- 论文 - 《LeanTTA: A Backpropagation-Free and Stateless Approach to Quantized Test-Time Adaptation on Edge Devices》
- 关键词 - 边缘、 test-time adaptation、无反向传播、量化
摘要
- 问题背景
- 边缘设备挑战:资源限制、环境的动态性、训练数据与实际场景数据分布之间的差异。
- 当前测试时适应 (test-time adaptation) 方法通常内存消耗较大,并且并非为量化兼容性或在低资源设备上的部署而设计。
- 本文解决办法
- 提出了 LeanTTA,一种新颖的无需反向传播且无状态的量化测试时适应框架,专为边缘设备量身定制。
- 通过动态更新归一化统计信息而不依赖反向传播,从而最小化计算成本,这使得LeanTTA避免了对大批量数据和历史数据的依赖,使其在实际部署场景中更加鲁棒。
- 实验效果
- 在多种传感器模态上验证了该框架,结果表明其性能显著优于现有的最先进的TTA方法,包括错误率降低15.7%,ResNet18的峰值内存使用量仅为11.2MB,以及在设备上的适应速度接近正常推理速度一个数量级。
- LeanTTA为在边缘部署中实现精度与系统效率之间的平衡提供了稳健的解决方案,解决了由数据有限和操作条件多样化带来的独特挑战。
1. 引言
-
边缘环境中域偏移问题
- 边缘部署模型场景中,通常只有一个单一的关键数据点可用——例如某片森林中的一段稀有鸟类视频,或某个特定患者的单次测量结果;数据分布可能会突然变化。
- 在实验室或诊所中收集的数据上训练的模型可能无法预测野外环境中的多样化条件,这可能导致高错误率。
- 即使是大型深度学习模型,在面对之前未见过的数据分布时,其准确性也可能显著下降(Liang等,2023);而为了节省内存和计算量被压缩的边缘部署模型,其泛化能力甚至更差
-
边缘设备上 TTA 挑战
- 1)基于反向传播的归一化层优化对资源受限的设备造成了严重负担,需要显著增加内存和功耗。
