- 论文笔记 - 《Unsupervised Domain Adaptive Visual Question Answering in the era of Multi-modal Large Language Models》
- 关键词 - 问答、特征对齐、多模态、域适应、WACV2025
1 介绍
-
研究背景:无监督域自适应(UDA)在视觉问答(VQA)任务中引起了研究兴趣。然而,尽管多模态大语言模型(MLLMs)在 VQA 数据集上表现出色,但基于 MLLMs 的 VQA 无监督域自适应仍未被探索。
-
以 BLIP2 为例,基于此类 MLLMs 的 UDA 面临以下三个挑战:
- C1 :鉴于各种 VQA 数据集中两个模态的单模态特征空间中存在的域偏移,以及 BLIP2 处理文本和图像编码的不同方式,第一个挑战在于 为图像和文本模态设计定制化的单模态特征对齐方法。
- C2 :一组预训练的可学习查询与 Q-Former 中的多模态输入交互以生成跨模态查询,从而导致跨模态特征空间中出现显著的域偏移。直观上看,每个可学习查询对来自不同领域的多模态输入具有不同的感知能力。实验表明,对来自特定领域的多模态输入更敏感并提取更重要的领域信息的可学习查询,在跨模态特征空间中的域偏移中起到了显著作用。因此,区分这些查询与可学习查询输出,并将其用于有效的跨模态特征对齐至关重要。
- C3 :由于硬提示策略对 MLLMs 的零样本性能及微调性能有重大影响,有必要 设计一种专门的硬提示策略来辅助 UDA 微调。
-
本文工作:提出了首个基于多模态大语言模型(MLLMs)的无监督域自适应 VQA 系统化方法(UDAM)
- 针对 C1 ,我们引入了 语义上下文特征对齐(SCFA) 和 领域查询特征对齐(DQFA) ,分别针对文本和图像模态设计。这些方法通过为每个模态引入一个单一的 token 嵌入来捕获单模态输入的全局级上下文领域信息,并对其进行粗粒度特征对齐,从而缓解各模态单模态特征空间中的域偏移。
- 针对 C2 ,我们提出了新颖的 语义引导查询特征对齐(SQFA) ,该方法区分出重要的领域特定查询与可学习查询输出,并通过语义引导权重图控制细粒度特征对齐,从而减少跨模态特征空间中的域偏移。
- 针对 C3 ,我们设计了 一种成对的领域感知提示策略 ,通过提示 MLLMs 区分多样化多模态输入中的任务共性和领域差异,从而辅助 VQA 的无监督域自适应。
2 相关工作
2.1 MLLMs
- MLLM
- 工作原理:MLLMs 通常开发多种类型的多模态感知器(perceiver),将多模态输入转换为软提示(soft prompts),然后与文本输入一起输入到大语言模型中以生成答案。
- 相关工作
- BLIP2 引入了 Q-Former 作为其多模态感知器。Q-Former 将图像、文本以及一组可学习查询(learnable queries)作为输入。在 Q-Former 的前向传播过程中,这些可学习查询捕获与文本相关的图像特征。
- 其他一些工作 [1, 4, 53] 则采用了更简单的多模态感知器,甚至将视觉特征集成到不同层 [52] 中,并训练 LLM 以增强其视觉能力。
- 评价:在预训练阶段通过 Q-Former 模块可以高效地建模了图像-文本对齐关系,而在微调阶段仅需训练 Q-Former,这种方法更具成本效益。这使得 BLIP2 成为我们本文的一个更适合的起点。
2.2 无监督域自适应 UDA
-
主流UDA方法分类
- 自训练方法:专注于如何为未标记的目标数据生成高质量的 伪标签 。
- 特征对齐方法
- 基于差异的方法: 一类通过 减少分布差异的各种度量 (如最大均值差异 MMD [46]、CoRAL [42]、Wasserstein 距离 [40] 等)来减少域偏移;
