本文主要关注deepseek v3架构和推理方面的知识,对于预训练和后训练方面后续有需要再完善。
摘要
- DeepSeek-V3,一款强大的混合专家MoE语言模型,671B参数,其中每个token激活37B参数。
- 为了实现高效推理和成本优化的训练,V3采用了多头潜在注意力MLA和DeepSeekMoE架构。此外,V3首次引入了一种无辅助损失的负载均衡策略,并设定了多token策略训练目标,以提升模型性能。
- 使用 14.8 trillion 份多样化且高质量的 tokens 预训练,随后使用监督微调SFT和强化学习进一步后训练加强。
1 介绍
-
DeepSeek-V3继承了V2的 MLA和DeepSeekMoE 架构,同时引入了两项额外策略进一步提升模型能力:
- 无辅助损失(auxiliary-loss-free) 负载均衡策略,旨在 减少负载均衡优化对模型性能的潜在负面影响。
- 多 token 预测训练目标,该策略在评测基准上能够 提升整体性能。
-
为了实现高效训练,V3引入了以下措施:
- FP8:首次在超大规模模型上验证了 FP8混合精度训练 框架的有效性,实现了 训练加速和GPU内存占用减少。
- 优化训练框架:使用 DualPipe 算法 实现高效流水线并行,该算法能够减少流水线 bubbles,通过计算-通信重叠隐藏大部分训练过程中的通信开销。确保了随着模型规模扩大,只要维持恒定的计算-通信比,就能在跨节点使用细粒度专家的同时,保持接近零的 all-to-all 通信开销。
- 高效的跨节点 all-to-all 通信内核: V3训练框架还定制了高效的跨节点all-to-all通信内核,以充分利用InfiniBand和NVLink带宽。
- 内存占用精细优化: 使得 DeepSeek-V3 的训练无需依赖昂贵的张量并行。
-
预训练过程十分稳定 -> 两阶段上下文长度扩展秩128K -> 后训练(监督微调+强化学习)
-
基准测试
- 当前最强的开源基础模型,尤其在代码和数学任务上。
- Chat version 优于其他开源,与闭源相当性能。
-
经济成本分析略过,整体训练成本为2.788M H800 GPU 小时。
-
贡献总结
- 架构:创新的负载均衡策略与训练目标
- 首创无辅助损失负载均衡策略,有效 减少因负载均衡优化导致的性能下降。
- 研究了多 token 预测目标,并 验证了其对模型性能的提升作用。此外,该方法还可用于 推理加速中的推测解码。
- 预训练:迈向终极训练效率
- FP8 混合精度训练框架。
- 通过 算法、框架和硬件的协同设计,我们 克服了跨节点 MoE 训练的通信瓶颈,实现了 近乎完全的计算-通信重叠,使得能够在无额外开销的情况下进一步扩展模型规模。
- 经济成本极低。
- 后训练:从 DeepSeek-R1 进行知识蒸馏
- 引入了一种创新方法,将 长链式思维 CoT 模型 (DeepSeek-R1系列之一)的 推理能力 蒸馏到标准大模型(DeepSeek-V3)。
- 训练流程优雅的融合了R1的 验证和反思模型 到V3,显著提高其推理能力。
- 精确的控制了V3的输出风格和长度。
- 测评结果
- 略
- 略
- 架构:创新的负载均衡策略与训练目标
2 架构
2.1 基本架构
- 如下图,V3仍然基于Transformer框架,与V2的架构一样使用 MLA 和 DeepSeekMoE。

2.1.1 MLA
- MLA 的核心是对注意力 keys和values 进行低秩联合压缩,以减少推理过程中 KV缓存 的使用。
- 理解MLA的核心就是理解下列公式和前面的图片
- Query
- (37) 中,低秩压缩,c^Q_t 是 Queries 的压缩潜在向量 (compressed latent vector),h_t 是隐藏层第t个token的注意力输入,W^{DQ} 是下投影矩阵。
- (38)中,将37中的结果乘上上投影矩阵 W^{UQ},得到 q^C_t