- 2)边缘设备上的数据可用性,许多TTA方法在时间相关性或有限数据的情况下表现非常差。不仅内存限制了批量大小,而且在低频推理场景中,数据是间歇性捕获的,每次分布变化可能只有一个数据点,总体数据点也很少。大多数TTA方法在小批量数据和移动部署中典型的快速变化域下会导致模型崩溃,并且无法单独适应从不同域收集的数据实例。
-
本文方法 - LeanTTA
- 一种新颖的无需反向传播、无状态且量化的TTA方法,专为边缘设备设计,该方法通过动态更新量化模型的归一化统计信息来实现适应。
- 具体来说:
- (1) 作者提出了一种无需反向传播的TTA模块,能够适应每个未标记的数据点,而不依赖于先前数据的可用性或连续性。
- (2) 为了使模块在不过度依赖输入信息的情况下适应不同的分布变化,作者提出了一种基于训练时统计信息与稳定输入统计信息之间的单样本差异的无状态统计更新机制。
- (3) 提出了分层更新与自适应融合的组合方法,这是一种新颖的结合方式,能够通过量化模型实现快速适应,并提供了关于层深度如何影响适应效果的新见解。
2 相关工作
2.1 传统 TTA 方法
- 传统TTA局限
- Tent 中 固有的限制性数据假设 削弱了其在实际应用中的鲁棒性。
- CoTTA 解决了 灾难性遗忘和连续分布变化 的问题。
- NOTE 和 RoTTA 都通过保留一批数据来模拟 i.i.d. 数据,即使在 非i.i.d. 条件下也是如此。
- 这些方法依赖于基于熵损失的反向传播,这意味着其准确性提升可能依赖于所使用的优化器和超参数;此外,熵损失还可能导致模型崩溃。由于依赖反向传播,这些方法与Tent一样,在内存消耗方面远高于标准推理。
2.2 内存高效的 TTA 方法
- 一些内存高效的TTA方法试图减少反向传播的深度或频率
- EATA 和 SAR 选择性地进行反向传播,以降低计算需求并避免噪声梯度的影响。
- MECTA 则通过结合剪枝和选择性训练的方法来提高内存效率。
- 然而,对反向传播的依赖意味着,对于上述所有方法,其最坏情况下的计算成本仍然与Tent相当,并且如果将其量化并部署到设备上,可能涉及复杂的实现过程。
2.3 无反向传播的 TTA 方法
-
仅推理的适应方法构成了TTA方法的一个分支。
- 由于无需反向传播,其内存和能耗与推理处于同一数量级。
- Li 提出直接用目标数据的整体统计信息更新模型归一化层中的冻结源统计信息。
