- 论文 - 《Modality-Collaborative Test-Time Adaptation for Action Recognition》
- 关键词 - CVPR、多模态、视频动作识别、TTA
摘要
- 研究背景
- 基于视频的无监督领域自适应(UDA)方法提升了视频模型的泛化能力,然而,它们在自适应过程中需要持续访问源域数据,这在实际场景中是不切实际的。
- 而现有的基于图像的 TTA 方法无法直接应用于多模态视频任务,因为视频在多模态和时间维度上存在领域偏移。
- 本文工作
- 提出了一种 模态协作测试时自适应网络(Modality-Collaborative Test-Time Adaptation, MCTTA) 。MCTTA 包含分别用于生成 伪原型(pseudo-prototypes) 和 目标原型(target-prototypes) 的 教师记忆库和学生记忆库。
- 在教师模型中,作者提出了 自组装源友好特征重建(Self-assembled Source-friendly Feature Reconstruction, SSFR) ,以鼓励教师记忆库存储更可能与源分布一致的特征。
- 通过多模态原型对齐和跨模态相对一致性,本文的方法能够有效缓解视频中的领域偏移问题。
- 提出了一种 模态协作测试时自适应网络(Modality-Collaborative Test-Time Adaptation, MCTTA) 。MCTTA 包含分别用于生成 伪原型(pseudo-prototypes) 和 目标原型(target-prototypes) 的 教师记忆库和学生记忆库。
1 引言
- 多模态动作识别
- 多模态数据融合成为解决动作识别任务的一种有前途的方法,特别是,RGB 模式提供了丰富的场景上下文信息,而光流模式捕捉了关键的运动属性,能够补充视觉特征,从而实现更准确的动作理解。
- 然而,现有的基于 TTA 的动作识别方法仅考虑了单模态数据,传统视频领域的自适应方法考虑了多模态数据但是不适用于TTA。
- 不同模态的领域偏移总是多样化的。例如,与视觉模态相比,光流模态在背景变化的情况下对动作识别更具领域不变性 [20, 28],而视觉模态包含更多关于动作执行者和上下文的领域特定语义信息。
- 本文方法 - 模态协作测试时自适应网络(MC-TTA)
- 在预训练阶段,利用标注的源域视频分别学习 每个模态对应的特征提取器和分类器,并为融合的多模态学习构建一个 多模态分类器。
- 在自适应阶段,通过预训练模型构建目标域的教师模型和学生模型。
- 教师模型维护一个教师记忆库,用于生成代表伪源域特征分布的 伪原型;
- 学生模型维护一个学生记忆库,用于生成代表目标域特征分布的 目标原型。
- 通过 减少伪源域和目标域分布之间的差异,可以缓解领域偏移问题。
- 在教师模型中,提出了 自组装源友好特征重建模块 SSFR,以鼓励教师记忆库存储更可能与源分布一致的特征。
- 具体来说,为了模仿源分布,SSFR 利用源分类器对目标视频不同模态预测的 logits 的一致性分数和置信度分数,找到与源视频更相似的视频片段。然后,这些选定片段的特征被聚合起来,以表示源友好的特征。