- 基于对抗的方法: 另一类涉及神经网络的 领域对抗训练(DANN)[7, 45, 49, 50],即模型在训练过程中通过与领域判别器竞争来学习领域不变特征。
-
大规模预训练模型上的单模态UDA分类
- 自训练方法
- 主要聚焦于图像分类,利用 CLIP [36] 的零样本能力为目标数据生成伪标签。
- Saad-Falcon 等人利用 LLMs 为目标域生成合成查询以用于段落检索。
- 将自训练方法应用于 VQA 的主要障碍在于难以合理评估和过滤模型的答案。
- 特征对齐方法
- Malik 等人 [34] 将 Adapters [20] 集成到 LLMs 中,并通过减少 MK-MMD [33] 度量的领域差异实现 UDA。
- Yang 等人 [54] 将基于对抗的方法应用于视觉预训练模型。
- 自训练方法
-
多模态 VQA UDA
- Chao 等人 [6] 指出,在各种 VQA 数据集中,文本和图像模态之间存在显著的域偏移,并使用 DANN 减少领域间的偏移以实现 UDA。
- Xu 等人 [51] 提出了一种面向开放性 VQA 的多模态 UDA 框架,该框架最小化领域间单模态特征的 MMD,并利用 DANN [12] 对融合特征进行特征对齐。然而,这种方法的有效性仅在 VQA 2.0 [16] 和 Vizwiz [19] 之间得到验证,这也带来了一定的局限性。
- Zhang 等人 [59] 在 VQA 模型的视觉编码器上应用了 DANN,但未探讨文本模态中的域偏移。
- Zhang 等人 [58] 探讨了基于两个 2019 年 VQA 模型的 MMD、自监督重建和监督辅助协同训练的影响。
-
局限
- 上述 VQA 的 UDA 研究,源域和目标域均使用类似的现实图像来源(如 COCO 数据集),这导致其跨域场景中图像模态的域偏移较小,从而使其方法的说服力不足。
- 以往的研究尚未探索 MLLMs,而本文正是填补了这一空白。
2.3 MLLMs 提示工程
- 本节主要关注硬提示(hard prompts)
- 不同的 MLLMs 精心设计了多种硬提示以优化多模态任务中的零样本推理性能。
- Huang 等人通过结合硬提示和特定类别的描述来提升零样本图像分类的性能。
- Awal 等人系统地研究了各种硬提示技术在 BLIP2 上进行零样本 VQA 推理的有效性,这些技术包括任务特定指令、上下文示例以及各种信息丰富的标题。
3 问题定义
首先,一个常规的 VQA 数据集被定义为 D = \{(I_i, Q_i), A_i\}_{i=1}^n ,其中第 i 个样本包含一张图像 I_i 和与其对应的提问 Q_i。 A_i 是给定图像和提问组合时的期望答案。
然后,在 UDA 的设置下,进一步使用 D_S = \{(I_i^s, Q_i^s), A_i^s\}_{i=1}^{n_s} 表示带有 n_s 个标记样本的源数据集。未标记的目标数据集表示为 D_T = \{(I_i^t, Q_i^t)\}_{i=1}^{n_t} 。我们遵循开放性设置(open-ended setting),即不提供候选答案,模型可以以任何形式回答问题。我们的目标是利用 D_S 和 D_T 对 MLLMs 进行微调,使其在目标域上达到最优性能。
4 方法
4.1 粗粒度单模态特征对齐
首先为文本和图像模态分别提出了 两种粗粒度的单模态特征对齐 方法。
作者使用图 1 中的单模态掩码策略来控制 Q-Former 的自注意力机制,防止文本输入和可学习查询相互干扰,从而获得单模态特征输出。
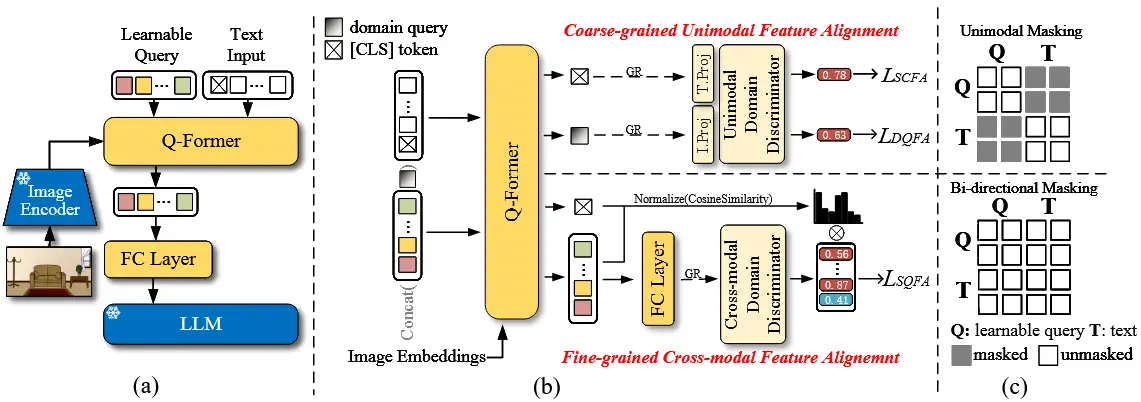
(语义上下文对齐) 对于文本模态,引入了语义上下文特征对齐(SCFA)。Q-Former 的文本输入的第一个 token 总是被指定为 BLIP2 中的 [CLS] token。得益于在大量数据上的预训练过程,Q-Former 输出的 [CLS] 嵌入 t 表示 给定文本输入的上下文语义,并应包含文本模态的有价值领域信息。将 t 输入到一个全连接层 f_t ,然后再将其输入到域判别器 D_{\text{uni}} 中以区分其所属的域。我们采用 二元交叉熵(BCE) 损失作为 SCFA 的域分类损失,其公式如下:
其中,域标签 d 对于源域为 0,对于目标域为 1。
(域查询特征对齐) 对于图像模态,引入了域查询特征对齐(DQFA)。在 Q-Former 中,一组可学习查询用于跨注意图像嵌入,生成代表图像信息的单模态查询。我们首先定义了 一个额外的可学习域查询 token ( dq ) ,任务是 捕获图像嵌入中的域信息 。( dq ) 的权重通过平均所有可学习查询的权重初始化,确保域查询在早期阶段具有捕捉有价值信息的能力。( dq ) 被附加到可学习查询中,形成 Q-Former 的输入,仅在前向过程中与其他可学习查询交互。我们将 Q-Former 的输出表示为 [\{\tilde{q}_i\}^n : \tilde{dq}] 。这样,域查询收集图像的全局域信息,而可学习查询提取辨别性特征。在这一过程中,可学习查询的权重被冻结以保持其辨别能力。\tilde{dq} 然后被输入到一个全连接层 f_i 以及域判别器 D_{\text{uni}} 。DQFA 的域分类损失如下:
SCFA 和 DQFA 方法都 利用单个 token 嵌入捕获全局上下文域信息 ,并通过 对抗训练 对其进行特征对齐,即 Q-Former 在训练过程中与 D_{\text{uni}} 进行竞争。
4.2 细粒度跨模态特征对齐
在本节中,将展示本文提出的新型细粒度跨模态特征对齐方法。
前情分析
猜想:某些查询可能对特定领域的多模态输入更敏感,并捕获更有价值的领域信息,这表明它们具有更强的领域特异性。
实验:作者在基于 Vicuna7B 的 BLIP2 上进行实验,在 AOKVQA→VQA-Abstract 场景中验证这一直观想法。对于每一对图像和问题,将其输入到 Q-Former 中,并计算 32 个跨模态查询与 [CLS] 嵌入输出之间的余弦相似度,即多模态输入的上下文语义。在 AOKVQA 验证集上计算所有 32 个查询的平均相似度,并按降序排列。作者发现,大约 12.5% 的跨模态查询表现出显著的语义余弦相似度。 相比之下,其他跨模态查询的相似度非常小,甚至小于 0。
结论:领域特定查询(domain-specific queries)对跨模态特征空间中的域偏移贡献巨大。
(语义引导查询特征对齐) 基于上述分析,我们提出了一种名为 语义引导查询特征对齐(SQFA) 的细粒度跨模态特征对齐方法,以通过语义引导权重图控制跨模态特征空间中的域偏移。在 Q-Former 的前向传播过程中,采用图 1 所示的双向自注意力掩码策略,可学习查询能够与文本输入交互,从而生成跨模态查询。在此设置下,[CLS] token 在编码过程中仍然表示整个多模态输入的上下文语义,我们计算每个跨模态查询与 [CLS] 嵌入输出之间的余弦相似度。然后,我们根据计算得到的相似度计算一个语义引导权重图 W,具体如下:余弦相似度小于 0 的查询被赋予权重为 0,而其他查询的权重则根据其余弦相似度进行归一化求和得到。
然后,我们通过 Q-Former 后的预训练全连接(FC)层对所有跨模态查询进行投影,在此过程中,跨模态查询经过维度扩展并进一步丰富其语义信息。由于 FC 层的输出,表示为 \{\hat{q}_i\}^n ,将直接用作下游 LLM 的软提示,我们认为在这些嵌入上进行细粒度的域对齐是有益的。我们将 \{\hat{q}_i\}^n 输入到一个域判别器 D_{\text{cross}} 中,以获取它们的分类损失。在这里,我们也使用 BCE 损失。我们将这一步中获得的跨模态查询的分类损失乘以语义引导权重图,从而得到 SQFA 的最终损失,公式如下:
其中,w_i 表示第 i 个输出跨模态查询对应的权重。