- Benz 仅利用小批量目标统计信息,但当批量大小接近1时,该方法会失效。
- Schneider 通过使用源统计信息和目标统计信息的加权平均值,减少了所需的目标数据量。SITA 和 InTEnt 分别使用特征增强和超参数空间中的熵加权积分,进一步将目标数据需求减少到单张图像,但这些方法每次适应都需要多次通过整个模型。
- FOA 实现了仅前向传播的适应,但它是针对ViT模型设计的,并且仍然需要大批次数据或缓存的历史数据。
- RealisticTTA 采用了一种不同的方法,涉及两次前向传播,以牺牲超参数搜索为代价,在批量大小为1的情况下需要大约1,000张测试图像的长时间预热期。
-
LeanTTA优势
- 与其他方法一样,LeanTTA 无需反向传播;然而,它避免了集成或数据增强,并能够动态地逐数据点进行适应,即使这些数据点来自完全不同领域——且不依赖于批量大小或先前的数据。
- 统计信息稳定策略消除了长时间预热期的需求,而逐数据点的重置机制则杜绝了长期模型崩溃的可能性。
- 最后,LeanTTA通过在模型的一部分上进行适应并将非适应层融合,在提高准确性的同时提升了计算效率。
3 方法
3.1 问题描述
将 TTA问题形式化如下:
(训练数据) 给定一个模型 f_\theta(x) ,它在源数据集上进行训练,输入和标签为 x_s, y_s ,这些数据是从联合概率分布 P_{\text{source}}(x_s, y_s) 中采样的。
(测试数据) 在测试时,具有参数 \theta 的模型 f_\theta(x) 会遇到输入 x_t ,其标签 y_t 未知,其中 x_t, y_t 分布在 P_{\text{target}}(x_t, y_t) 上,并且 P_{\text{target}}(x_t, y_t) 可能已经偏离了 P_{\text{source}}(x_s, y_s) 。
(TTA 过程) 模型 f_\theta(x) 必须仅通过访问 x_t 来适应 P_{\text{source}} 和 P_{\text{target}} 之间的任何差异。对于边缘设备上的实际部署,还必须适用于从浮点精度(32位)压缩到整数精度(8位)的模型。