- 接下来,使用多模态原型对齐将目标原型推向伪原型,从而减少多模态领域的偏移。
- 由于目标域数据缺乏监督,可能会导致自适应过程中判别能力下降。因此,作者提出了 跨模态相对一致性损失,利用 模态之间的对应关系 来保持易受领域偏移影响的模态的良好判别能力。
注意:需要修改原本的预训练过程。
2 相关工作
2.1 动作识别
- 现有工作
- TSN:通过在空间和时间维度上利用 2D 卷积网络获取视频级表示,然后融合特征。
- TRN:通过不同时间尺度上帧的时间变换和依赖关系生成视频级特征向量。
- I3D:扩展了双流网络的思想,通过对 RGB 和光流使用 3D 卷积核实现。
- ViViT:在空间编码器的基础上增加了多个时间 Transformer 编码器。
2.2 视频无监督域适应
- 现有工作
- TA3N:使用了一个集成的时间关系模块,该模块可以同时学习时间动态并实现领域对齐。
- TCoN:采用了一种带有跨域注意力模块的深层架构,用于匹配源域和目标域之间时间对齐特征的分布。
- SAVA:利用注意力机制确定具有判别性的片段,并在对抗学习框架内使用这些信息进行视频级别的对齐。
- MMSADA:基于自监督和多模态学习(RGB + 光流)提出了一种领域自适应方法,用于精细的第一人称视角动作识别。
- 尽管 VUDA 方法在提高视频模型的鲁棒性方面带来了改进,但所有这些方法在自适应过程中都需要访问源域数据。
2.3 TTA
略
3. 方法论
3.1 问题定义
在多模态视频 TTA 任务中,使用 D_s = \{x^i_s, y^i_s\}_{i=1}^{n_s} 表示源域数据集,其中 x^i_s 表示一个多模态视频实例, n_s 是源视频实例的数量。 y^i_s \in \mathbb{R}^C 是对应的类别标签,其中 C 表示总类别数。此外,用 D_t = \{x^i_t\}_{i=1}^{n_t} 表示目标域,其中 n_t 是无标签视频实例的数量。仅使用标注的目标域视频实例进行评估。为了全面捕捉动作识别的重要信息,本文在视频中使用 RGB 模态和光流模态 。对于每个多模态视频实例 x ,首先将其分割为 T 个等长片段,可以获得 T 个 RGB 片段和光流片段。
3.2 模态协作测试时自适应 MC-TTA
MC-TTA方法如图 2 所示。主要由三个模块组成:
- 教师模型和学生模型:教师记忆库用于生成伪原型,而学生记忆库用于生成目标原型。伪原型的目的是模仿伪源域的特征分布,而目标原型的目的是表示目标域的特征分布,通过原型之间的对齐来减少领域差异。本文希望教师记忆库存储源友好的特征,使伪原型更接近源域。
- SSFR:鼓励教师记忆库存储更可能与源分布一致的特征。
- 跨模态一致性损失:利用模态之间的对应关系,保持易受领域偏移影响的模态的良好判别能力。
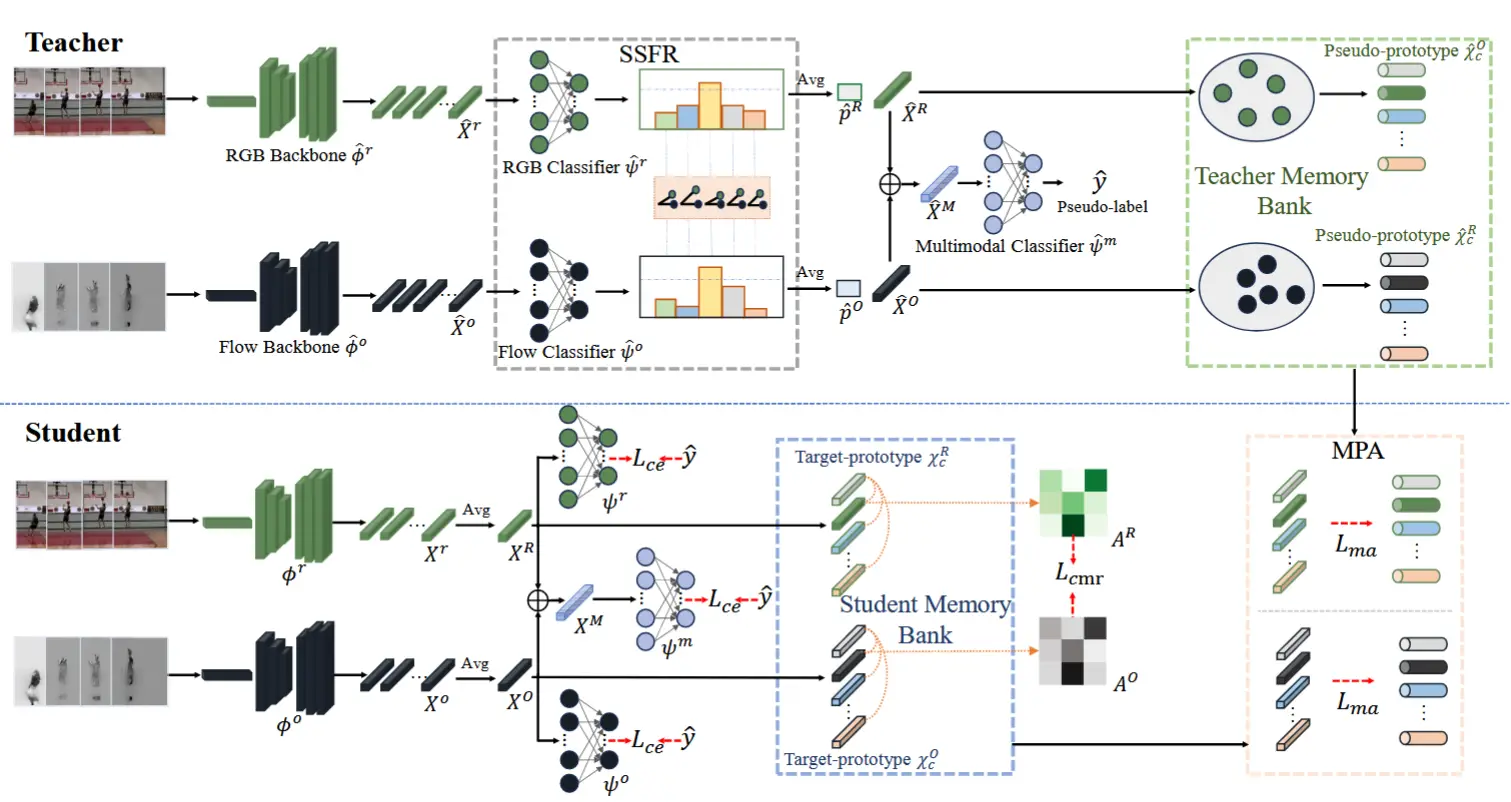
3.2.1 网络架构
遵循 TTA 的设置,无法访问源域数据,只能使用预训练的动作识别分类模型。该模型由两个分支和一个多模态分类器组成。每个分支包括一个特征提取网络 \phi^r/\phi^o 和一个分类器 \psi^r/\psi^o,用于 RGB/光流的特征编码和单模态分类。此外,多模态分类器 \psi^m 通过拼接来自两个分支的特征表示来实现视频的最终多模态分类。
