- 论文-《Cross-Device Collaborative Test-Time Adaptation》
- 代码-Github
- 关键词-test-time Adaptation、开源、视觉、Neurips 2024
摘要
- 本文工作 - test-time Collaborative Lifelong Adaptation (CoLA)
- 这是一种通用范式,可以与现有的先进TTA方法结合使用,以多设备协作的方式提升适应性能和效率。具体来说,CoLA 维护并存储一组设备共享的领域知识向量,这些向量累积了所有设备在其终身适应过程中学到的知识。
- 基于此,CoLA针对具有不同计算资源和延迟需求的设备实施两种协作策略:
- 1)知识重编程学习策略(Knowledge reprogramming learning strategy)联合学习新的领域特定模型参数和一个重加权项,以重新编程现有的共享领域知识向量,称为主代理上的适应。
- 2)基于相似性的知识聚合策略 仅根据领域相似性以无优化的方式聚合存储在共享领域向量中的知识,称为从代理上的适应。
- 实验效果
- 实验验证了CoLA简单但有效,不仅提升了TTA的效率,还在协作、终身和单领域TTA场景中表现出显著的优势。
- 例如,在从代理上,CoLA在ImageNet-C数据集上将准确率提高了30%以上,同时保持了与标准推理几乎相同的效率。
1 引言
- 测试时适应 TTA 介绍
- TTA 的出现是为了解决域偏移问题,即在模型部署后遇到的测试样本与训练域不同的情况。
- TTA 通常使用自监督或无监督目标(如旋转预测 [13]、对比学习 [2, 30, 50]、熵最小化 [54, 64, 25, 37] 等)针对测试样本更新给定模型。
- 与传统的域适应或微调方法相比,这些方法需要对整个预先收集的目标数据集进行离线模型学习,而 TTA 则通过仅利用每个测试样本一次进行即时后推理适应。(开销小、更具适应性)
- 先前的 TTA 方法局限性
- 先前的 TTA 方法主要是在单设备上,而实践中通常部署在多个设备上。
- 1)单设备 TTA 忽略了从其他设备中学到的有用知识,并独立进行适应。由于不同设备可能经常遇到相似甚至相同的测试域,忽略这些共享知识往往会导致次优的适应性能。