- (39)中,将37中的结果进行RoPE位置编码,得到 q^R_t
- (40)中,将38和39的结果分别进行拼接,得到了第t个token的Q矩阵 q_{t,i}
- Key 和 Value
- (41)中,低秩压缩,h_t 乘下投影矩阵 W^{DKV} ,得到Key和Value的压缩潜在向量 c_t^{KV}
- (42)中,将41的压缩潜在向量乘上投影矩阵 W^{UK} ,得到 k^R_t
- (43)中,RoPE位置编码,注意这里是使用 h_t 进行位置编码,得到 k^R_t
- (44)中,将42和43结果拼接,得到Key矩阵 k_{t,i}
- (45)中,将41的压缩潜在向量乘上投影矩阵 W^{UV} ,得到Value矩阵 v^C_t
- (46)(47)Softmax和Output计算
- Query

-
需要注意的是只有(41)和(43)中框中蓝色变量需要缓存,这显著减少了KV缓存的大小。
-
细节问题
2.1.2 DeepSeekMoE
- 基本架构
- 与传统MoE架构不同之处:DeepSeekMoE 使用了更细粒度的专家,并将一些专家独立出来作为共享专家。
- 设 u_t为第t个token的FFN输入,通过以下公式计算FFN输出h_t'
- 其中,N_s和N_r分别表示共享专家和路由专家的数量;FFN_i^{(s)}(·) 和 FFN_i^{(r)}(·) 分别表示第 i 个共享专家和第 i 个路由专家;K_r表示激活的路由专家数量;g_{i,t} 是第 i 个专家的门控值;s_{i,t} 是 token 与专家的亲和度;e_i 是第 i 个路由专家的质心向量;Topk(·), K 表示在为第 t 个 token 和所有路由专家计算的亲和度分数中,选出 K 个最高分的集合。
- 与 DeepSeek-V2 略有不同,DeepSeek-V3 使用 sigmoid 函数来计算亲和度分数,并对所有选中的亲和度分数进行 归一化 ,以生成门控值。

-
无辅助损失负载均衡策略
- 对于 MoE 模型,专家负载不均衡会导致路由崩溃,并在专家并行的场景中降低计算效率。传统的解决方案通常依赖于辅助损失来避免负载不均衡。然而,过大的辅助损失会损害模型性能。
- 为了在负载均衡和模型性能之间取得更好的平衡,我们开创了一种无辅助损失的负载均衡策略,以确保负载均衡。具体来说,我们为每个专家引入一个偏置项b_i,并将其添加到相应的亲和度分数s_{i,t} 中,以确定 top-K 路由。
- g_{i,t}' = \begin{cases} s_{i,t} ,&s_{i,t} + b_i \in Topk({s_{j,t} + b_j |1 \leq j \leq Nr }, K_r), \\ 0,& otherwise.\end{cases}
- 与(14)对比,可知偏置项仅用于路由选择,而门控值仍然来自原始的亲和力分数。
- 偏置值动态调整:在训练过程中持续监控整个批次中每个训练步骤的专家负载,如果过载则减少\gamma,如果负载不足则增加\gamma。
-
互补的序列级辅助损失
- 尽管 DeepSeek-V3 主要依赖于无辅助损失的负载均衡策略,但为了防止单个序列内的极端不平衡,我们还采用了互补的序列级负载均衡损失:

-
其中,平衡因子 \alpha 是一个超参数,对于 DeepSeek-V3,将为其分配一个极小的值;\mathbf{1}(·) 表示指示函数;T 表示序列中的标记数量。
-
序列级负载均衡损失鼓励每个序列中的专家负载保持平衡。
-
除了上述机制,还有
- 节点限制路由:确保每个token最多只会发送到M个节点,选择亲和度最高的前**K_r / M**个专家。
- 无Token-Dropping:由于有效的负载均衡,V3在训练和推理过程不会丢弃任何token。
2.2 多 Token 预测 MTP(仅训练时开启)
-
MTP优点
- MTP目标密集化了训练信号,并可能提高数据效率。