使用 \phi^r 和 \phi^o 网络提取所有视频片段的 RGB 片段特征 X^r = [r_1, r_2, \dots, r_T]^T 和光流片段特征 X^o = [o_1, o_2, \dots, o_T]^T,其中 T 表示视频片段的数量,r_i, o_i \in \mathbb{R}^d,且 X^r, X^o \in \mathbb{R}^{T \times d}。
在训练开始时,教师模型 (h_{\hat{\Theta}_t}) 和学生模型 (h_{\Theta_t}) 共享相同的权重,即 \Theta_t = \hat{\Theta}_t = \Theta_s,其中 \Theta_s 表示源域模型参数,\Theta 包含 \phi^r、\phi^o、\psi^r、\psi^o 和 \psi^m 的参数。
3.2.2 自组装源友好特征重建 SSFR
在 MC-TTA 中,教师模型维护一个教师记忆库,用于存储源友好的特征以模拟伪源域的特征分布。
(如何选择接近源的视频片段?) 首先,两种模态预测之间的高相关性表明源域模型在预测每种模态时做出了相似的判断,这表明该片段的两种模态之间的关系更接近源域的特征分布。其次,较低的熵通常表示目标片段的特征更接近源域的特征分布。因此,这些特征更有助于构建伪源域特征。
(基本思想) SSFR 利用源分类器对目标视频不同模态预测的 logits 的一致性分数 和 置信度分数,找到与源视频更相似的视频片段。然后,将选定片段的特征聚合起来以表示源友好的特征。
(公式化) 每个分支使用教师特征提取器 \hat{\phi}^r_t/\hat{\phi}^o_t 提取目标域多模态视频实例的特征 \hat{X}^r_t/\hat{X}^o_t。在平均片段特征之前,每个片段特征输入到教师单模态分类器 \hat{\psi}^r_t/\hat{\psi}^o_t,以获得片段级别的 logits。对于 RGB 和光流的每个片段 logits,计算 两种模态之间的模态相关余弦距离:
其中 \hat{p}^r_t 是 RGB 模态的片段级别 logits,\hat{p}^o_t 是光流模态的片段级别 logits。d 表示两种模态分类结果的相似性。
对于每个片段,计算教师 单模态分类结果的片段级置信度分数 conf(\hat{p}_t):
其中 \hat{p}_t \in (p^r_t, p^o_t)。最后,通过模态相关性和置信度分数确定片段 是否为源友好:
其中,\alpha 和 \beta 是阈值。通过 合并两种模态的视频级源友好特征,得到多模态特征表示 \hat{X}^M_t = \text{concat}(\hat{X}^R_t, \hat{X}^O_t),其中 \hat{X}^R_t/\hat{X}^O_t 表示对所有源友好的 RGB/光流模态 片段特征 进行 平均。然后,可以获得目标视频实例的 伪标签 \hat{y} = \arg\max \hat{p}^m_t,其中 \hat{p}^m_t = \psi^m_t(\hat{X}^M_t)。