- 2)由于资源有限或延迟需求,某些设备可能不支持基于学习的 TTA 方法所需的反向传播操作,使得单设备 TTA 不可行。
- 3)即使在单个设备上,模型 也可能遇到动态且周期性变化的域偏移。尽管最近的工作提出了持续 TTA 来缓解灾难性遗忘问题,例如抗遗忘正则化器 [38] 或恢复机制 [56],但这些方法仍然难以在长期适应过程中积累之前学到的知识。
- 后续实验环节验证局限性。
- 本文 CoLA 方法
- CoLA 方法利用了来自其他设备以及设备自身的先前学到的知识,从而实现高效且协作的TTA。(跨设备)
- 领域向量:表示每个设备在每个领域上学到的知识,并在其持续适应过程中自动检测领域变化,在设备之间共享,用于协作TTA和缓解灾难性遗忘。
- 知识重编程学习:针对资源充足的设备(即主代理),通过 利用可用的共享知识 来提升TTA性能和效率,同时 在现有知识不足的情况下学习新的领域特定参数。新学到的参数/知识随后被存储以更新共享领域向量集。
- 无优化的协作 TTA :针对资源受限设备,根据领域相似性直接聚合主代理共享的领域知识,避免额外计算开销。
2 问题描述和动机
-
设 f_\theta(·) 为在标注数据集 D_{\text{train}} = \{(x_i, y_i)\} 上训练的模型,且 x_i \sim P(x) 。训练完成后部署到设备上,可能遇到来自偏移且动态变化的领域分布 Q(x) ,导致严重的性能下降。为了解决这个问题,可以通过在测试时优化某些自监督或无监督学习目标来适应 f_\theta(·) 对 x 的表现:
\min_{\theta_l} L(x; \theta_f, \theta_l), \quad x \sim Q(x), \quad (1)- 其中 \theta_f 和 \theta_l 分别表示冻结参数和可学习模型参数。
-
动机
- 公式 (1) 被称为单设备测试时适应(TTA)方法,它简单地在每个设备上从头重新适应 f_\theta(·) 。
- 在多设备适应场景中,这种独立适应方式忽略了从其他设备中学到的宝贵知识,往往导致有限的性能表现。
- 因此,迫切需要设计多设备协作的 TTA 方法,关键技术挑战在于协作+有效利用来自其他设备的知识+隐私保护+通信效率。
-
领域知识向量
- 灵感来源:模型部署环境可能是周期性的,或者其他设备先前见过的,此时利用先前知识显然更高效。