边缘设备 TTA 目标:
- 能够适应稀缺数据,需要有限的超参数调整,并能在不同模态下良好运行。
- 在实际场景中遇到的数据不太可能完全匹配有限训练数据的分布,TTA方法应具有广泛的适用性。
- 轻量级、量化兼容、低延迟、内存高效,并且相对于正常推理消耗较少的功耗。
3.2 LeanTTA
所提出的LeanTTA方法如图2所示。给定一个预训练模型,系统通过对目标域统计信息更新和调整归一化层,同时保持其在源域上的性能。这一过程包含四个关键步骤:
- 提取并稳定输入的统计信息;
- 计算样本差异;
- 平衡源域和目标域的统计信息;
- 对模型进行归一化并重置,以适应下一个样本,且完全避免了模型崩溃的可能性。
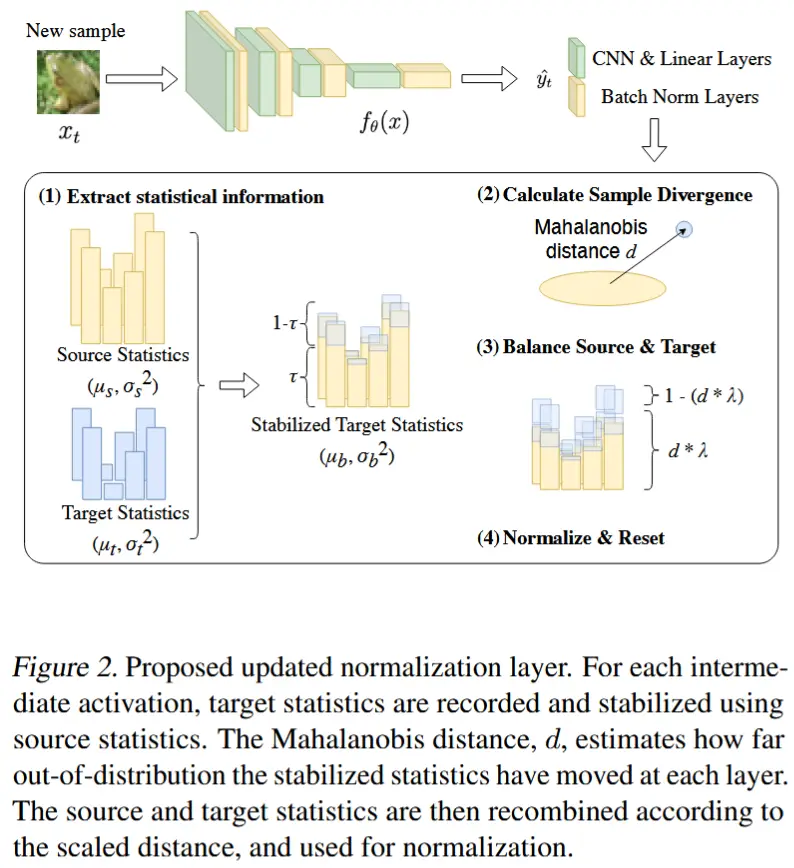
3.2.1 提取统计信息
(测试样本的统计均值方差) 本文方法旨在适应单个数据实例在未知分布变化下的情况,从而在连续和急剧变化的域中提升性能。该过程首先从输入数据 x_t^l 中提取统计信息。按特征计算均值 ( \mu_t )和方差 ( \sigma_t^2 ),如下所示:
其中,H 和 W 分别表示输入数据的高度和宽度。
(与源/训练样本统计信息平均)这些目标统计信息与源统计信息 (\mu_s, \sigma_s^2) 使用加权平均进行组合,参数化为 \tau ,以稳定目标统计信息:
图 3 是在无偏移CIFAR10数据集上从单个 ResNet18 层记录的 mean 和 variance:
- 蓝线Instance是对单个图像进行统计信息,这种做法高度不稳定,会迅速降低准确性。
- 粉线Stabilized表示依赖于先前的数据,不依赖目标统计信息。
- 橙线Moving首先使用原始训练统计信息来稳定输入的统计信息,通过模拟动量(使用 \tau = 0.9)而不依赖先前数据。
这图没看太懂,上面的解释不一定对。。。
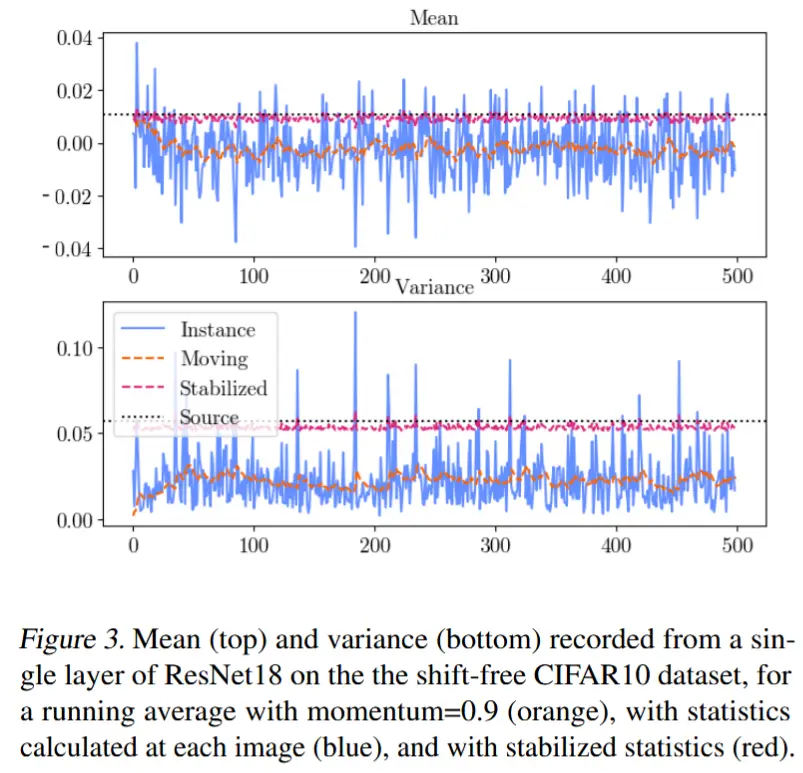
(引入权重参数平衡源和目标)\tau 是一个介于0和1之间的参数,决定了分配给源统计信息 ( \tau ) 和目标统计信息 ( 1 - \tau ) 的权重。这种平衡允许根据 \tau 实现精细的稳定性调整。