(教师记忆库) 在自适应过程中,给定一个无标签的多模态视频实例,可以通过教师模型获得视频级别的 RGB 和光流特征以及 logits。值得注意的是,这些特征和 logits 是通过对上述方法获取的源友好的片段进行平均得到的。维护一个 教师记忆库 \hat{M}_t = \{(\hat{X}^R_t, \hat{p}^R_t), (\hat{X}^O_t, \hat{p}^O_t)\},用于 存储目标域视频实例的源友好特征和 logits。遵循 T3A 和 TSD 的方法,教师记忆库初始化为源单模态分类器 \psi^r_s 和 \psi^o_s 的权重。通过教师记忆库建立当前实例与所有先前实例之间的关系,可以为每个类别生成伪原型。
类 c 的原型可以公式化为:
其中 1(\cdot) 是指示函数,如果 \hat{y}_i = c 则输出值为 1,否则为 0。希望从教师记忆库中生成与源域特征具有高相似性的类原型。通过输入记忆库,作者基于存储的视频 logits 进行熵判断。为了进一步提高相似性,选择前 K 个低熵特征的平均值来获得伪原型。
3.2.3 关系感知多模态自适应
(学生记忆库) 为了减少领域偏移,需要将目标域特征推向源域特征。因此,在学生模型中维护一个学生记忆库 M_t = \{X^R_t, X^O_t\},用于存储目标域特征,其中 X^R_t/X^O_t 表示通过平均所有片段特征得到的视频级 RGB/光流特征。当每个 X^R_t/X^O_t 来临时,作者 将其与相应的类原型进行平均,以获得新的类目标原型 \mathcal{X}^R_c/\mathcal{X}^O_c,其中 X^R_t/X^O_t 的 伪标签由教师模型生成。与教师记忆库相比,学生记忆库在两个方面有所不同:(1) 它的目的是存储目标域视频的视频级特征,以获取目标原型;这些视频级特征是通过对每个视频内的所有片段特征进行平均得到的;(2) 它初始化为零权重。
(多模态原型对) 为了明确减少源域和目标域之间的多模态领域偏移,需要将目标域特征推向源域分布。由于教师记忆库由接近源域特征分布的原型组成,可以将其视为域自适应中的伪源域。然后,使用 多模态原型对齐损失 来对齐两个记忆库中两种模态的类原型,公式如下:
其中 \mathcal{X}_i^R 和 \mathcal{X}_i^O 分别表示学生记忆库中第 i 类的 RGB 原型和光流原型。通过这一约束,多模态视频特征可以显式地减少领域偏移。
(跨模态相对一致性) 不同模态的领域偏移总是各不相同,在多模态视频测试时自适应(MVTTA)任务中,全面考虑不同模态的领域偏移非常重要。需要利用模态之间的对应关系,让判别能力强的模态引导判别能力严重下降的模态。 因此,作者提出了一种跨模态相对一致性损失。与多模态原型对齐不同,该模块专注于模态协作,使其在自适应后仍具有良好的判别能力。
具体而言,计算学生记忆库 M_t 中每个类别的原型之间的 欧几里得距离,并构建 原型之间的关系矩阵如下:
其中 E(\cdot) 表示欧几里得距离公式,A^R, A^O \in \mathbb{R}^{C \times C} 分别表示 RGB 和光流的模态关系矩阵。\mathcal{X}_i, \mathcal{X}_j 分别是学生记忆库中第 i 类和第 j 类的原型。
不同模态的领域偏移不同:例如,在快速运动或背景变化较大的场景中,光流模态的表现会更加稳定和鲁棒;而在纹理丰富、细节丰富的场景中,RGB 模态提供的视觉信息将更为稳定。
然后,通过 A^R 和 A^O 关系矩阵之间的 KL 散度实现模态关系的自适应:
(分类约束) 除了上述操作外,作者还使用教师模型生成的伪标签计算两个单模态分类器和一个多模态分类器的 交叉熵损失:
其中 \sigma 表示 softmax 操作。p_t^R/p_t^O 是学生单模态分类器 \psi_t^R/\psi_t^O 的预测,而 p_t^m 是学生多模态分类器 \psi_t^m 的预测。最小化 \mathcal{L}_{\text{CE}} 可以增强教师和学生预测的一致性。
3.2.4 训练目标函数
结合公式 (5)、公式 (7) 和公式 (8),最终的目标函数为:
其中 \lambda 是平衡不同损失函数的权衡参数。
在学生模型 h_{\Theta_t} 的更新(\Theta_{t,j} \to \Theta_{t,(j+1)})之后,使用 指数移动平均(EMA)通过学生权重更新教师模型 h_{\hat{\Theta}_t} 的权重:
其中 \gamma 是一个平滑因子,控制每次更新时所需的更改程度。
4 实验
4.1 实验设定
- 数据集
- UCF-Olympic:6个共享类别,分别来自 UCF-101 和 Olympic。
- UCF-HMDBsmall:两个数据集的5个共享类别。
- UCF–HMDBfull:两个数据集的12类共享动作。
- Epic-Kitchens:在三个域分区(D1、D2、D3)上进行。
- 基线方法:Tent、LAME、T3A、TSD、ViTTA、MM-TTA、Source-only
- 实现细节
- 主干模型:I3D,初始化权重来自 ImageNet 和 Kinetics 预训练。
4.2 与 SOTA 比较
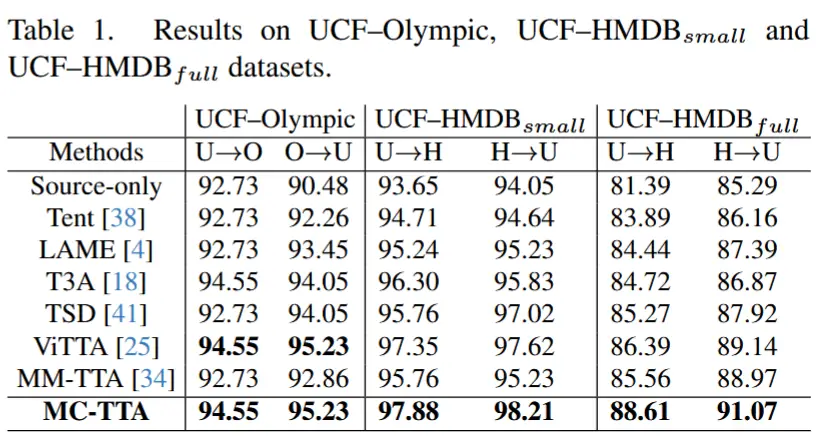
- 表1
- 数据集偏移设置
- MC-TTA超越了SOTA方法
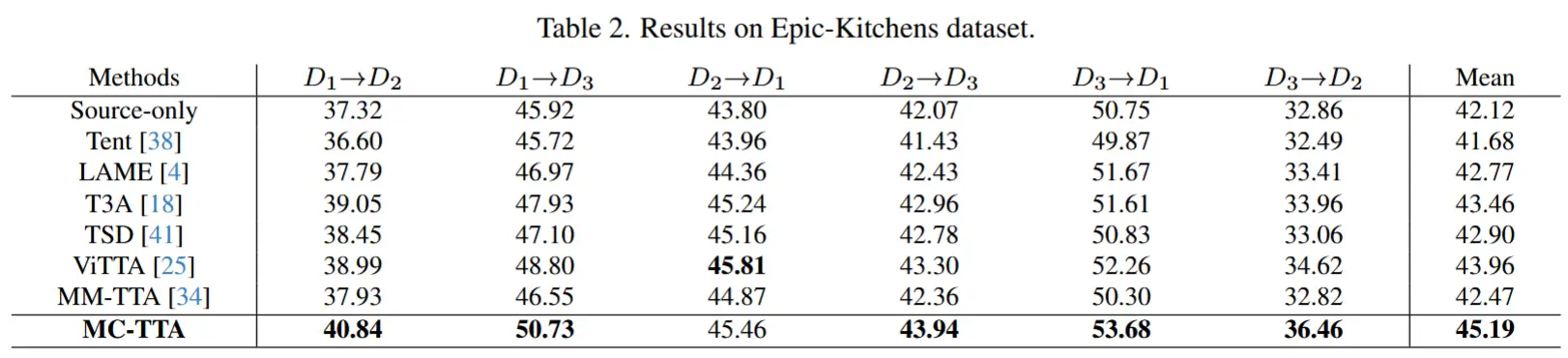
- 表2
- 在Epic-Kitchens上预测,从不同的分区偏移到其他分区。
- 数据集更具挑战性,所有方法的准确率较低,但 MC-TTA 在 5 个领域自适应任务中表现最佳。
- 图3
- 通过可视化不同方法在自适应过程中的准确率变化,MC-TTA 能更快地调整数据分布,在目标域中实现更高的准确率。

4.3 消融
- 表3
- 本节通过分析 MC-TTA 的三个关键组件(SSFR、多模态原型对齐、跨模态相对一致性 )在四个数据集上的影响,进一步评估了模态协作测试时自适应网络的有效性。

除此以外,作者还进一步做了以下实验
Sensitivity to hyperparameter
Hyperparameter Selection Strategy.