论文地址-《Agglomerative Federated Learning: Empowering Larger Model Training via End-Edge-Cloud Collaboration》
摘要
- 尽管分层联邦学习HFL支持适合EECC的多层模型聚合,先前的工作在所有计算节点上假设相同的模型结构,通过最弱的中断设备限制模型规模。
- 为了解决这个问题,作者提出了聚合联邦学习FedAgg,这是一种由EECC赋能的FL框架,允许从端、边缘到云的训练模型变得更大,泛化能力更强。
- FedAgg基于桥接样本的在线蒸馏协议BSBODP递归地组织各层之间的计算节点,使得每队父子计算节点能够相互传输和提取从生成的桥样本中提出的知识。
- 开源:https://github.com/wuzhiyuan2000/FedAgg
Ⅰ 介绍
- Agglomerative federated learning
- 具体来说,FedAgg 通过我们定制的基于桥样本的在线蒸馏协议(BSBODP)递归地组织计算节点来协作训练从终端设备、边缘服务器到云服务器规模不断增长的模型,该协议定义了每对父节点之间的交互规则具有树形拓扑的端边云网络中的子计算节点。
- 对于BSBODP,在任何一对父子计算节点中实现与模型无关的协作训练,其中使用预训练的轻量级解码器来生成假样本(称为桥样本),其提取的逻辑用于节点之间的知识蒸馏。
- 第一个由端边缘云协作范式支持的框架,它能够通过不断增加的能力训练更大的模型,直至云端。
Ⅱ 相关工作
- 分层联邦学习
- 分层联邦学习(HFL)由Liu[10]首次提出,所建立的端-边-云FL架构结合了云计算海量数据覆盖和边缘计算低通信延迟的优点。
- 然而,之前工作方法都要求参与的计算节点采用相同的模型结构,这将模型规模限制于终端设备的能力,并且浪费了具有大量计算能力的边缘和云端节点的资源。
- 联邦学习训练大模型
- 流行的FL方法[7]-[9]要求在强大的中央服务器和资源有限的终端设备中采用同质模型,这阻碍了超出终端设备最大能力的更大模型的训练。