作者发现,在不同的数据集和模型上, \tau = 0.9 可以稳定统计信息,使得如果 \lambda (图2 & 3.2.3节出现)足够高,则不仅准确性会增加,而且在分布变化时也不会下降,相对于 \tau = 1 (不依赖目标统计信息)的情况。其他选择可能会在不同级别的分布变化下获得更高的准确性,但需要对变化的性质有预见性。
3.2.2 计算样本差异
(引入Mahalanobis距离描述样本差异) 为了有效适应单个数据点,计算马哈拉诺比斯距离 d ,该方法最近已被广泛应用于许多最先进的(SOTA)分布外检测任务,以衡量源分布与当前稳定后的目标分布之间的差异:
其中,(\mu_b - \mu_s)^T (\Sigma_s^2)^{-1} (\mu_b - \mu_s) 计算平方马哈拉诺比斯距离,同时考虑了源分布的方差和均值。指数函数将该距离转换为一个范围在 0 到 1 之间的度量,然后从 1 中减去该值,使得 d 成为一种差异度量,其中较大的值表示更大的分布变化。\Sigma_s^2 是对角方差矩阵,并且可以高效地求逆。
3.2.3 平衡源域和目标域
(引入Mahalanobis距离平衡源与输入) 马哈拉诺比斯距离(Mahalanobis distance)指示分布变化的严重程度,从而决定是更多地重视源统计信息还是稳定后的输入统计信息。对于严重的分布变化,更多地强调源统计信息;而对于较轻微的分布变化,则更多地强调稳定后的输入统计信息。
在这里,将 \lambda 设置为一个平衡参数,以确保即使马哈拉诺比斯距离 d 为1时,仍会部分纳入目标统计信息,从而提高准确性,并确保源统计信息与目标统计信息之间的平滑过渡。
这里作者引入的三个参数好像都是用来平衡源与目标样本之间的权重,公式 (3 4 5 6 7) ,包括\tau d \lambda 。注意这个过程出现了三个均值和方差,分别是 \mu_s \mu_b \mu_{new},从图2可以更清楚的看明白顺序关系。
3.2.4. 归一化和重置
最后一步涉及使用更新的统计数据对输入数据 x^l_t 进行归一化,从而得到输出 x^{l+1}_t :
