论文地址-《Towards Efficient Asynchronous Federated Learning in Heterogeneous Edge Environments》
摘要
- 研究解决的问题
- 边缘设备通常具有异构的计算能力和数据分布,阻碍了协同训练的效率。现有的工作开发了陈旧感知的半异步 FL,减少了慢速设备对全局模型的影响,以减轻其负面影响。但这使得慢速设备上的数据无法在全局模型更新中得到充分利用,从而加剧了数据异构性的影响。
- 本文工作
- 在本文中,为了应对系统和数据异构性,我们提出了一种基于集群和两阶段聚合的高效异步联邦学习(EAFL)框架。
- 简单介绍EAFL
- 我们首先提出了一种基于梯度相似性的动态聚类机制,在训练过程中动态地将具有相似系统和数据特征的设备聚类在一起。
- 然后,我们开发了一种新颖的两阶段聚合策略,包括陈旧感知 (staleness-aware) 半异步集群内聚合和数据大小感知同步集群间聚合,以高效、全面地聚合跨异构集群的训练更新。
- 这样,可以同时缓解慢速设备和非独立同分布数据的负面影响,从而实现高效的协作学习。
Ⅰ 介绍
-
FL的挑战
- 系统异构性:边缘设备具有不同的计算能力
- 数据异构性:本地数据不是相同且独立分布(Non-IID)
-
系统异构性的现有工作
- 半异步联邦学习(AFL)被提出,它通过以半异步方式聚合客户端本地更新来处理系统异构性。在每次迭代中,服务器都会聚合来自最快的 K 个客户端的本地更新。
- 考虑到客户端可能基于在不同迭代中更新的过时全局模型进行更新,而高过时(high-stale updates)更新对全局模型产生不利影响,大多数 AFL 算法采用过时感知加权聚合来减少贡献高陈旧更新。
-
数据异构性的现有工作
- 数据异构性会导致局部模型出现漂移,将不可避免地降低全局模型的准确性。
- 大多数现有工作[16]-[20]试图利用整体数据并增强全局信息在FL训练过程中所发挥的作用,从而使全局模型能够全面学习并在各种数据分布取得更好的性能。
-
局限
- 主流的AFL方案SAFL虽然提高了训练效率,但它违背了解决NonIID问题的原则, 导致SAFL在数据异构性下模型效用下降。
- 首先,训练快的客户更频繁地参与全局聚合,慢速客户的数据无法充分利用。
- 其次,慢速的客户更有可能基于更陈旧的全局模型更新,导致聚合背分配到更低的权重,进一步阻止了它们充分参与全局模型更新,加剧了数据异构性的负面影响。
- 一些方法[8]、[20]已经被提出来提高AFL在非独立同分布场景中的性能,但它们不能确保全局模型能够充分学习各种数据分布,全局模型仍然会有偏差。也就是说,现有的工作无法同时很好地解决系统异构性和数据异构性。
- 主流的AFL方案SAFL虽然提高了训练效率,但它违背了解决NonIID问题的原则, 导致SAFL在数据异构性下模型效用下降。
-
面临的挑战,本文工作的难度
- 1)如何充分学习具有异构系统和数据特征的客户端,而不被缓慢的客户端所拖累?让所有客户参与训练可以有效利用整体数据并充分学习全局信息?
- 2)如何始终有效、全面地聚合客户的本地更新以获得更好的性能?