- 方法:试图显式存储每个设备在每个领域上学到的知识,并利用这些知识进行协作TTA,将这种知识称为领域向量。
- 定义
- 给定 m 个设备,每个设备有 n 个领域,使用一个领域向量 \Delta\theta_{i,j} = \theta_{i,j}^l - \theta_o^l 来表示第 j 个设备在第 i 个领域上学到的知识。这里, \theta_{i,j}^l 表示第 j 个设备在第 i 个领域上学到的参数, \theta_o^l 表示对应的原始可学习参数。
- 选择归一化层的仿射参数作为可学习参数 \theta_l ,并在设备之间传输领域向量以实现知识共享。
- 将每个知识向量 \Delta\theta_{i,j} 存储在一个集合 T = \{\Delta\theta_{i,j}\}_{i=1,j=1}^{n,m} 中。在持续适应过程中,一旦学到了新的 \Delta\theta_{i,j} ,就通过将其存储到 T 。
- 为了简化表述,将 T 表示为 \{\Delta\theta_i\}_{i=1}^N,其中 N = mn ,并在以下章节中利用 T 设计协作TTA策略。
3 跨设备协作测试时适应
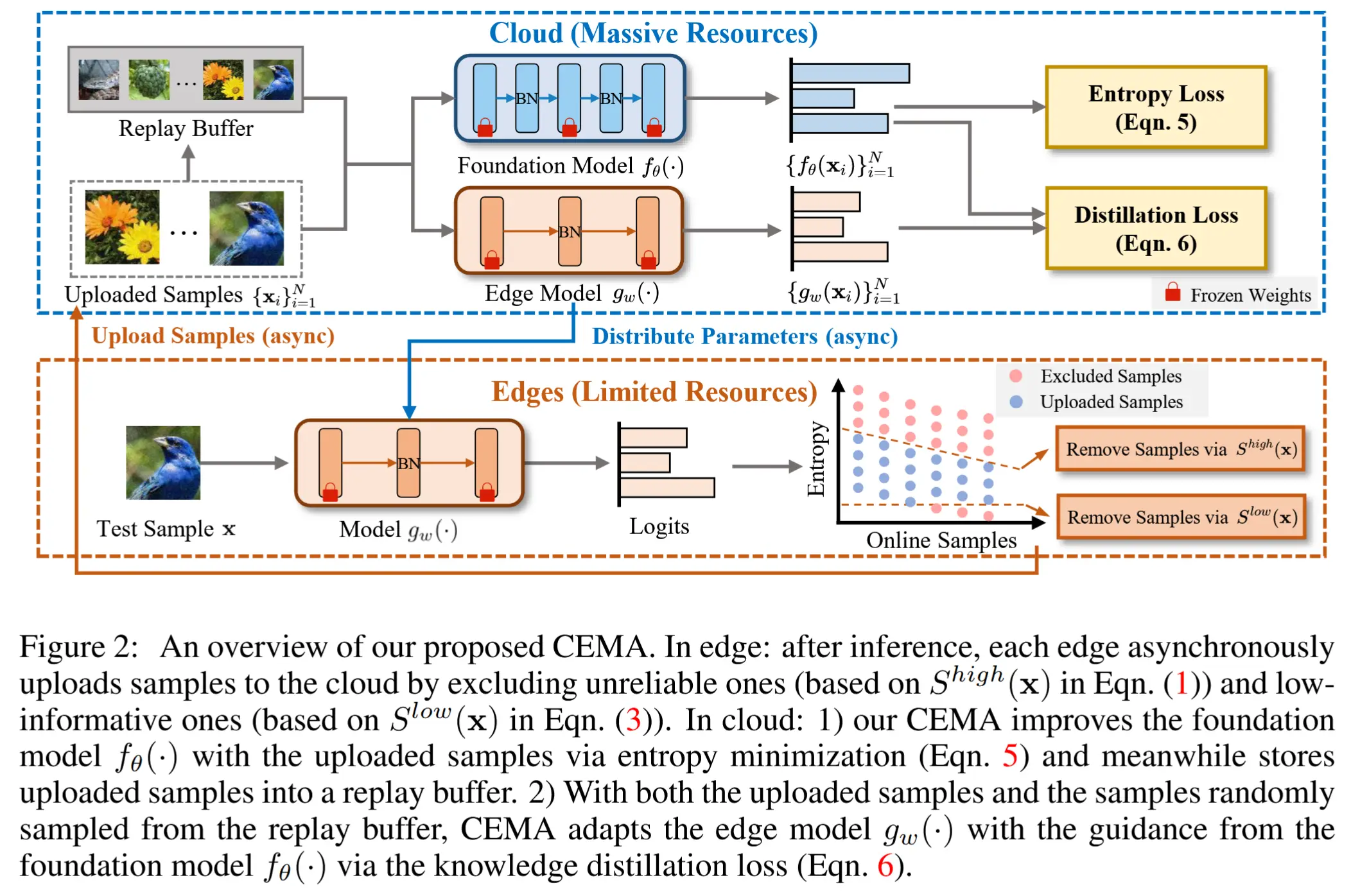
- CoLA的整体流程 - 图2
- 核心就是一组共享的领域向量 T ,在持续适应过程中自动检测每个设备的领域变化并显式的存储变化。
- 基于 T ,有两种不同的协作策略,根据计算资源或延迟需求来决定使用哪种。
- 1)协作知识重编程学习策略,专为“主代理”设计,即那些主导新知识学习并拥有足够资源进行基于反向传播模型更新的设备。该策略通过基于反向传播的优化,联合学习新的领域特定模型参数和一个重加权项,以重新编程从设备自身和其他设备先前遇到的分布中学到的知识。
- 2)无优化的协作TTA,专为“从代理”设计,即那些资源受限或对延迟敏感的设备。该策略主要利用来自主代理共享的知识,通过根据分布相似性聚合有价值的共享知识。


3.1 知识重编程学习
-
假设存在 N 组参数(即先前学到的领域向量),记为 T = \{\Delta\theta_i\}_{i=1}^N ,其中 \Delta\theta_i = \theta_i - \theta_o^l 。基于 T ,学习一个重加权项,通过反向传播自适应地聚合共享知识,同时在现有知识不足的情况下学习新知识。整体优化问题如下:
\min_{\alpha, \Delta\theta} L(x; \theta_f, \theta_l), \quad \text{where } \theta_l = \theta_o^l + \sum_{i=0}^N \alpha_i \Delta\theta_i + \Delta\theta \text{ and } \Delta\theta_i \in T = \{\Delta\theta_i\}_{i=0}^N. \quad{(2)}- 这里,\Delta\theta 表示当前轮次适应的可学习参数,\alpha 表示不同领域知识的归一化权重,即 \sum_i \alpha_i = 1 。因此,知识重编程和新知识学习被解耦为对 \alpha 和 \Delta\theta 的优化。注意,作者引入 \Delta\theta_0 以确保重编程的更高灵活性,例如,通过设置 \alpha_0 = 1 ,可以在先前学到的知识对当前领域适应无益时完全忽略它们。
T 的第一项是一个空的共享向量,设置 \alpha_0 = 1 时则其他领域的向量权重为0,完全忽略先前的知识。
- 自适应温度缩放 (temperature scaling) 实现快速适应
- 当测试分布突然变化时,快速重新加权适当的知识以进行聚合是快速适应的关键。然而,当 α 的logits变得尖锐时,这一过程会受到阻碍,使得重新加权难以偏向其他知识。
- 为缓解这一问题,在优化阶段进一步引入了自适应缩放温度,这有助于在保持原始logits平滑性的同时自适应地调整 \alpha 的尖锐程度。 \alpha 的计算可以表示为 \alpha = \text{softmax}(\beta \cdot T_l) ,其中 \beta 是 logit 向量,T_l 是可学习的温度参数。
3.2 基于相似性的知识聚合
-
无需后向传播,从已经有的共享向量中找到相似领域的向量进行更新,适合资源限制和延迟要求的情况。
-
形式上,给定由 m 个资源充足的主代理设备共享的领域向量 T = \{\Delta\theta_i\}_{i=0}^N ,每个设备有 n 个遇到的领域且 \Delta\theta_0 = 0 ,适应的目标是找到合适的归一化权重 \gamma^* \in \mathbb{R}^{N+1} ,使得:
\gamma^* = \arg\min_\gamma L(x; \theta_f, \theta_l), \quad \text{where } \theta_l = \theta_o^l + \sum_{i=0}^N \gamma_i \Delta\theta_i \text{ and } \Delta\theta_i \in T = \{\Delta\theta_i\}_{i=0}^N. \quad (3) -
根据分布相似性直接为每个 \gamma_i 分配具体的值,通过计算特征统计量(即来自首个主干层特征的均值和标准差)来估计分布。形式上,设 \phi_d 表示当前分布的统计量,通过公式 (6) 在线估计,\phi_i 表示 \Delta\theta_i 所适应的分布统计量(即在学习 \Delta\theta_i 时对应的 \phi_d ),通过对不同分布的知识进行重加权:
\gamma = \text{softmax}(\rho), \quad \text{where } \rho_i = \frac{1}{D(\phi_d, \phi_i) + \varepsilon}. \quad (4)- 这里,\rho 是一个logit向量,D(·, ·) 是一种距离度量,采用KL散度(如公式 (7) 所示), \varepsilon 是一个小常数,用于数值稳定性。
- 利用多样化知识进行聚合
-
聚合不同知识的优势是在各种分布偏移下实现令人满意的鲁棒性的关键。
-
然而,当分布高度相似时,重加权logit \rho_i 会变得足够大,而softmax函数往往会简化为最大值函数,这阻碍了公式(3)聚合多样化知识的潜力。
-
为了缓解这一问题,进一步引入了一个预定义的温度缩放因子 T_f 来软化 \rho_i,从而鼓励聚合更多现有的知识。然后,\rho_i 被重新定义为:
\rho_i = \frac{1}{T_f \cdot D(\phi_d, \phi_i) + \epsilon}. \quad (5)
-
- 注意
- CoLA可以与现有的TTA技术结合,作为一个即插即用模块。