在每个数据实例上重置模型,防止灾难性遗忘,并确保在不同数据分布变化下具有鲁棒性能。
因此,本文的方法设计为仅前向传播且量化兼容,非常适合资源受限的设备。它只需要一次批量大小为 1 的前向传播即可提高 TTA 准确率。随着每个数据实例通过模型的归一化层,统计信息会依次更新。一旦某一层计算出中间表示,统计信息就会立即重置,为下一个数据点做好准备。
3.3 部分融合策略
融合:指的是将多个操作或层合并成一个更高效的计算单元。这是为了减少计算开销和内存占用,特别是在资源受限的设备上。在卷积神经网络中,常见的融合是对 Convolutional Layer 和 Batch Normalization Layer 进行融合。
当 TTA 被量化时,它们需要在设备上进行真实的量化训练,而这通常在没有专门设计的内核支持稳定训练的情况下是不可行的。(即需要量化后进行微调 QAT)
本文提出了一种适用于任何预训练模型的部分融合量化TTA策略。不仅避免了对专门设计内核的依赖,还进一步提升了LeanTTA的效率。灵感来源于图4的结果:更新模型的前半部分在不同架构和数据集上能够达到与更新整个模型相似或更高的准确性。 根据算法1(步骤1-8),给定架构中未融合层的集合,仅融合较深层的部分,然后基于3.2节的TTA方法更新未融合的层。
总结部分融合策略:融合较深层的部分(参数固定),浅层用 TTA 更新。
这一策略进一步提高了LeanTTA更新步骤的计算效率,因为使用QNNPACK(当前ARM架构支持的量化引擎)时,未融合层的运行速度比融合层更慢。此外,融合层不需要存储BN层参数和激活值以用于更新步骤。

4. 结果与讨论
4.1 实验设置
-
数据集
- 图像:CIFAR10-C、CIFAR100-C
- 音频数据集:BirdVox-DCASE20k和Warblr(鸟类鸣叫检测任务)。使用BirdVox预训练,并使用Warblr测试其在剧烈分布变化下的表现。
-
模型
- 图像模态:MobileNetV2 和 ResNet18
- 音频模态:VGGish
- 为了强调在不同模型架构上的适应性,并突出其在处理复杂性不断增加的数据集时的鲁棒性。
-
剧烈分布变化