- MTP可能使模型能够预先规划其表示,从而更好地预测未来的token。
-
如下图展示了MTP实现
- 与Gloeckle等人(2024年)不同,他们通过独立的输出头并行预测D个额外token,而 DS-V3 则是 顺序预测额外token,并在每个预测深度保持完整的因果链条。
- 需要注意的是,图中绿色部分 嵌入层和输出头 是 共享 的。

-
MTP 模块
-
使用D个顺序模块来预测D个额外的token。
-
第k个MTP模块由一个共享的嵌入层 Emb(·),一个共享的输出头 OutHead(·),一个Transformer块 TRM_k(·) 和一个投影矩阵 M_k \in R^{d×2d} 组成。
-
第i个输入token t_i,在第k个预测深度,我们首先将第 (i+k) 个token的嵌入 Emb(t_{i+k}) \in R_d 与第 i 个token在第(k−1)深度的表示 h^{k−1}_i \in R_d 结合,并进行线性投影:h^{'k}_i = M_k [RMSNorm(h^{k−1}_i); RMSNorm(Emb(t_{i+k}))]
- 其中,[· ; ·]表示连接。
-
当k=1时,h^{k-1}_i 指的是主模型给出的表现形式。结合之后的 h^{'k}_i 作为第k深度的Transformer块的输入,用于生成当前层的输出表示: h^k_{1:T-k} = TRM_k(H^{'k}_{1:T-k}) ,
- 其中T 表示输入序列的长度,i:j 表示切片操作。
-
最后,以 h^k_i 作为输入,共享的输出头将计算第 k 个额外预测 token 的概率分布 P^k_{i+1+k} \in R^V,其中 V 是词汇表大小: P^k_{i+k+1} = OutHead(h^k_i)
- 输出头 OutHead(·) 将表示线性映射为 logits,随后应用 Softmax(·) 函数计算第 k 个额外 token 的预测概率。
-
-
MTP 训练目标
- 对于每个预测深度,计算一个交叉熵损失:

-
其中,T代表输入序列长度的长度,t_i表示第 i 个位置的真实 token,P^k_i[t_i]表示由第 k 个 MTP 模块给出的 t_i 的对应预测概率。最后,我们计算 所有深度的 MTP 损失的平均值,并乘以权重因子 λ,得到整体的 MTP 损失 LMTP,作为 DeepSeek-V3 的 额外训练目标。
-
MTP 推理时
- MTP 策略主要旨在提高主模型的性能,因此在推理过程中,可以直接丢弃 MTP 模块,主模型可以独立且正常地运行。此外,我们还可以将这些 MTP 模块重新用于 推测解码,以进一步降低生成延迟。
- MTP 策略主要旨在提高主模型的性能,因此在推理过程中,可以直接丢弃 MTP 模块,主模型可以独立且正常地运行。此外,我们还可以将这些 MTP 模块重新用于 推测解码,以进一步降低生成延迟。
3 Infrastructures
3.1 计算集群
- DeepSeek-V3 在配备 2048 个 NVIDIA H800 GPU 的集群上进行训练。
3.2 训练框架(略)
- HAI-LLM
- 采用了16路流水线并行、跨越8个节点的64路专家并行、ZeRO-1数据并行。
- 设计了DualPipe算法以进行高效的流水线并行。它在前向和反向过程中重叠了计算和通信阶段,从而解决了跨节点专家并行引入的沉重通信开销问题。
- 开发了高效的跨节点全对全通信内核,以充分利用 IB 和 NVLink 带宽,并节省用于通信的流式多处理器(SMs)。
- 细致地优化了训练期间的内存占用,从而能够在不需要使用昂贵的张量并行(TP)的情况下训练 DeepSeek-V3。
3.3 FP8 训练(略)
3.4 推理和部署
- 为了同时确保在线服务的服务级别目标(SLO)和高吞吐量,我们采用了以下部署策略,将 预填充和解码阶段分开。
3.4.1 预填充