- 针对上述问题,先前的工作提出了两种类型的解决方案:一种基于部分训练,另一种基于知识蒸馏。
- 局限:然而,上述方法都是针对两层架构设计的,无法支持端边云网络赋能的协同模型训练。因此,上述工作的适用性受到很大限制。
Ⅲ 初步
A 端边云协作
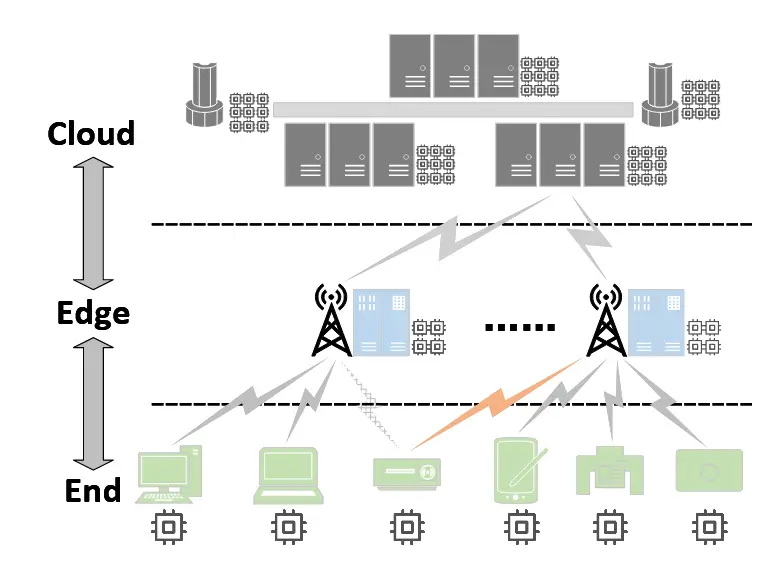
B 端边云协作赋能的分层联邦学习
- 此外,每个节点 v \in V 都拥有一个参数为 W^v 的模型 Model(v),并且能够与其父节点和子节点交换信息,即 {Parent(v)} \cup Child(v) 。我们的目标是获得根节点 Model(r) 中的模型,使其在设备上所有私有数据上的训练损失 L_{train}(·) 最小化,即:
\argmin \limits_{W^r} L_{train}(\cup^K_{k=1}D^k;W^r)
- 为了充分利用异构资源并适应端、边缘和云计算节点的差异化能力,具有强大计算资源的边缘和云服务器应该部署比端设备更大的模型,通过从私有数据中捕获更复杂和更通用的模式来增强性能,而能力有限的端节点上的模型大小应相应减小。
C 联邦学习中的交互协议
- FL中的交互协议是FL系统中计算节点之间的信息交换规则,包括内容传输和参数更新的规则。
- FedAvg
Ⅳ AGGLOMERATIVE 联邦学习
A 动机和概述
-
我们提出了在边缘和云节点上训练比终端设备更大的模型的直观动机,以实现更高的精度和更强的泛化能力。
- 实现这一想法的一种可行方法是进行在线蒸馏作为不同层计算节点之间的交互协议,训练节点之间异构结构的模型。
- 问题:然而,直接将在线蒸馏集成到 EECC 支持的 FL 中可能会引发有关在设备上共享数据的隐私问题,因为需要相同的样本来跨不同计算节点提取 logits。
- 解决办法:为了克服这个问题,我们设计了一种新的交互协议,名为BSBODP,该协议使用虚假数据作为桥梁,在轻量级预训练自动编码器的帮助下跨多级节点传输知识。该虚假数据是由来自编码或接收的嵌入的解码器生成的,允许计算逻辑而不泄露设备上的原始数据。