- 为了模拟真实场景中剧烈变化的分布,作者使用了两个数据集:(1) 随机打乱分布类型和严重程度级别的 CIFAR10-C 和 CIFAR100-C。(2) 在多样化条件下由不同传感器间歇性收集的 Warblr 数据集。
-
渐变分布变化
- 在这种情况下,数据的分布缓慢变化,从严重级别1到5,再从5回到1,然后进入下一个域。使用CIFAR10/100-C数据集来模拟这种情况。
-
基线方法
- Tent、CoTTA、EATA、RealisticTTA
-
设备
- 对于系统测量,使用了Raspberry Pi Zero 2W,配备4GB的交换内存。
- 测量端到端延迟并通过功率记录设备估算能耗。
-
量化
- 量化模型是使用PyTorch中的QNNPACK后端生成的;静态量化后的比例因子和零点是在来自CIFAR10/CIFAR100训练数据集的100个批量大小为64的数据上记录的。必要时,对相邻的卷积层和批归一化层进行了层融合。
4.2 LeanTTA 的准确性提升
4.2.1 剧烈变化的领域
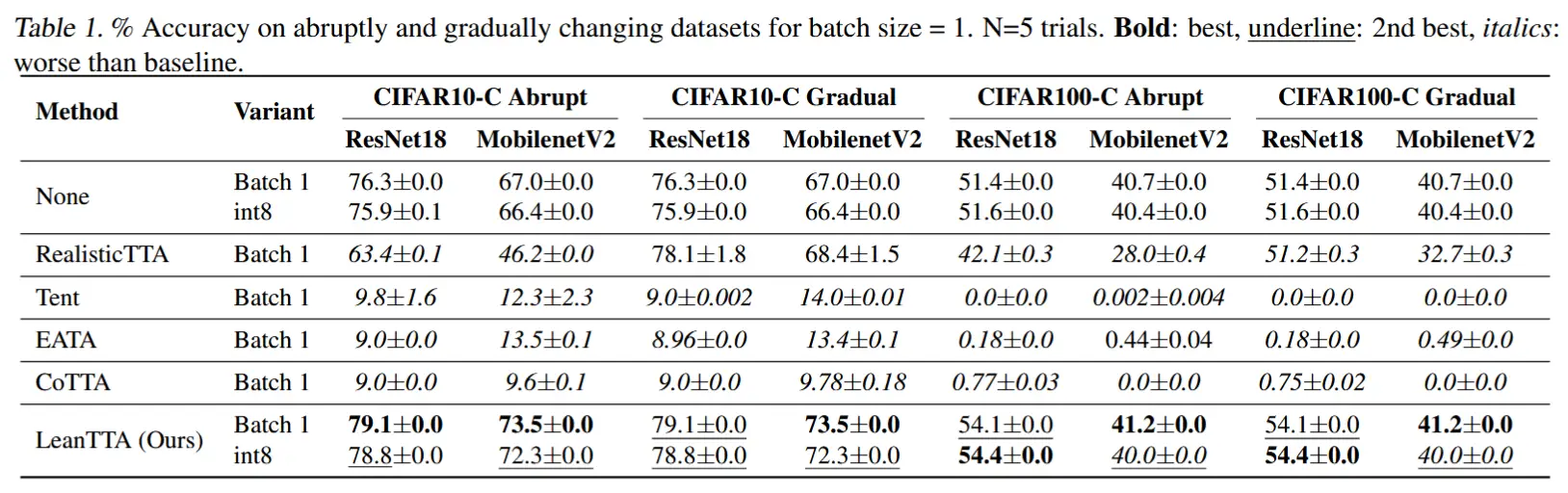
- 剧烈分布变化、batch=1、图像模态 - 表1 Abrupt 列
- LeanTTA全方面领先,并且对基线模型性能都有提升。
- 在无历史信息、单批次数据集中,大多数方法都崩溃了,其准确性接近随机猜测。
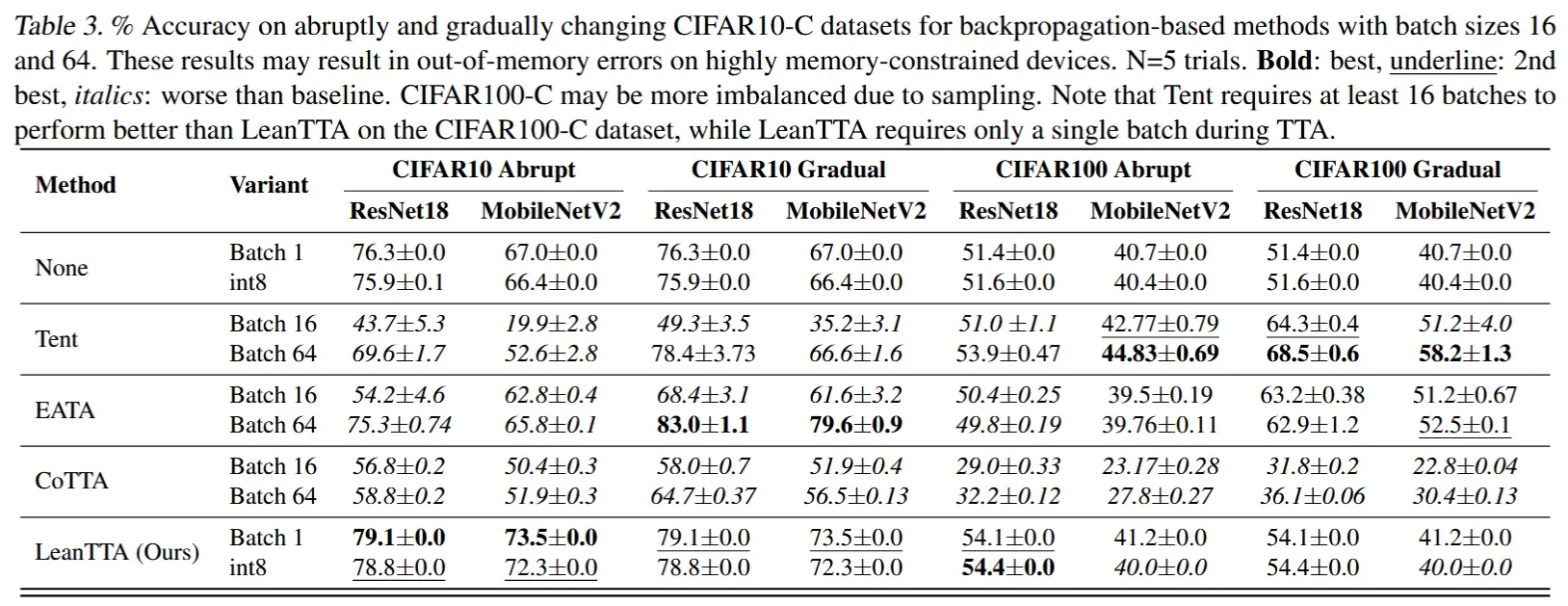
- 剧烈分布变化、大batch、音频模态 - 表3
- 在批量大小为 64 的情况下,大多数方法仍无法超越无适应的基线准确性。
- LeanTTA 则始终能够提高准确性。
4.2.2 渐变分布变化
- 表1 和 表3 Gradual 列
- 虽然当batch较大时,LeanTTA 提升幅度不如基于反向传播的方法 Tent 和 EATA,但是这不适合资源受限的边缘设备,
- RealisticTTA 的表现也不错,但需要较长的预热期,并且具有较高的延迟。
表1 和表3 见第4.2.1节。
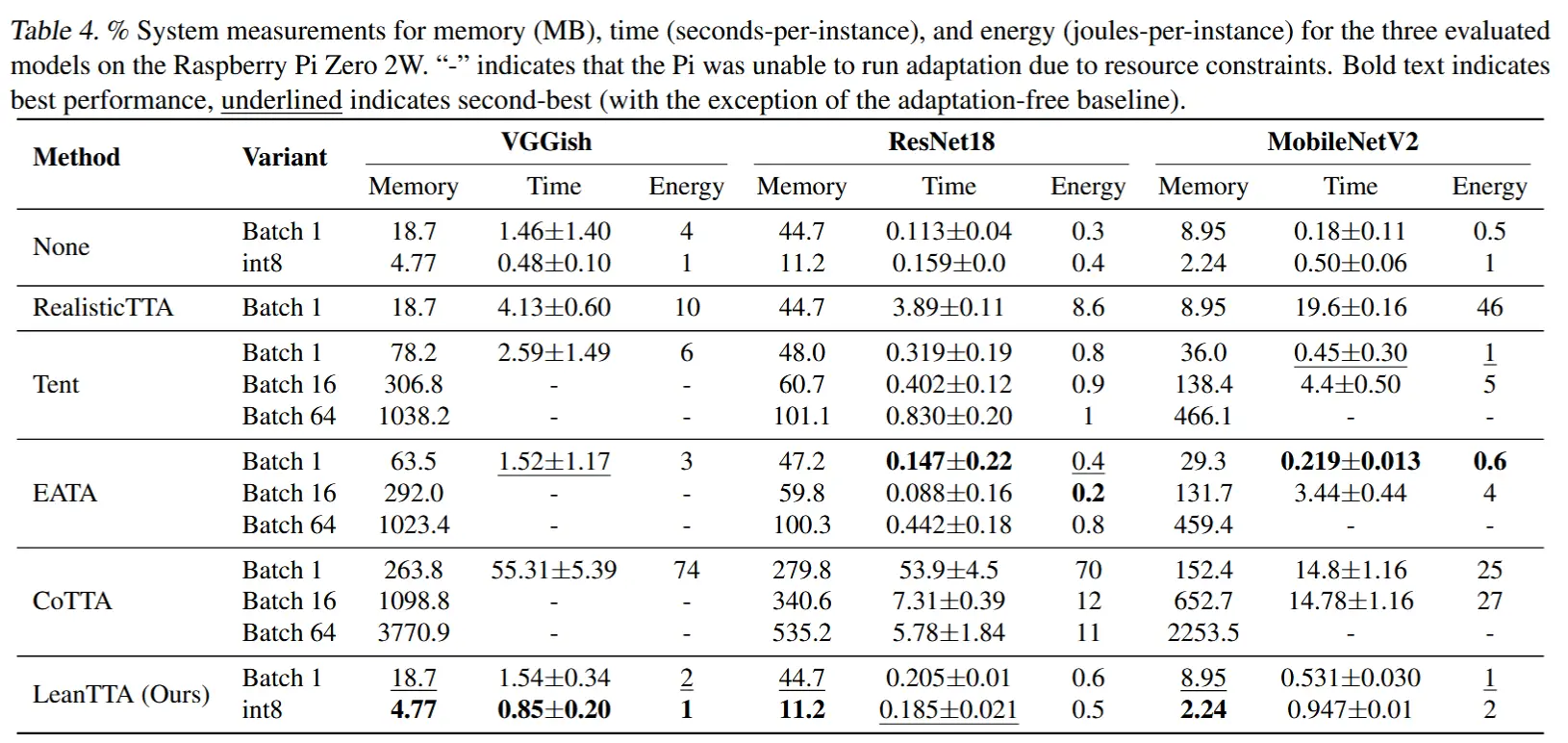
4.3 系统评估
- 表4
- 评估延迟和内存使用情况。