总之, SQFA 方法通过语义引导权重图区分领域特定查询和可学习查询输出,并在跨模态特征空间中进行细粒度的跨模态特征对齐,从而减少域偏移。
4.3 成对的领域感知提示策略
研究不同的提示策略如何影响 MLLMs 的 UDA 微调至关重要。我们首先研究了几种最广泛使用的提示策略对 MLLMs 零样本推理和 UDA 微调的影响,然后设计了一种简单而实用的成对领域感知提示策略,以辅助 MLLMs 的 UDA 微调。
我们设计的成对领域感知提示策略 由三个组件组成 ,具体如下:
- 领域无关的任务指令:对于视觉问答(VQA),我们使用“Visual Question Answering”作为任务指令。
- 领域特定的风格描述:我们为每个数据集中的图像精心选择一种风格描述,例如,对于 VQA-Abstract,我们使用“abstract images”(抽象图像)。数据集的详细描述见补充材料。据我们所知,我们是第一个探索图像风格描述对零样本 VQA 推理影响的研究。
- 每个样本的格式化文本输入:
我们通过以下策略格式化原始问题输入:“Question: ⟨question⟩ Answer:”。
在进行 UDA 微调时,我们在不同领域之间保持任务描述不变,但为目标域和源域使用不同的领域特定风格描述,从而提示 MLLMs 区分任务的共性和领域间的差异性。在推理过程中,我们使用目标域对应的提示策略。这种提示策略被证明在零样本推理和 UDA 微调中都非常有效,并且具有高度适应性,因为每个组件都可以根据数据变化进行调整。
4.4 总体训练策略
本节中,我们将介绍基于 MLLMs 的 UDA 微调策略。首先,我们使用成对的领域感知提示策略重构源域和目标域的数据输入。对于标记的源域数据,我们要求 MLLM 提供自由形式的答案,并计算语言建模损失 L_{lm} ,将预测结果与真实标签进行对比。对于目标域数据 ( d = 1 ),由于没有真实标签,因此 L_{lm}(F) = 0 。对于两个域的数据,我们分别计算 SCFA、DQFA 和 SQFA 的损失,并通过超参数 \alpha 控制它们之间的权重比。对抗训练损失 L_{UDAM} 可以表示为:
总结来说,总体训练目标可以定义为:
其中,D 表示域判别器以及 f_t 和 f_i 。 F 是 MLLM 中所有可训练模块的统一表示。 \lambda 表示对抗训练损失 L_{UDAM} 的权重。
5 实验
5.1 实验设定
- 数据集:OKVQA、AOKVQA、CLEVR、VQA-Abstrace
- 设计的跨域场景 :
- OKVQA → VQA-Abstract
- AOKVQA → VQA-Abstract
- OKVQA → CLEVR
- AOKVQA → CLEVR
- 基线
- BLIP2(仅源域训练)
- BLIP2+DANN
- BLIP2+MMD
- BLIP2+MK-MMD
- 评估方法
-
标准 VQA 分数:对于单个问题 q ,假设其有 N 个真实答案,其中 S(a) 个与预测答案 a 相同,则预测答案的准确率计算公式为:
\text{Acc}(a, q) = \min\left(\frac{S(a)}{3}, 1\right) -
精确匹配:对于每个问题只有一个标准答案的 VQA 数据集(如 CLEVR )使用。
-
- 模型:基于 Vicuna7B 的 BLIP2 模型和 FlanT5XL 模型
- 设置
- batch size 为 4,每批次包含来自两个领域的各 2 个样本。
- 只微调 Q-Former 和全连接层(FC Layer)的参数。
- 设置 \lambda=0.003 和 \alpha=0.9 。
5.2 实验结果
- 不同硬提示策略如何提升模型的零样本推理性能?

- 不同硬提示策略如何提升模型的 UDA 微调性能?& 不同特征对齐方法如何增强模型的目标域性能?
- 消融实验