- 工作
- 提出了EAFL,一种基于集群和两阶段聚合的高效异步联邦学习框架。
- 首先,作者提出了一种基于梯度相似性的动态聚类机制,将具有相似系统和数据特性的客户端聚类在一起。它们的同质性可以通过其本地更新方向的一致性来体现,进而体现在梯度的相似性上。因此,我们动态地将具有相似梯度方向的客户端分组到同一集群中。
- 其次,作者设计了一种新颖的两阶段聚合策略,用于聚合跨异构集群的各种更新,包括过时感知的半异步集群内聚合和数据大小感知的同步集群间聚合。
- 为了避免受到高过时 (highstale) 客户端的影响,作者提出了根据过时度 (staleness) 进行加权聚合。集群间聚合是同步聚合来自异构客户端的各种更新,从而充分利用全局信息。它还具有数据大小感知功能,允许聚合更新更好地代表整个集群而不是单个客户端。
Ⅱ 相关工作
- FL 中的系统异质性
- FL 中的数据异质性
- 基于聚类的 FL
Ⅲ 问题定义
A 系统模型
- 我们考虑异构边缘环境中的 FL 系统,由服务器和多个异构边缘设备(客户端)组成。客户端在数据和系统方面都是异构的。
- 具体来说,客户会根据一定的标准被分为几个集群。每个集群会选择其中的一个客户端作为簇头,其他客户端通过簇头与服务器交互,而不是直接与服务器交互。
- 在这种情况下,每个客户端像往常一样在本地训练其模型,并将本地更新上传到簇头,簇头负责
- 1)聚合簇内客户端上传的本地更新,即簇内聚合,并发送向客户端聚合更新
- 2) 从服务器接收全局更新并将其发送到参与此集群内聚合的客户端。服务器执行簇间聚合,以聚合簇头上传的更新以更新全局模型,然后将新的全局模型发送回相应的簇头。
B 问题建模
- 需要解决的问题是
- 在集群 \{X_1,X_2,···,X_N\} 的协助下,如何实现不同本地训练时间 \{e_1,e_2,···,e_M\} 和各种不同异构客户端之间的高效协作来自不同分布的本地训练数据 \{D_1,D_2,····,D_M\},从而减轻慢客户端和数据分布不均匀的影响,实现高效的联邦学习,得到高性能的全局模型w。
Ⅳ 预备
- 本节首先回顾了FL和SAFL的运行过程,然后分析了SAFL的缺点。
A 联邦学习
B 陈旧感知异步联邦学习
- Staleness-aware Asynchronous Federated Learning
- 数据和系统异构性会显着降低 FL 的效率。例如,如果少数客户端遇到延迟,则整个 FL 系统的进度可能会受到影响。
- SAFL
- SAFL可以提高FL的效率。首先,它减轻了客户端速度慢的影响,因为它使客户端能够独立提交更新,而无需等待其他客户端。此外,它通过聚合根据陈旧性加权的本地更新来提高学习性能。
- 在SAFL中,服务器一旦从最快的K个客户端接收到本地更新,就会执行陈旧感知全局聚合以获得新的全局模型,并且更新后的全局模型将仅广播到这K个客户端。与此同时,其他客户继续各自的本地培训,为未来的全球聚合做好准备。请注意,客户端的陈旧程度衡量全局模型在本地训练中的陈旧程度,可以定义为自客户端上次参与全局聚合以来经历的迭代次数。
