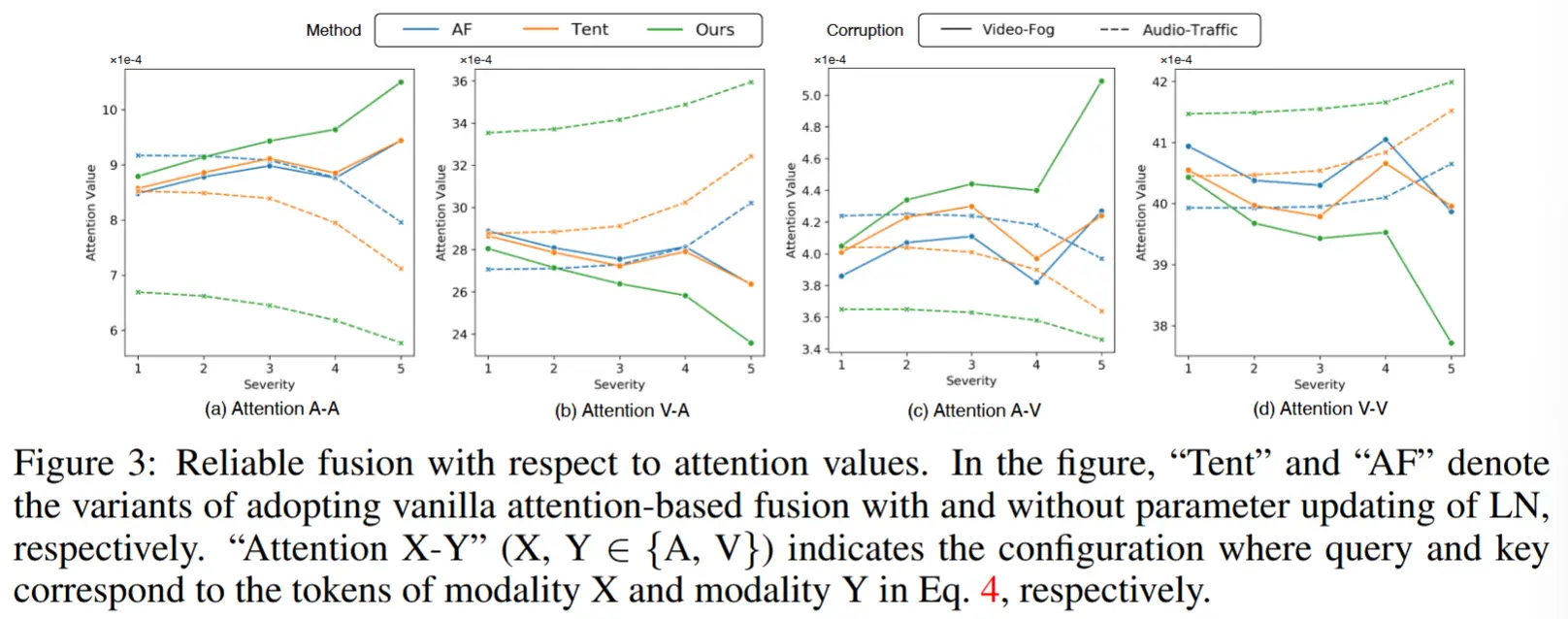
- 不同情况下的可靠融合 - 图 3
- Tent”相比“AF”能实现稍微稳健的融合效果,这可能归因于重新利用 LN 缩小了领域间隙。
- READ 方法在视频或音频偏置情况下(不同严重程度)的可靠性估计(注意力值)上表现出显著改进,这验证了自适应注意力融合范式在多模态 TTA 中的必要性。
- (图中的“Attention X-Y”表示 query 和 key 分别对应模态 X 和模态 Y 的标记)
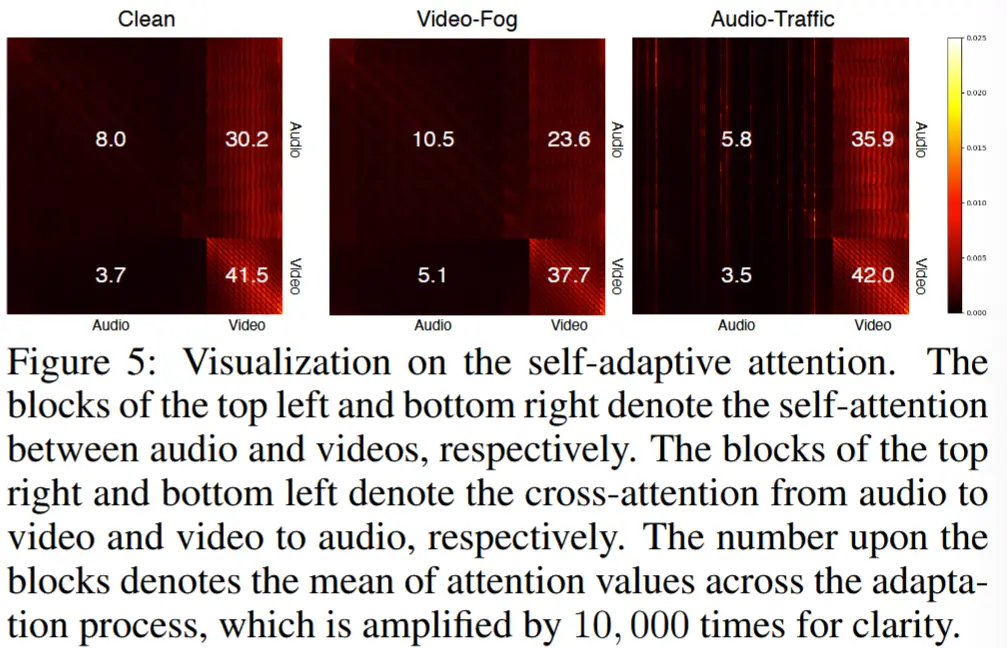
- 自适应注意力的可视化 - 图 5
- 验证 SAF 模块的有效性。
- 在适应干净/几乎无分布偏移的测试数据时,SAF 能够维持音频和视频模态之间的重要性平衡(8.0 vs. 41.5)。(在动作识别任务中,视频对于 Kinetics50 更具信息量)
- 一旦某个模态受到干扰,SAF 能够使模型更多地关注另一个较为可靠的模态,例如从 8.0 提升到 10.5。同时,干净的模态会减少对受损模态的关注,而受损模态则会增加对干净模态的关注,例如从 30.2 减少到 23.6,以及从 3.7 增加到 5.1。
5 结论
在本文中,我们正式研究了多模态测试时适应。通过深入研究多模态情景中的分布偏移,我们揭示了模态内分布偏移将导致模态之间的信息差异,即模态可靠性偏差挑战。为了应对这一挑战,READ 采用自适应注意力模块实现不同模态之间的可靠融合,并采用置信度感知损失函数实现稳健适应。为了进行综合评估,我们提供了两个具有多模态可靠性偏差的新基准。未来,我们计划探索不同应用和场景下具有可靠性偏差的多模态 TTA 的更具体问题。