- EECC采用多层架构,每个节点都可以采用与其自身计算能力相匹配的模型结构,下层节点可以通过BSBODP迭代地将其学习到的表示传递到上层节点。
- 此外,FedAgg 还可以处理任何计算节点在同一层内动态更改其父节点的情况,这确保了现实 EEC-NET 中的部署灵活性。
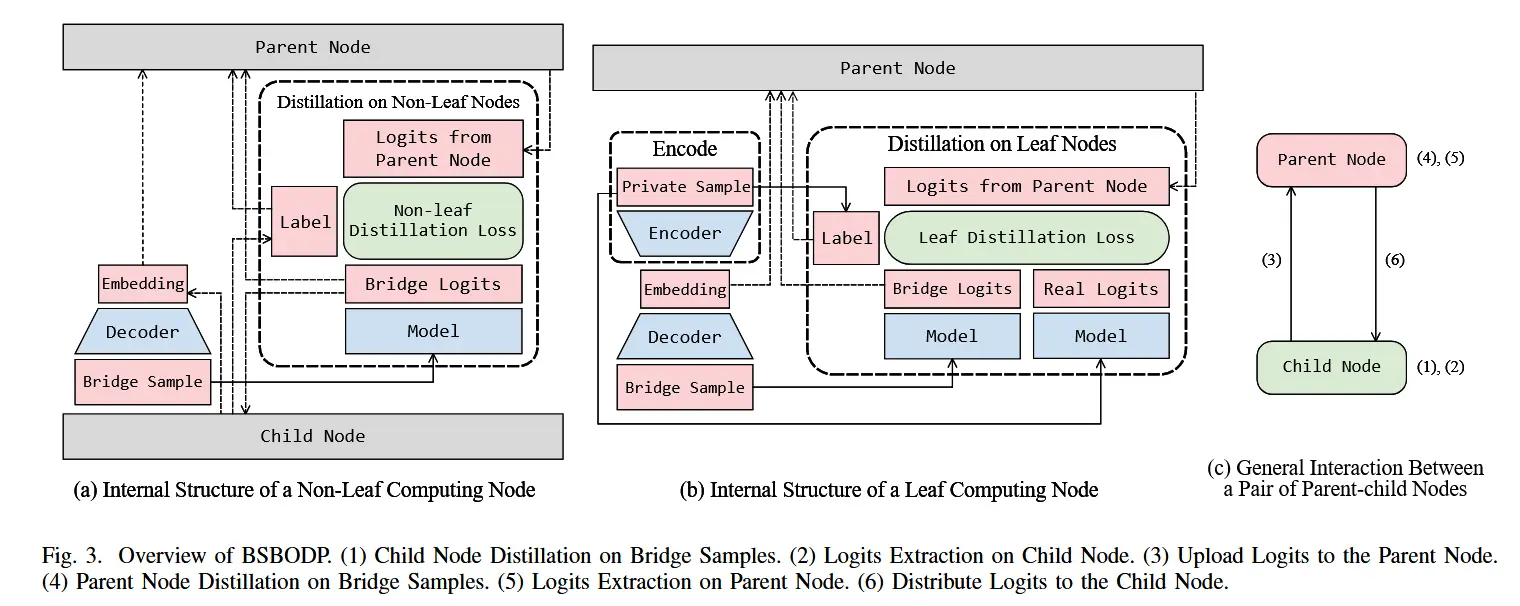
B 基于桥接样本的在线蒸馏协议
- 下图展示了BSBODP的设计
- 每个计算节点保存一个预训练的解码器和一个常规的完整模型(计算节点上要训练的模型)
- 每个叶子计算节点额外保留一个预训练的编码器(与上述解码器形成预训练的自动编码器),用于将本地数据编码为嵌入,该嵌入将被传输到其父节点直至到达根节点。
- 在执行阶段,每个计算节点利用解码器根据私有数据编码或子节点上传的嵌入生成与其相应叶节点的数据分布相匹配的桥样本。这些桥样本用作中介,在由相同嵌入对齐的每对父子计算节点之间进行在线蒸馏。
- 如下图所示,很难从私有样本的嵌入中恢复原始信息,因为嵌入是基于在超大型开放数据集,而自动编码器无法捕获细粒度特征并从中重建训练样本。

- BSBODP过程
- 每个计算节点的解码器定义为dec(·),叶计算节点的编码器定义为enc(·)。
- 当向上进行知识蒸馏时,父亲节点作为学生 v^S,子节点作为教师 v^T 。当进行向下的知识蒸馏时,角色颠倒过来。
- 对于非叶学生节点
- 训练目标如下,即最小化 L_{CE} 交叉熵损失和 KL散度 KL ,交叉熵损失是学生模型的输出与样本标签,KL散度是教师模型输出的logit与学生模型输出的KL散度。
- \epsilon根据方程(3)在叶子节点处生成
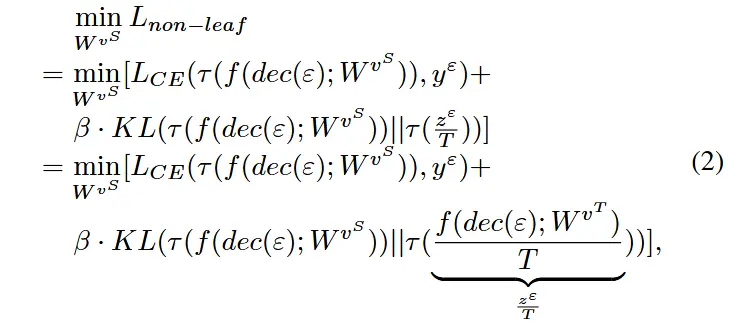
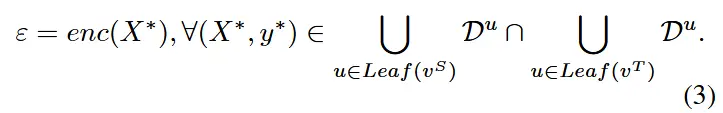
- 此外,对于每一个叶节点,训练目标如下
- 最小化与标签的交叉熵损失+非叶节点损失(即方程2)
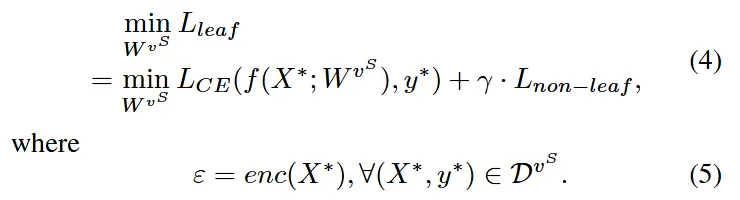
- 上述步骤完成后,v^S 和 v^T 需要交换角色,并遵循上述约束条件向相反方向进行优化,如算法1所示。