- 图1给出了 SAFL 的示例,其中 K = 2。以迭代 2 为例,客户端 2 和客户端 3 是本次迭代中最快的两个客户端。由于它们的本地更新分别基于w1和w0,因此它们的陈旧度分别为1和2。因此,服务器聚合客户端 2 和客户端 3 的本地更新,其权重与其陈旧程度成反比,以获得更新后的全局模型 w2。
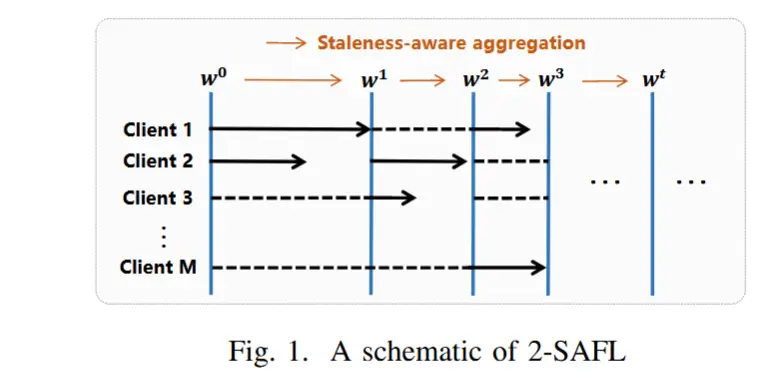
- 设 \nu^t 表示迭代t时最快的K个客户端,每个客户端 i \in \nu^t 的陈旧度用 \tau^t_i 表示,则SAFL在迭代 t 时通过以下方式进行更新:
\omega^t = (1- \alpha)\omega^{t-1} - \alpha \sum_{i \in \nu^t} \frac{|D_i|* S(\tau^t_i) * \omega^t_i}{|D^t|}
C SAFL缺点
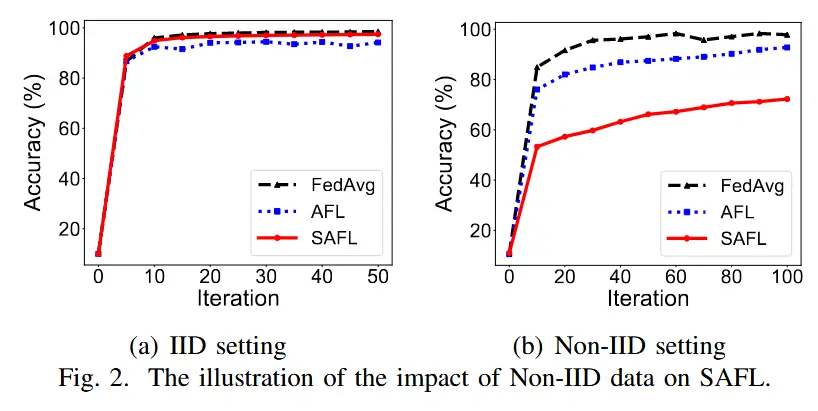
- SAFL在IID设置中,效率和准确性方面表现良好,然而,在NonIID设置中,它的准确性很可能会下降,这是因为它倾向于选择快速客户端参与全局聚合。
- 在这种情况下,如果稀有且独特的数据仅由慢速客户端持有,则此类数据无法在全局模型训练中充分发挥作用。
- 更糟糕的是,过时感知聚合加剧了数据异构性的负面影响,因为它根据客户端的过时程度对更新进行加权。
- 作者在 MNIST [32] 上进行分类任务实验来证明上述推论。
- 分别考虑一个IID和Non-IID设置,其中每个客户端只有属于 1 个标签的数据。
- 在这两种设置中,我们分别将 SAFL 与典型的 FL 算法 FedAvg 和没有过时感知聚合的典型同步联邦学习算法 - AFL 进行比较。结果如图2所示。
- 可以观察到,AFL 和 SAFL 的准确度都比 FedAvg 低得多,并且 SAFL 的准确度比 KAFL 低。这表明AFL不能很好地解决数据异构性问题,并且SAFL中基于陈旧性的加权聚合方法在Non-IID设置中起到了适得其反的作用,这与我们的分析是一致的。
Ⅴ 机制设计
- 在本节中,我们首先概述 EAFL,然后详细介绍所提出的机制。
A EAFL概述
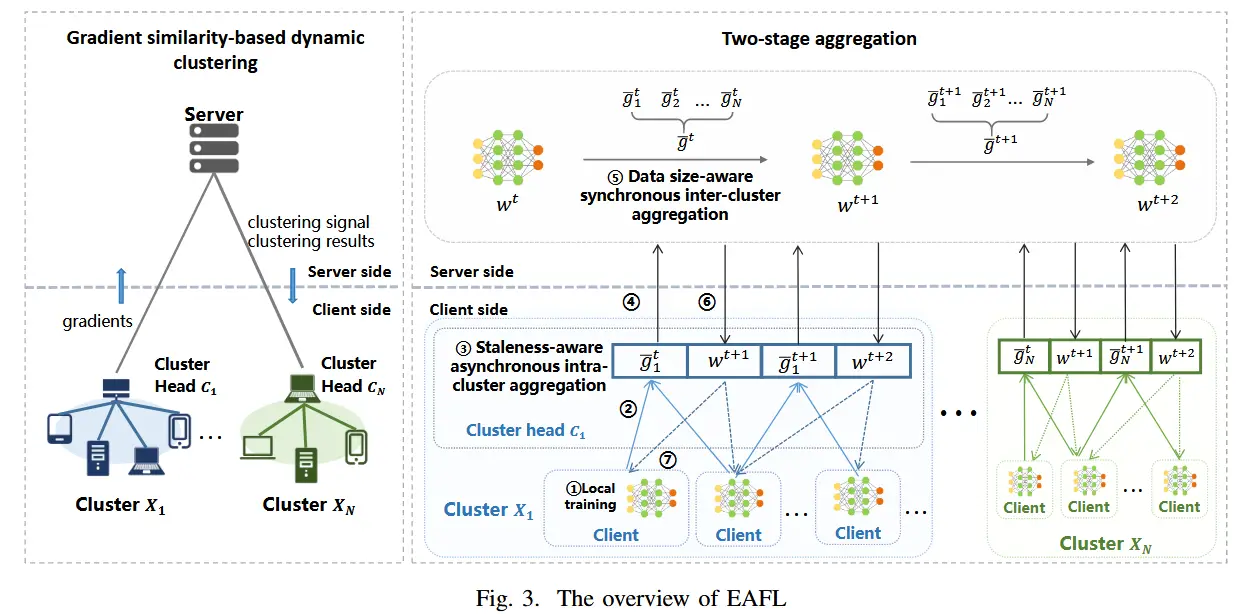
- 图3显示了EAFL的框架,它由两个主要机制组成:基于梯度相似性的动态聚类机制(GDC)和新颖的两阶段聚合策略。
- 前者是在服务器上执行的,服务器动态地将本地更新方向(即梯度)相同的客户端分配到同一个集群中,使每个集群中的客户端具有相似的系统和数据特征。
- 后者包含在每个集群处处理的陈旧感知半异步集群内聚合(SAA)和在服务器处处理的数据大小感知同步集群间聚合(DSA)。