- 与先前需要密集传输数据和模型权重的方法[4]不同,CoLA具有以下优势:
- 1)CoLA仅涉及传输学习到的参数,这既保护了用户隐私,又大大减轻了通信负担。
- 2)领域向量通过一个领域变化检测器间歇性地保存和共享,这进一步大幅减少了通信负担。
- 3)CoLA是去中心化且灵活的,允许所有代理随时加入或退出协作。
3.3 自动领域偏移检测
- 知识向量 T 的构建方法
-
问题:在实际应用中,在每个设备的终身适应过程中,通常无法获得关于给定测试样本流的领域标签的任何先验信息。
-
为了解决这一问题,作者设计了一种高效的分布偏移检测器,用于识别测试分布是否发生变化,并在检测到领域变化时自动将当前学到的模型权重存储到领域向量集合 T 中。
-
作者通过测量分布统计量 \phi_d 与当前测试批次统计量 \hat{\phi}_t 之间的差异来实现这一点
-
形式上,设 f_{\theta_s}(\cdot) 为 f_\theta(\cdot) 的主干层(即第一层),\hat{\phi}_t 包含基于 f_{\theta_s}(x_t) 计算的均值 \hat{\mu}_t 和标准差 \hat{\sigma}_t 。然后,通过指数移动平均从观察到的测试样本 \{x_t\}_{t=1}^T 中估计统计量 \phi_d :
\phi_d = \lambda \hat{\phi}_t + (1 - \lambda) \phi_d, \quad (6) -
其中 \lambda 是属于 [0, 1] 的移动平均因子。
-
-
受现有基于距离的检测方法[19]的启发,作者通过以下距离函数 D(·, ·) 来捕捉分布偏移的幅度:
D(\phi_d, \hat{\phi}_t) = \frac{1}{H} \sum_{i=1}^{H} KL(\phi_{d,i} \| \hat{\phi}_{t,i}) + KL(\hat{\phi}_{t,i} \| \phi_{d,i}), \\ KL(\phi_1 \| \phi_2) = \frac{1}{2\sigma_2^2} (\sigma_1^2 + (\mu_1 - \mu_2)^2), -
其中 H 表示统计量的维度,KL(·||·) 是从[19]简化而来的KL散度。当 D(\phi_d, \hat{\phi}_t) > z 时,检测到分布偏移,其中 z 是预定义的阈值。