- 因此,每对父子计算节点上训练的模型可以互相学习, 通过知识蒸馏学习到的表示可以从叶子节点开始逐层传播到云上的模型。

C 端边缘云网络中的递归聚合
- 考虑到 EEC-NET 中计算节点以树形拓扑结构组织的 FL,作者提出了 FedAgg 框架,该框架应用 BSBODP 来实现每对父子计算节点的协作训练,以凝聚方式从下到上递归地提取知识方式,如算法 2 所示。具体来说,FedAgg 包括两个主要阶段:
- 在初始化阶段,叶节点使用预先训练的编码器生成嵌入,并将它们沿着树层次结构发送到根节点。
- 在训练阶段,每个节点从以它为根的子树中递归地提取知识,并将新提取的知识传递给其父节点,应用 BSBODP 来实现父子对之间的交互。这个过程从叶节点开始,到云服务器结束。

D 聚合联邦学习的部署灵活性保障
- FedAgg 支持计算节点的动态迁移,以保证 EEC-NET 中的部署灵活性,其中负载平衡、连接不可靠和节点故障等各种因素可能需要计算节点切换到同一级别的不同父节点。
- 为了展示 FedAgg 在处理计算节点动态迁移方面的优势,我们根据对交互计算节点模型结构的约束,将可能支持分层协作模型训练的现有 FL 交互协议分为两类:等价交互协议 (equivalence interaction protocols) 和偏序交互协议 (partial order interaction protocols) 。接下来详细介绍这两类协议。
- 等价交互协议
- 定义:对于Ⅲ-A节中的树形拓扑EEC-NET,在任何一对父子计算节点上定义二元关系 R。等价交互协议的充分必要条件定义如下:(6)(7)(8)即等价应该满足自反、可逆、传递。
- 可以很容易地证明以下几点是等效的交互协议:
- 1) 父子计算节点采用相同的模型结构,例如FedAvg
- 2) 与模型无关的交互协议,对父计算节点和子计算节点的模型结构不施加限制,例如BSBODP
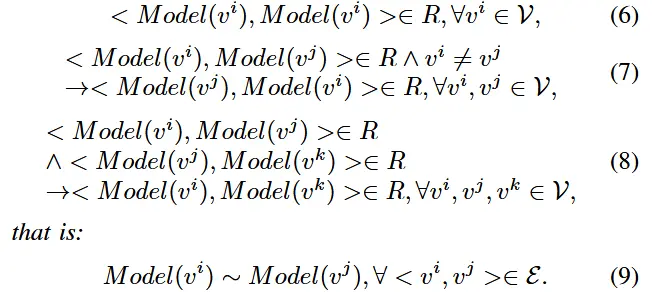
- 偏序交互协议