- 效果
- 通过SAA,我们可以克服慢速客户端和高陈旧度梯度的阻力,从而有效地聚合来自每个集群内同类客户端的本地更新。
- 通过DSA,我们可以全面聚合来自异构集群的更新,以确保具有各种数据和系统特征的客户端能够充分参与全局聚合并为全局模型做出贡献。
- 通过我们的设计,可以同时减轻慢速设备和不均匀数据的负面影响,从而实现高效的协作学习并提高全局模型性能。
- EFAL 的训练过程如算法1所示
- 服务器有两个主要功能:
- 1)每R轮,服务器需要向客户端发送聚类信号,收集所有客户端的梯度,并执行GDC(第4-12行)。
-
- 执行DSA,并分发新模型(第14-15行)。
- 服务器有两个主要功能:
- 如果一个客户端被选为簇头
- 它将承担集群内客户端与服务器之间的交互。
- 它从集群内最快的 φ 比率客户端收集更新,同时执行本地更新,执行 SAA,然后将聚合的更新发送到服务器。
- 此外,它将新模型发送给参与集群内聚合的客户端(第27-30行)。
- 客户端需要做的是
-
- 当收到聚类信号时向服务器发送梯度(第 19-25 行)
-
- 执行本地训练,然后将更新上传到簇头,在收到新的全局模型后更新本地模型(第 32-33 行)
-

B 基于梯度相似度的动态聚类
具有相似系统和数据特征的客户端往往具有相似的模型更新方向,这在大多数机器学习框架中通过训练中的梯度下降方向来指示。因此,我们根据梯度方向的相似性对客户端进行聚类,使得每个聚类中的客户端在数据和系统上可以近似同质。
- 作者使用余弦距离来测量客户端之间的梯度方向相似度,余弦距离如下
cos(\vec{g},\vec{g'})= \frac{\vec{g} \cdot \vec{g'}}{|\vec{g}| \cdot |\vec{g'}|}
- 通过余弦距离测量客户端的梯度相似度后,我们使用K-Means [34] 算法将具有高梯度相似度的客户端聚类到同一簇中。
- 然而,每个客户端的陈旧度在训练过程中是动态变化的,这加剧了基于梯度相似度的聚类的不确定性。为了解决这种不确定性,我们在每R次全局迭代中动态执行基于梯度相似性的聚类,以确保每个集群内的客户端具有一致的陈旧性和数据分布, 从而尽可能具有相似的系统和数据特征。
C 两阶段聚合
- 在本文中,我们提出了一种新颖的两阶段聚合策略,结合SAA和DSA来充分学习全局信息,并减少高陈旧客户端更新对全局模型的损害,从而提高全局学习的效率。
- 簇内聚合
- 集群内聚合采用半异步聚合,提高训练效率。这样,在每个集群内,快速客户端不需要等待慢速客户端,从而减轻了落后者效应。同时,集群内聚合具有过时感知能力,这减少了高过时梯度的参与,以减轻其负面影响。
- 假设客户端 i 在当前全局迭代 t 参与簇内聚合,最后一次参与簇内聚合是在全局迭代 t',即客户端当前基于全局模型 w^{t'} 进行更新迭代 t' 的 ,此时它的陈旧度用 \tau^t_i = t - t' 表示。