-
预填充阶段的最小部署单元由 4 个节点和 32 个 GPU 组成。
- 注意力部分,采用 4 路张量并行和序列并行,并结合 8 路数据并行。
- MoE部分,32路专家并行。对于 MoE 全对多通信,首先通过 IB 跨节点传输 token,然后通过 NVLink 在节点内 GPU 之间转发。
- 浅层的密集 MLP 中,使用 1 路张量并行,以节省 TP 通信。
-
冗余部署高负载专家
- 目的:为了实现 MoE 部分中不同专家之间的 负载均衡,我们需要确保每个 GPU 处理大致相同数量的 token。为此,我们引入了冗余专家的部署策略。
- 核心思想:复制高负载专家并冗余部署它们。
- 方法:通过 在线部署期间收集统计数据,根据数据在节点内的GPU之间重新安排专家,尽可能平衡GPU之间的负载,同时不增加跨节点all-to-all开销。
- 在 DeepSeek-V3 的部署中,我们为预填充阶段设置了 32 个冗余专家。对于每个 GPU,除了其原本托管的 8 个专家外,还将托管一个额外的冗余专家。
-
重叠两个批次
- 方法:同时处理两个计算工作量相似的微批次,将一个微批次的注意力和 MoE 与另一个微批次的调度和组合重叠。
- 目的:提高吞吐量并隐藏全对全和 TP 通信的开销
-
动态冗余策略
- 方法:每个 GPU 托管更多专家(例如,16 个专家),但在每个推理步骤中只激活 9 个。在每层的全对全操作开始之前,我们会动态计算全局最优的路由方案。
- 方法:每个 GPU 托管更多专家(例如,16 个专家),但在每个推理步骤中只激活 9 个。在每层的全对全操作开始之前,我们会动态计算全局最优的路由方案。
3.4.2 解码
-
解码阶段的最小部署单元由 40 个节点和 320 个 GPU 组成。
- 注意力部分采用 TP4 with SP,结合DP80。
- MoE部分,320路专家并行。每个 GPU 仅托管一个专家,64 个 GPU 负责托管冗余专家和共享专家。调度和组合部分的全对全通信通过 IB 的直接点对点传输实现。
- 利用IBGDA(NVIDIA,2022)技术进一步 减少延迟并提高通信效率。
-
冗余部署高负载专家
- 与预填充阶段类似,我们基于在线服务时专家负载的统计,定期确定冗余专家集合。
- 由于解码阶段每个 GPU 仅托管一个专家,因此不需要重新安排。
- 目前解码阶段的动态冗余策略 还在探索,这需要对计算 全局最优路由方案的算法 进行更细致的优化,并将其与调度内核融合以减少开销。
-
重叠两个批次
- 目的:与预填充一样。
- 区别:解码阶段中注意力计算占据了更多时间。因此,我们将一个微批次的注意力计算与另一个微批次的调度+MoE+组合重叠。
- 流式多处理器(SMs)分配:在解码阶段,每个专家的批量大小相对较小(通常在 256 个 token 以内),瓶颈在于内存访问而非计算。由于 MoE 部分只需加载一个专家的参数,内存访问开销很小,因此使用较少的流式多处理器(SMs)不会显著影响整体性能。因此,为了避免影响注意力部分的计算速度,我们可以仅分配一小部分 SMs 给调度+MoE+组合。
上述部分为《DeepSeek-V3》论文节选,其余部分为预训练和后训练,与推理优化似乎关系不大。
4 DeepSeek-R1 Reasoning 能力
- DeepSeek-R1是基于V3训练来的,模型架构与V3几乎一样,通过使用RL来增强reasoning能力,主要包含以下步骤:
- 冷启动(Cold Start)
- 面向推理的强化学习(Reasoning-oriented Reinforcement Learning)
- 拒绝采样(Rejection Sampling)
- 监督微调(Supervised Fine-Tuning)
- 适用于所有场景的强化学习(Reinforcement Learning for all Scenarios)

- Reasoning 能力从何而来?