- 定义:对于Ⅲ-A节中的树形拓扑EEC-NET,在任何一对父子计算节点对上定义了一个二进制关系 R。偏序交互协议的充分必要条件定义如下:
- 我们还可以证明,基于偏序训练的交互协议,它要求子节点上的模型是父节点上的模型的子模型,例如 Model(v^i) \subseteq Model(Parent(v^i)), \forall < v^i,Parent(v^i) >\in \varepsilon,是部分顺序交互协议。
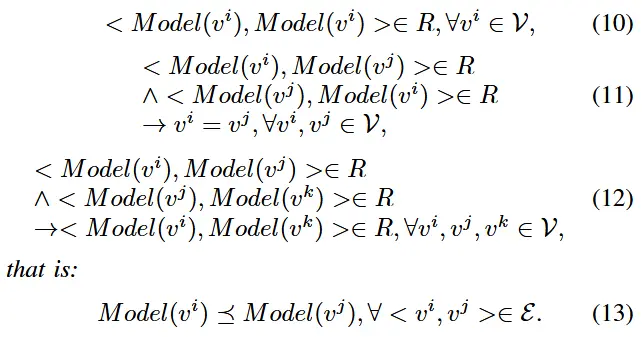
- 定理1
- HFL方法基于等价交互协议,允许任意 v^1 的父节点切换到 Parent(v^2) ,其中 Parent(v^1) and Parent(v^2) 是同一级别的,即 Model(v^1) \sim Model(Parent(v^2)), \forall v^1,v^2 \in \nu_t, t \in {2,3,…,T}。证明见原论文。
- 定理2
-
HFL方法基于偏序交互协议,不一定允许任意 v^i 的父节点转换到 Parent(v^2) ,其中Parent(v^1) 和 Parent(v^2) 在同一级别,即 \neg Model(v^1) \preceq Model(Parent(v^2)), \exists v^1,v^2 \in \nu_t, t \in {2,3,…,T} 。证明见原论文。
-
Ⅴ 实验
A 实验设置
- 数据库:CIFAR-10、CIFAR-100,划分为K个非独立且分布相同的部分,作为K个设备的私有数据。
- 基于FedML库,遵循 [24],我们采用了在 FedML 中预设的超参数α来控制设备之间数据异构的程度。在我们的实验中,我们分别设置了对应于数据异质性高度和低度的 α ∈ {1.0, 3.0} 的值。
- 在所有终端设备上部署了在 ImageNet [27] 上预训练的相同的轻量级 6 层自动编码器,并在其他计算节点上部署了自动编码器的解码器部分。此外,在端节点、边缘节点和云节点分别部署了从小到大模型的 3 层卷积神经网络 (3-layer-CNN)、ResNet10 和 ResNet-18 [30],以适应不同层的计算节点的能力。