- 另外,该客户端的本地更-新过程可以表示为如下公式,其中 D_i 为本地训练数据,\eta 为学习率。f 是本地训练损失函数,∇f (w^{t′} , Di_) 是局部梯度。
w^t_i = w^{t’} − \eta \cdot ∇f (w^{t′} , D_i)
- 对于每个簇 X_n (n \in \{1, 2, \cdots, N\}) ,簇头 C_n 通过陈旧性聚合由簇内最快 φ 比率客户端上传的本地更新(即梯度)意识聚合。在簇内聚合时,对于每个客户端梯度权重,使用其陈旧度的反比例函数表示,即 p_i^t = 1 / \tau_i^t 。
- 然后,在迭代 t 时在每个集群 X_n 处处理的陈旧感知半异步集群内聚合可以表示为:
\vec{g}_n^t = \sum_{i \in V_n^t} \frac{|D_i|}{|D_n^t|} \cdot p_i^t \cdot \nabla f(w_i^t, D_i)
- 簇间聚合
- 我们采用DSA进行簇间聚合,允许每个簇以相等的概率参与训练,使每个数据分布和计算能力的客户端都参与训练,以缓解全局模型偏向快速训练客户端的问题。
- 在大多数联邦学习范例中,服务器根据参与聚合的客户端的数据量执行加权聚合。但考虑到特定集群上传的梯度不仅代表参与集群内聚合的客户端的情况,还代表整个集群的情况,因此集群间聚合是在整个集群的加权数据量的基础上进行的。
- 让 |D_n| 表示每个簇中数据样本的总数 X_n,在每次迭代 t 中,服务器执行数据大小感知的同步簇间聚合,以聚合所有簇头上传的聚合梯度,以更新全局模型 w^t 。
w^t = w^{t-1} - \eta \cdot \frac{\sum_{n=1}^N |D_n| \cdot \vec{g}_n^t}{|D|}
- 之后,服务器将新的全局模型发送回所有簇头,每个簇头将新的全局模型广播给参与本次迭代的簇内聚合的客户端,以供其进一步本地更新。
D 收敛性分析
- 作者提出了三个Assumption和一个Theorem,从数学分析了收敛性,T epoch 之后 EAFL 的收敛界限为:
E[F(w^T) - F(w^*)] \leq [2N \cdot M \cdot (1-\mu \cdot \eta)^Q] \cdot [F(w^{T-1}) - F(w^*)] + \frac{N \cdot M \cdot Q \cdot \eta \cdot P}{2}
Ⅵ 评估
A 设置
- 数据集:MNIST、CIFAR-10。按照之前的工作来模拟两种分布,T1-IID,T2-Non-IID。
- 训练设置:我们训练卷积神经网络。FL系统有1台服务器和100个客户端。
- 对于 MNIST,我们部署了一个包含两个卷积层的 CNN 模型,两个卷积层都带有 ReLU 激活层。我们使用随机梯度下降作为优化器。聚类数量 N = 5,重新聚类轮次间隔 R = 100。