-
- 这种简单的设计具有以下几个优点:
- 1)它对计算和内存成本的影响极小,且无需保存数据。
- 2)通过利用主干层的特征,可以快速检测并响应分布偏移,使其非常适合TTA的在线特性。
4 实验
- 数据集:ImageNet-1K 以及五个用于分布外(OOD)泛化的基准数据集,包括:ImageNet-C [16](包含4大类共15种类型的损坏图像,每种类型有5个严重程度级别)、ImageNet-R(200个ImageNet类别的各种艺术化渲染)[15]、ImageNet-Sketch [55]、ImageNet-A [17] 和 ImageNet-V2 [44]。
- 模型:ViT-Base,在ImageNet-1K上进行训练,模型权重从timm库获取。
- 对比方法:
- 1)基于反向传播的方法:CoTTA [56]、ETA [38]、EATA [38]、SAR [39] 和 DeYO [25];
- 2)无反向传播的方法:LAME [3] 和 T3A [21]。
- 其余超参数见论文。
4.1 sota对比
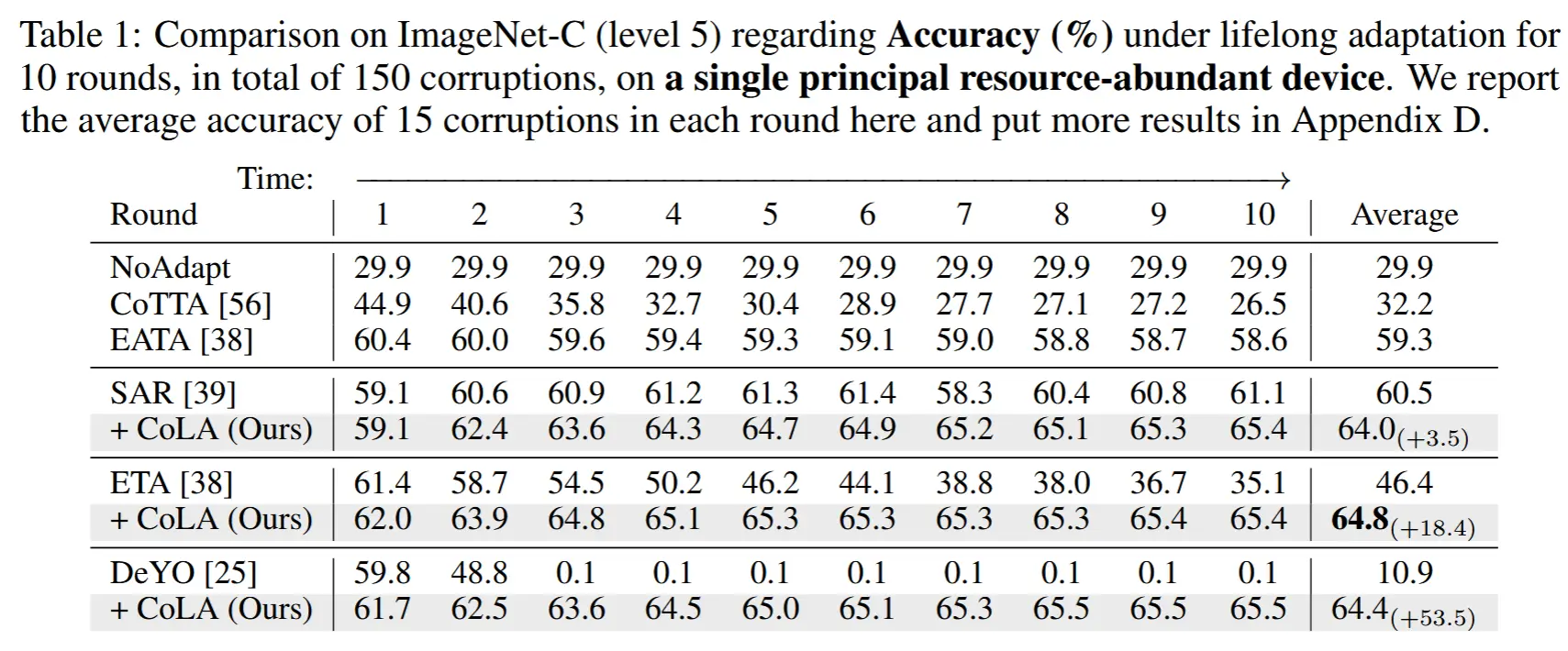
- lifelong test-time adaptation
- 在 ImageNet-C 上评估了CoLA在具有挑战性的终身TTA场景中的长期有效性,该场景中模型在线适应10轮共15种损坏(总计150种损坏),且参数永远不会重置。
- 结果如表 1 所示
- 结果:
- CoLA 取得了最好的表现,稳步提升性能。
- 大多数方法,包括带有对抗遗忘策略的CoTTA和EATA,随着适应轮次的增加,性能会下降。
- 尽管EATA通过引入抗遗忘正则化缓解了性能下降,但它面临稳定性-可塑性权衡问题,即第一轮的平均准确率从61.4%(ETA)降至60.4%(EATA)。
- collaborative test-time adaptation
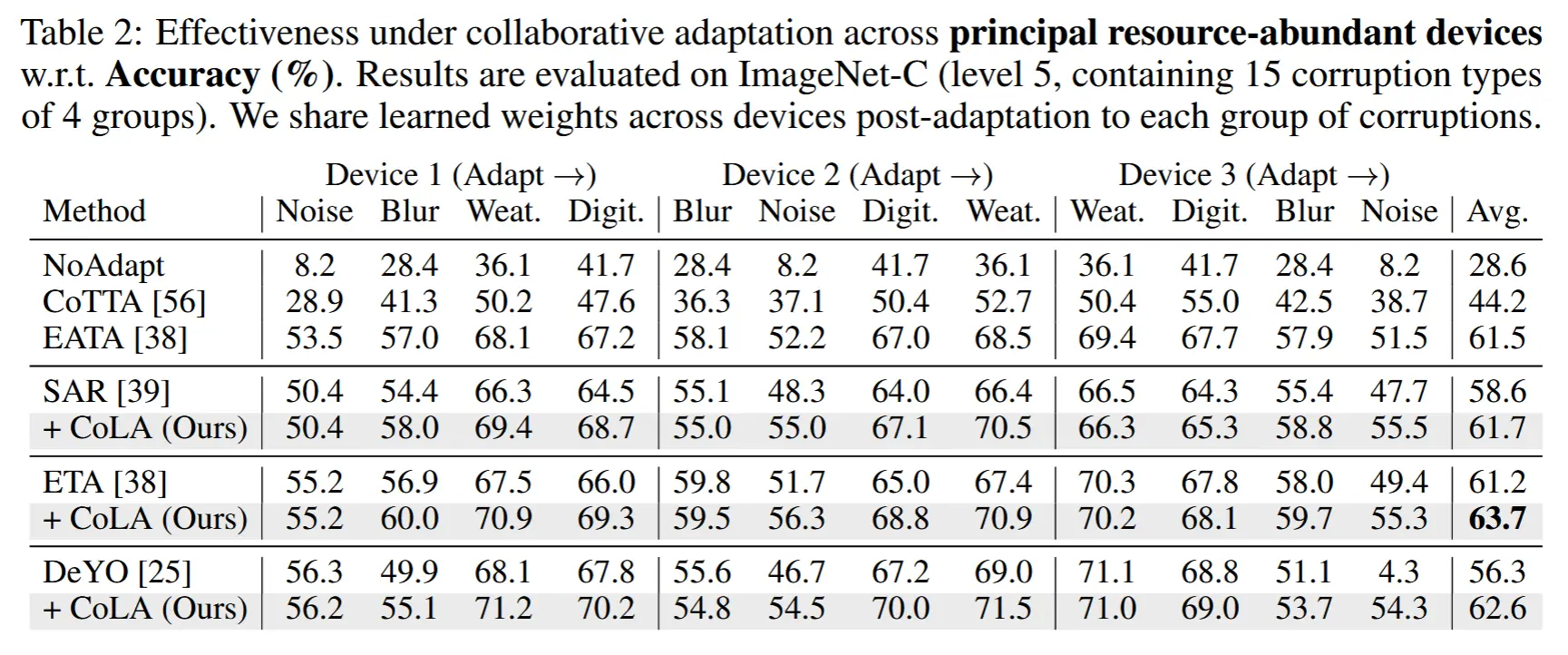
- 1)表 2:首先评估其在多个资源充足的主设备上的性能,在 ImageNet-C(级别 5,包含 4 组的 15 种损坏类型)上进行评估。
- CoLA在适应到第二组损坏时超越了集成基线。
- 随着设备间共享知识的增加,这种改进变得更加显著。