- 基线:HierFAVG、DemLearn、FedGKT、FedDKC
B 性能评估
- 测试准确性
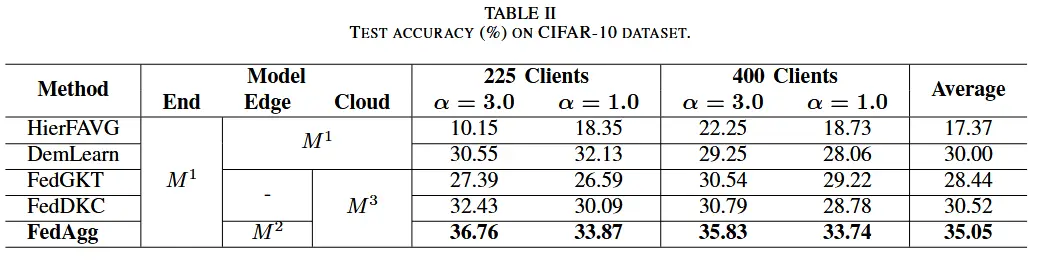
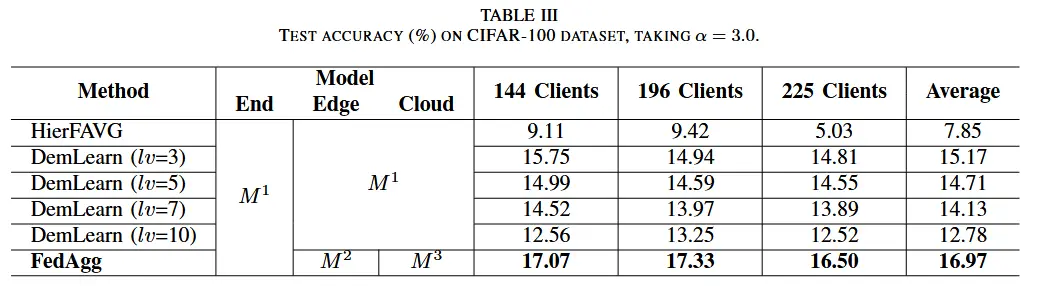
- 收敛速度
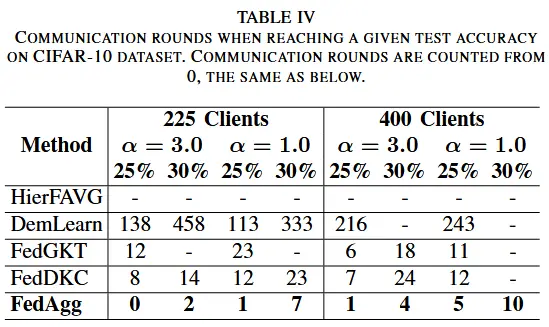
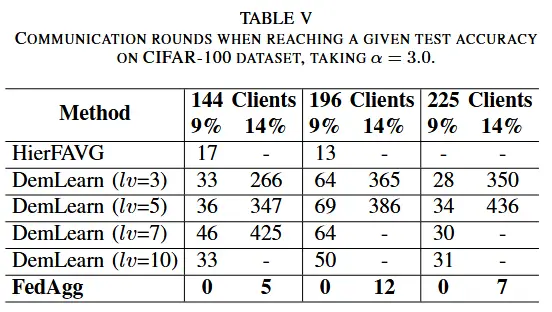
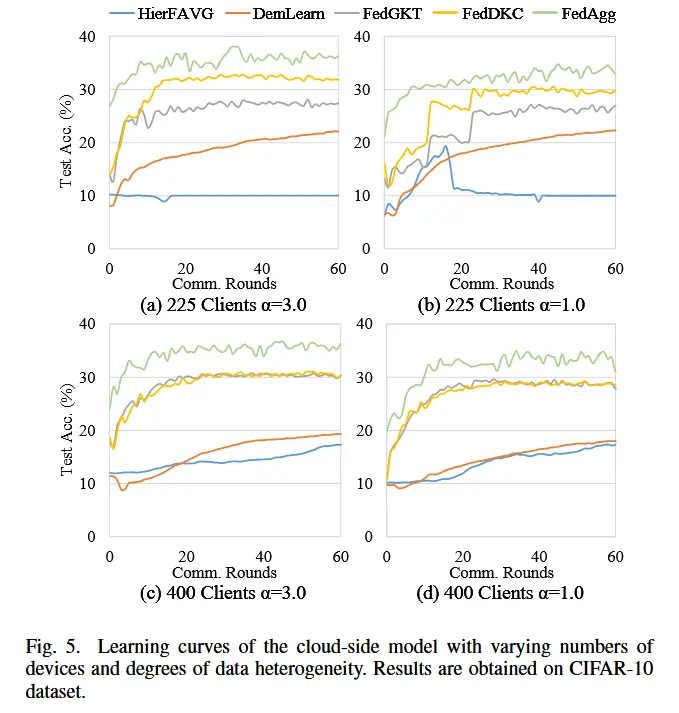
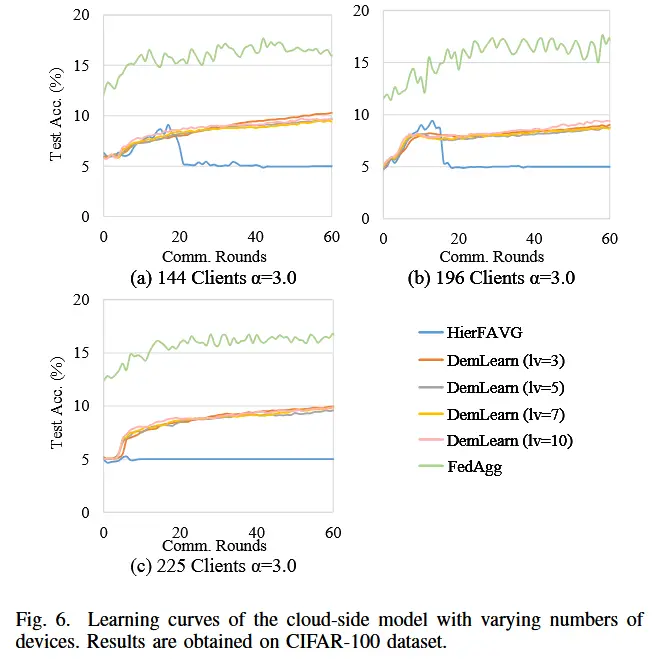
- 此外,图 5 显示了 CIFAR-10 上不同数据异质性和不同客户端数量下的学习曲线,图 6 显示了 CIFAR-100 上不同组织结构下的学习曲线。从图 5 和图 6 中,我们可以得出结论,在相同的通信轮数下,FedAgg 在测试准确性方面始终优于基线算法,并且还保证了在各种实验设置下更快的收敛。
Ⅵ 消融实验
A 在线蒸馏

B 对设备异构性的容忍度

C 更小的云端模型
- 我们将使用较小的云端模型 M^1 和 M^2 的 FedAgg 的性能与使用较大的云模型 M^3 获得的性能进行了比较。

Ⅶ 总结
为了克服由 EECC 授权的 FL 中最弱的终端设备限制的强大边缘和云计算节点上的模型规模限制,我们提出了一种称为聚合联邦学习(FedAgg)的新型联邦学习框架,它允许来自终端设备的训练模型,将边缘服务器连接到云服务器,使其规模更大、泛化能力更强。具体来说,FedAgg通过我们定制的基于桥样本的在线蒸馏协议(BSBODP)以聚合的方式从下到上递归地蒸馏知识,通过对生成的数据进行在线蒸馏,可以在每对父子计算节点之间实现与模型无关的交互。桥梁样品。据我们所知,FedAgg是第一个由EECC赋能的框架,能够逐层训练能力不断增强的更大模型到云端,并且在测试方面能够获得比相关最先进方法更优越的性能准确率和收敛速度。