- 冷启动,在冷启动阶段使用了少量的 长CoT数据 去微调初始 RL actor,这些CoT数据来自于R1-Zero,并通过人工注释者后处理。
- RL,作者采用和DeepSeek-R1-Zero一样的大规模强化学习训练过程(GRPO),Zero强化学习时奖励函数由准确度、格式构成,其中格式强制模型将其 思维过程置于 '
' 和 ' ' 标签之间,这鼓励了模型进行思考的过程,注意 没有对思考的形式和过程进行规定和奖励( 后续论文还提到 Process Reward Model是不成功的尝试 )。在R1-Zero的奖励函数基础上,R1还引入了语言一致性奖励。 - 拒绝采样,通过从强化学习训练的checkpoint执行拒绝采样**合成推理数据,用于后续的监督微调。通过基于规则的奖励策略(rule-based rewards)、生成式奖励模型(Generative Reward Model),生成了 600,000 份高质量的推理示例。此外,还生成了 200,000 份“非推理”示例,这些示例来自 DeepSeek-V3 的部分SFT数据集。
- 监督微调,使用上述这 800k 样本,对 DeepSeek-V3-Base 进行 SFT 得到最终的DeepSeek-R1。
- 面向所有场景的强化学习**,**这一步主要是旨在提高模型的有用性和无害性。
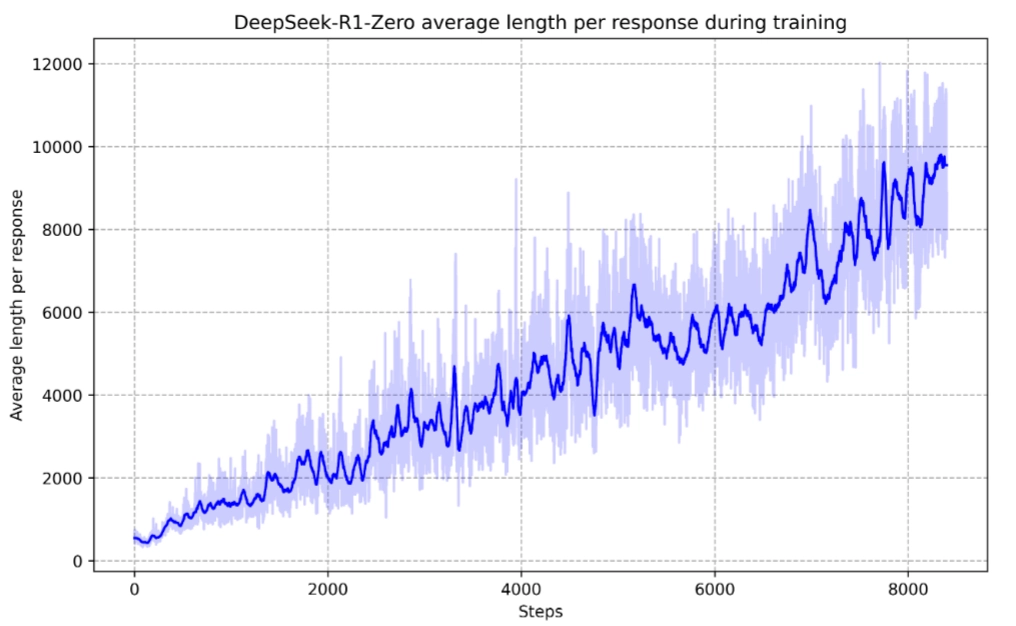
Reasoning 能力总结:从R1的训练过程中可以看到,几乎所有的步骤都是围绕Reasoning展开的,主要是引导模型增加 测试时计算(Test-time compute),模型在训练过程中的平均响应长度自发增加,同时在RL时与环境交互的过程中模型也出现了反射(reflection)、探索替代方法等复杂行为,使得模型的思维过程更加完善和深入。
参考文献
- DeepSeek-V3 Technical Report
- DeepSeek-V2: A Strong, Economical, and Efficient Mixture-of-Experts Language Model
- https://spaces.ac.cn/archives/10091#MLA
- DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning
- https://zhuanlan.zhihu.com/p/24065428139