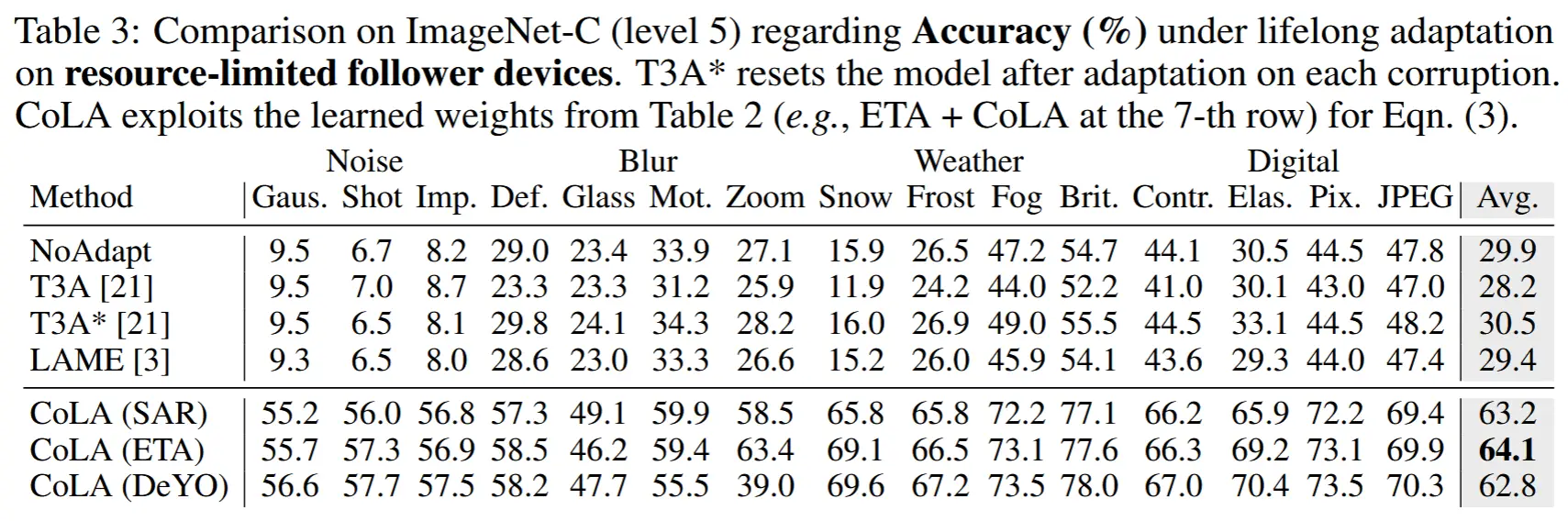
- 2)表 3:基于从资源充足的主设备中获得的已学知识(总计34个权重,占用5.0 MB),进一步评估了CoLA在资源受限的从设备上的有效性。
- 现有的TTA方法在没有模型更新的情况下难以提升源模型的性能。
- 通过公式(3)以仅前向传播的方式自适应地利用共享知识,CoLA实现了显著的性能提升。
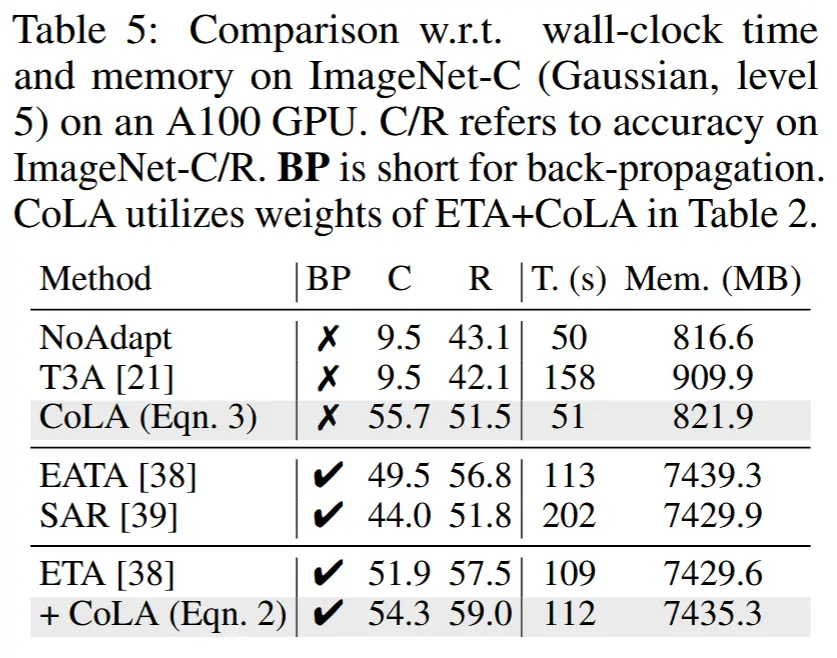
- 3)表 5:验证CoLA的样本效率以及计算和内存效率
- C/R 是指 ImageNet-C/R 上的准确性。BP 是反向传播的缩写。
- 1)表 2:首先评估其在多个资源充足的主设备上的性能,在 ImageNet-C(级别 5,包含 4 组的 15 种损坏类型)上进行评估。
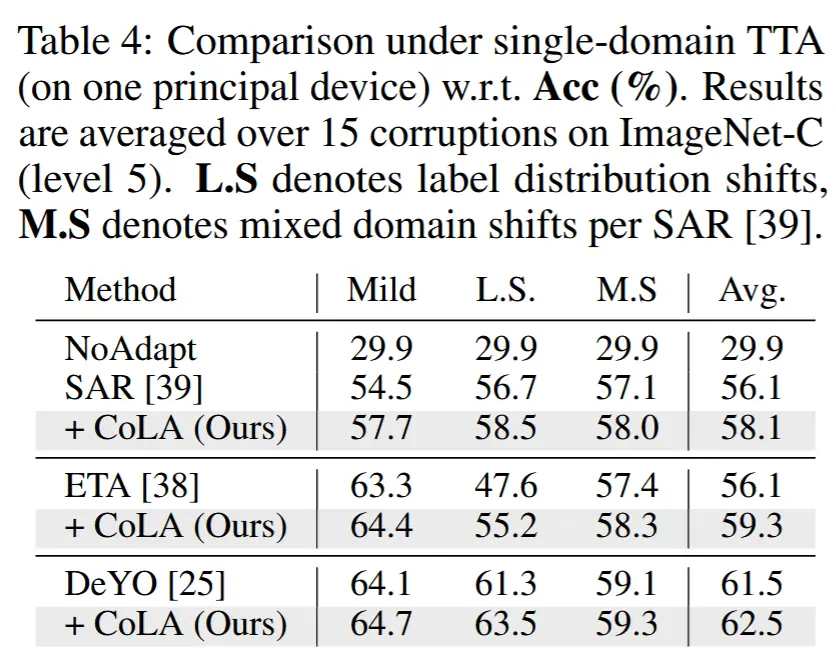
- single-domain test-time adaptation
- 在两种场景下验证了CoLA:野外场景(即标签分布偏移不平衡和分布偏移混合)以及单领域TTA的温和场景,其中模型在每次适应后会被重置。在此场景中,CoLA为每10批次样本保存适应后的权重,同时根据 \alpha_i 丢弃未使用的权重,最多保留32个权重(总计4.7 MB)。
- 从表4可以看出,在所有评估场景中,结合CoLA均显著提升了性能。
- L.S 表示标签分布偏移,M.S 表示每个 SAR 的混合域偏移。
4.2 消融实验
略
5 总结
在本文中,作者提出了一种用于测试时适应(TTA)的多设备协作终身适应(CoLA)范式,该范式解决了一个实际场景,即具有不同计算资源和延迟需求的多个设备需要同时执行TTA。具体来说,首先通过一个高效的领域偏移检测器积累了一组共享的领域知识向量。基于此,在主代理上开发了一种知识重编程学习策略,该策略利用基于反向传播的优化来聚合现有知识,同时学习新的领域特定参数。为进一步提高适应效率,在从代理上引入了一种无优化的TTA策略,该策略仅根据领域相似性聚合共享的领域向量。在CoLA中,所有设备/代理协同工作,同时确保隐私保护和通信效率。实验验证了CoLA在协作、终身和单领域TTA场景中提升了现有TTA解决方案的性能和效率。