- 对于 CIFAR-10,我们使用经典的 CNN 模型 LeNet [39]。我们使用 SGD 作为优化器。
- 其余参数见论文。
- 指标:在实验中,我们通过测试集上的预测准确性来衡量全局模型效用。
- 基线:我们将 EAFL 与 3 种专注于数据或系统异构性的最先进的 AFL 算法进行了比较。
- TWAFL [9]:它通过以下方式计算参与全局聚合迭代 j 的每个客户端 i 的过时感知权重
S(\tau^t_i) = (e/2)^{-\tau^t_i}
- GSGM [20]:一种旨在处理数据异构性的AFL算法。它会阻止快速客户端,强制它们等待慢速客户端,以便所有具有异构数据分布的客户端都有机会充分参与训练。
- WKAFL [8]:一种旨在处理数据异构性的AFL算法。它首先在最快的 K 个局部更新之间执行陈旧感知聚合,以估计无偏全局更新,然后根据这些局部更新与无偏全局更新的距离重新分配权重。
- TWAFL [9]:它通过以下方式计算参与全局聚合迭代 j 的每个客户端 i 的过时感知权重
B 参数评估
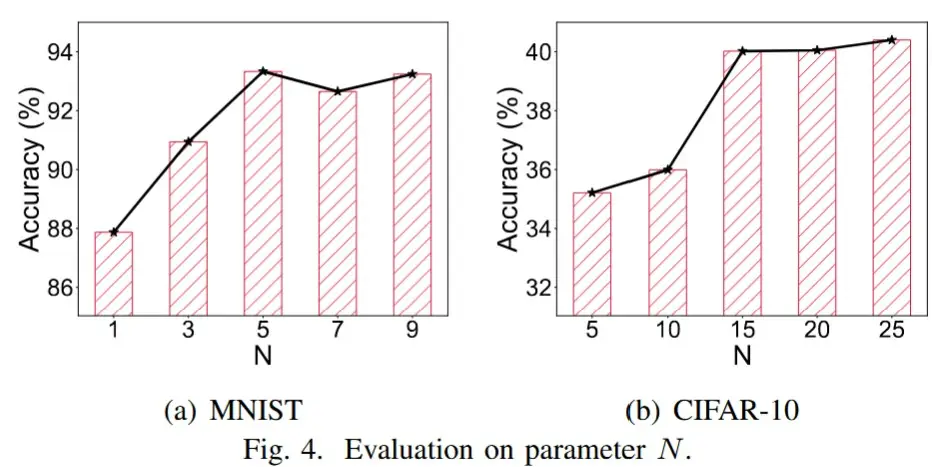
- 簇数 N 的影响
- 观察:随着 N 的增加,全局模型精度首先增加,然后几乎稳定。
- 原因:当N较小时,每个簇中的客户端数量会很大,并且每个簇内的异质性程度会很高。在这种情况下,很难确保全局模型能够全面学习来自客户的各种数据和系统特征的信息。当N增加到一定值时,每个集群内的客户端基本上是同构的,从而获得相对稳定的全局模型性能。
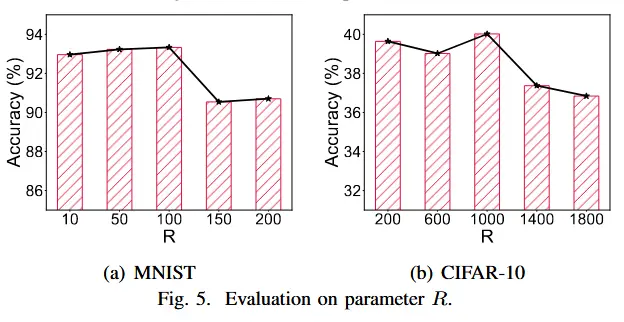
- 重新聚类轮次间隔 R 的影响
- 观察:随着 R 的减小,全局模型精度首先增加,然后基本保持不变。
- 原因:随着集群内半异步聚合的进行,客户端的陈旧性会发生变化。如果R太大,重新聚类不及时,因此同一集群内的客户端不具有相似的系统特征。当R减小到一定值时,重新聚类的频率可以赶上簇内陈旧性的变化,因此全局模型性能稳定。
- 后续实验N和R设置
- 考虑到集群越多,需要更多的通信资源来支持簇头和服务器之间的交互,在后续实验中,我们将MNIST设置为N = 5,将CIFAR-10设置为N = 15。
- 考虑到重新聚类过于频繁会影响训练效率,后续实验中MNIST选择R = 100,CIFAR-10选择R = 1000。
C 性能评估
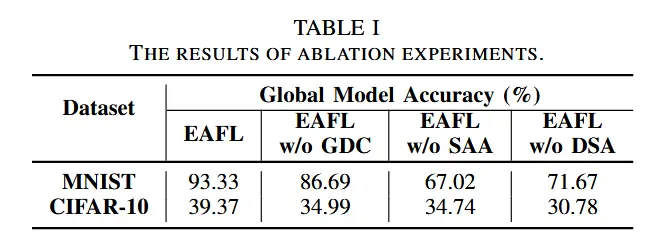
- 消融实验
- 为了验证由 GDC、SAA 和 DSA 组成的机制的有效性,我们分别进行了有和没有 GDC、SAA 和 DSA 的 EAFL 实验。 其中,没有GDC的EAFL仅在训练过程开始时执行一次聚类。没有 SAA 的 EAFL 通过平均而不是陈旧感知加权聚合来执行集群内聚合。没有 DSA 的 EAFL 以同步方式而不是异步方式聚合簇头上传的更新。结果如表1所示。