- 虽然 LeanTTA 不是最佳的,但是比它好的要么无法提高准确率,要么是需要大批次导致内存溢出。
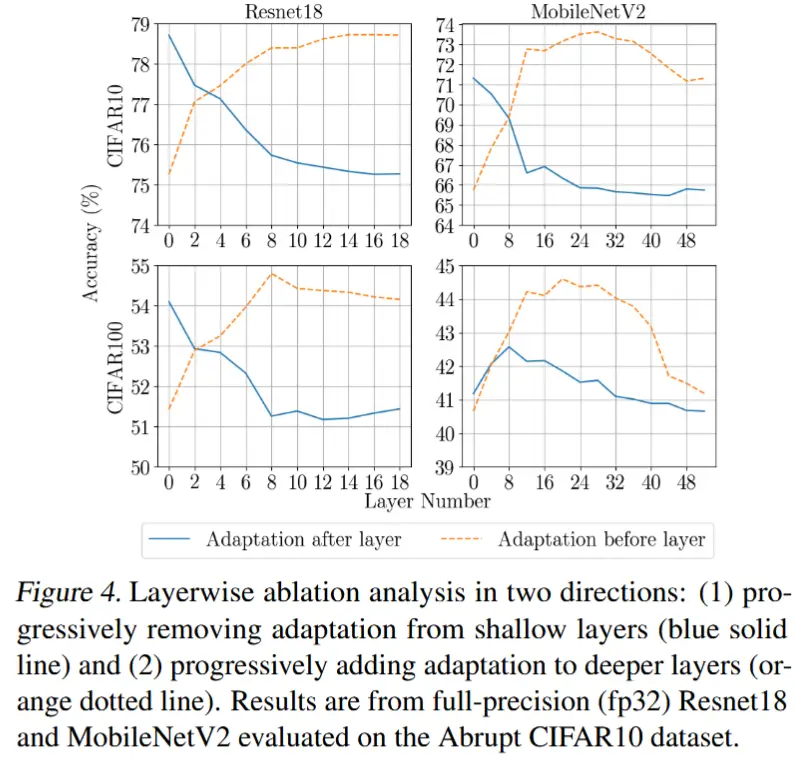
4.4 层对适应的影响
- 将适应限制在某些层可以进一步提高系统效率——尤其是在量化模型的情况下,仅适应某些层使我们能够将剩余的层融合为量化过程的一部分。
- 图4
- 展示了去除靠近输入的浅层(蓝色实线)或靠近输出的深层(橙色虚线) 对适应效果的影响。
- 去除深层的适应有时并不会显著降低准确性,甚至可能提高准确性。然而,去除浅层的适应会导致准确性提升幅度较低,这表明浅层对适应更为重要。
- 推测/归因:深层专注于更大规模的结构,而浅层学习的是通用模式和组件。
- 图5
- 融合带来的延迟减少
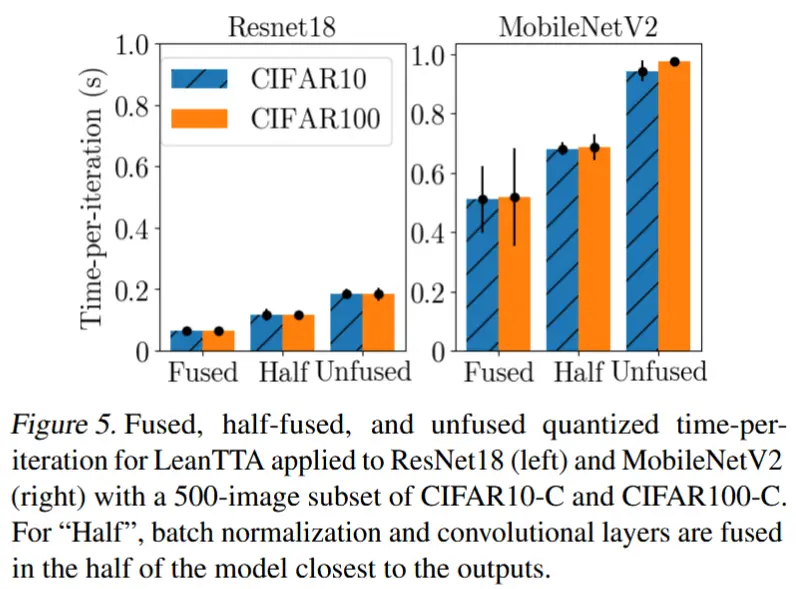
4.5 超参数
超参数搜索表明,通过保守地靠近源统计权重,LeanTTA方法很可能会减少分布变化误差,或者至少不会降低准确性。在图7中,可以看到,将 \tau 和 \lambda 都保持为0.9通常会使准确性高于 \tau = 1.0 和 \lambda = 1.0 的情况(即右下角的方块,代表没有 adaptation 的推理情况)。
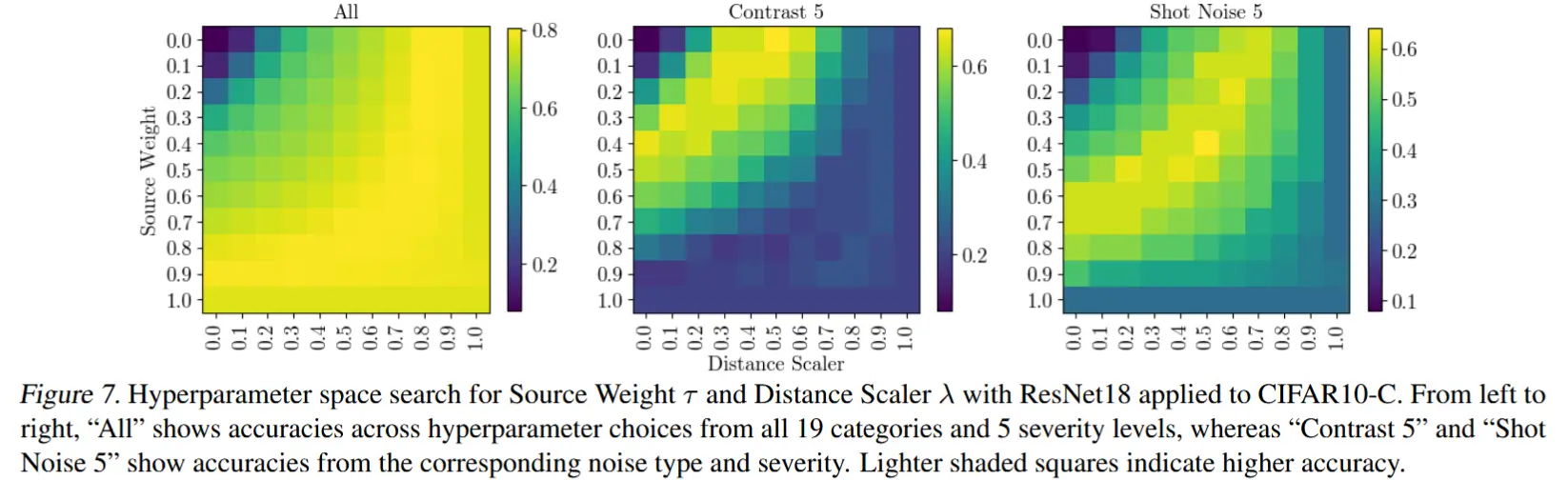
如图7,不同情况其实最优超参数不同,但是一般TTA工作都是静态的超参数,因为测试/目标样本的分布是未知的。
5 结论
受现有TTA方法在低资源设备上部署量化模型时的无效性以及其在多样化、实际稀缺数据场景下的不佳表现的启发,作者提出了LeanTTA,这是一种在设备端TTA领域的创新突破。LeanTTA在边缘部署中具有低数据、低内存、低功耗的挑战性环境下始终能够提高准确性。LeanTTA基于马哈拉诺比斯距离测量的单样本分布变化严重程度,动态独立地分析每个输入数据点,而无需维护历史数据或大批量数据。由于其逐层特性,LeanTTA还支持与量化模块融合相结合的适应,进一步优化了作者提出的量化TTA的系统效率,同时也为层深度对适应的重要性提供了见解。在数据稀缺、快速变化的分布下,LeanTTA避免了模型崩溃,在超越现有最先进方法的同时减少了延迟和内存消耗。