- 结果很明显,三个模块对与EAFL都很重要。
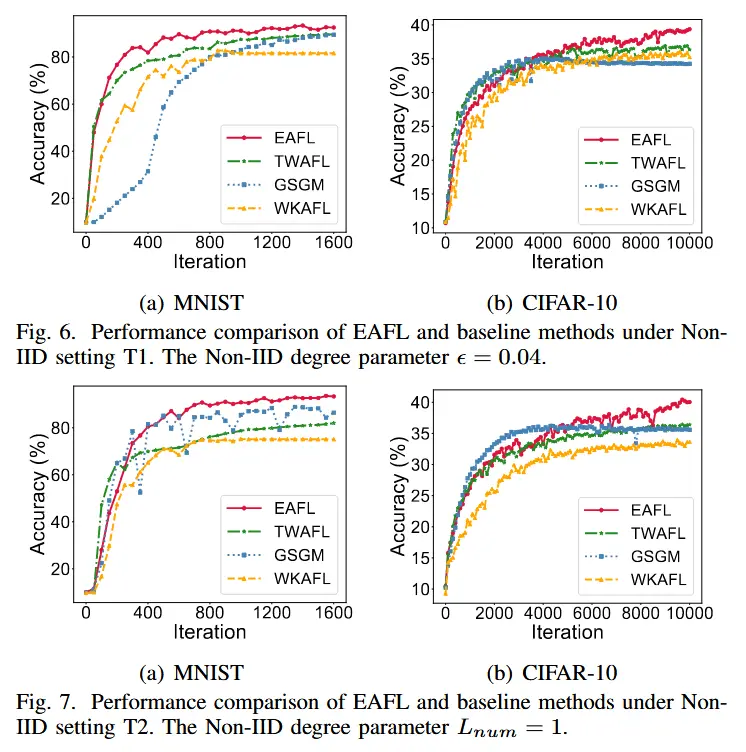
- Non-IID 设置下的性能比较
- 我们将 EAFL 与基线方法(即 TWAFL、GSGM 和 WKAFL)在 MNIST 和 CIFAR-10 数据集的两种非 IID 设置下的性能进行比较,结果如图 6 和图 7 所示。
- 基线的缺点:TWAFL仅提出加权聚合来解决系统异构性带来的陈旧问题而没有考虑数据异构性,GSGM只能增加每个数据分布参与训练的机会但没有充分解决陈旧问题,WKAFL不能保证训练速度慢但数据分布独特的客户充分参与训练。
- Non-IID程度变化时的性能比较
- 我们将 EAFL 与非 IID 设置(T2)下的基线方法(L_{num} 分别为 1、5、10)进行比较,结果如表2所示。
- 观察:随着 L_{num} 的增加,所有三种基线方法的准确性都会增加,因为每个客户端上可用的标记数据越来越多,局部模型漂移变得很小,并且客户端更新方向更加一致,即局部更新可以更好地表示全局信息。EAFL 在不同 L_{num} 设置下在 MNIST 和 CIFAR-10 上都保持了较高且稳定的精度,而基线方法在 L_{num} 较小时明显退化。

- 参与客户比例变化时的性能比较
- 当每次全局迭代中参与客户的百分比发生变化时,我们将 EAFL 与基线方法的性能进行比较。我们设置了三个不同的 φ,对于 MNIST 是 0.05、0.10、0.20,对于 CIFAR-10 是 0.10、0.20、0.30。结果如表3所示。
- 随着 φ 的增加,所有三种基线方法的准确性都会增加,原因有以下两点
-
- 之前的工作 [8] 表明,陈旧性的最小平均值大约等于 1/2\varphi ,这意味着客户端的陈旧性因此减少,从而使全局模型受到高陈旧更新的负面影响较小
-
- 有更多的客户端参与在每次训练迭代中,服务器可以全面地学习更多的全局信息。
-
- EAFL 在具有三种不同 \varphi 设置的 MNIST 和 CIFAR-10 上都保持了较高且稳定的精度。
- 原因:在集群内进行过时感知加权聚合,以避免在利用各种更新的同时受到高过时更新的影响。
Ⅶ 总结
在本文中,我们提出了一种基于集群和两阶段聚合的高效异步联邦学习(EAFL)框架,以应对系统和数据异构性并提高异构边缘环境中的全局模型实用性。我们提出了一种基于梯度相似性的动态聚类机制,在训练过程中动态地将具有相似系统和数据特征的边缘设备聚类在一起,从而自适应地利用各种更新。同时,我们设计了一种新颖的两阶段聚合,包括陈旧感知半异步集群内聚合和数据大小感知同步集群间聚合,以充分利用全局信息,而不受慢速设备的阻碍。实验结果表明,EAFL 优于现有最先进的方法,可以成为异构边缘环境中高效协作训练的有价值的解决方案。