论文地址《EdgeShard: Efficient LLM Inference via Collaborative Edge Computing》
Ⅰ 介绍
A 存在的问题
- 一些工作利用模型量化 [7][12] 来减小模型大小以适应资源受限的边缘设备。但是,它们通常会导致准确性损失。
- 其他工作倾向于使用云边缘协作 [13]、[14],它将 LLM 划分为两个子模型,并将部分计算工作负载卸载到具有高端 GPU 的强大云服务器上。但是,边缘设备和云服务器之间的延迟通常很高且不稳定。
- CEC 不同于现有的边缘计算研究。现有的边缘计算研究侧重于云、边缘和终端设备之间的垂直协作,而忽视了横向的边缘到边缘协作,存在资源利用率不优化、服务覆盖范围受限和性能参差不齐等问题。
- Gpipe和PipeDream等工作对 LLM 进行分区并分配给云数据中心中的多个 GPU,与本文的工作具有很大不同。一是,云服务器同构,边缘设备异构。二是,云GPU通常通过高带宽网络连接,边缘设备则通过异构和低带宽网络连接(eg, NVlinks 最高可达600GB/s,而边缘设备带宽从几十Kbps到1000Mbps不等)
B 简单介绍方法
给定一个具有异构计算设备的网络,EdgeShard 将 LLM 划分为多个分片,并根据异构计算和网络资源以及设备的内存预算将它们分配给明智的设备。为了优化性能,作者制定了联合设备选择和模型分区问题,并设计了一种高效的动态规划算法,以分别最小化推理延迟和最大化推理吞吐量。
C 贡献
- 作者提出了一个通用的 LLM 推理框架,用于在边缘计算环境中部署 LLM,从而实现异构边缘设备和云服务器之间的协作推理。
- 作者定量研究了如何选择计算设备以及如何对 LLM 进行分区以优化性能。作者从数学上制定了一个联合设备选择和模型分区问题,并提出了一种动态规划算法来分别优化延迟和吞吐量。
- 作者还在物理测试台上使用最先进的 Llama2 串行模型评估了 EdgeShard 的性能。实验结果表明 EdgeShard 的性能明显优于各种基线方法。
Ⅱ 前提和动机
-
生成式LLM推理
- LLM 推理的过程是迭代的,通常包括两个阶段:提示处理阶段和自回归生成。提示处理阶段也称为预填充prefill。
- 在提示处理阶段,模型以用户初始词元 (x_1,..., x_n) 作为输入,通过计算概率 P(x_{n+1} | x_1, ..., x_n) 生成第一个新词元 x_{n+1} 。
- 在自回归生成阶段,模型根据初始输入和到目前为止生成的标记,一次生成一个标记。此阶段按顺序为多次迭代生成令牌,直到满足停止标准,即在生成序列结束 (end-of-sequence, EOS) 令牌或达到用户指定或受 LLM 约束的最大令牌数时。
- LLM 推理的过程是迭代的,通常包括两个阶段:提示处理阶段和自回归生成。提示处理阶段也称为预填充prefill。
-
prefill阶段生成一个token的时间比自回归阶段高很多,因为prefill阶段需要计算所有 input token 的 KV cahche 作为初始化。
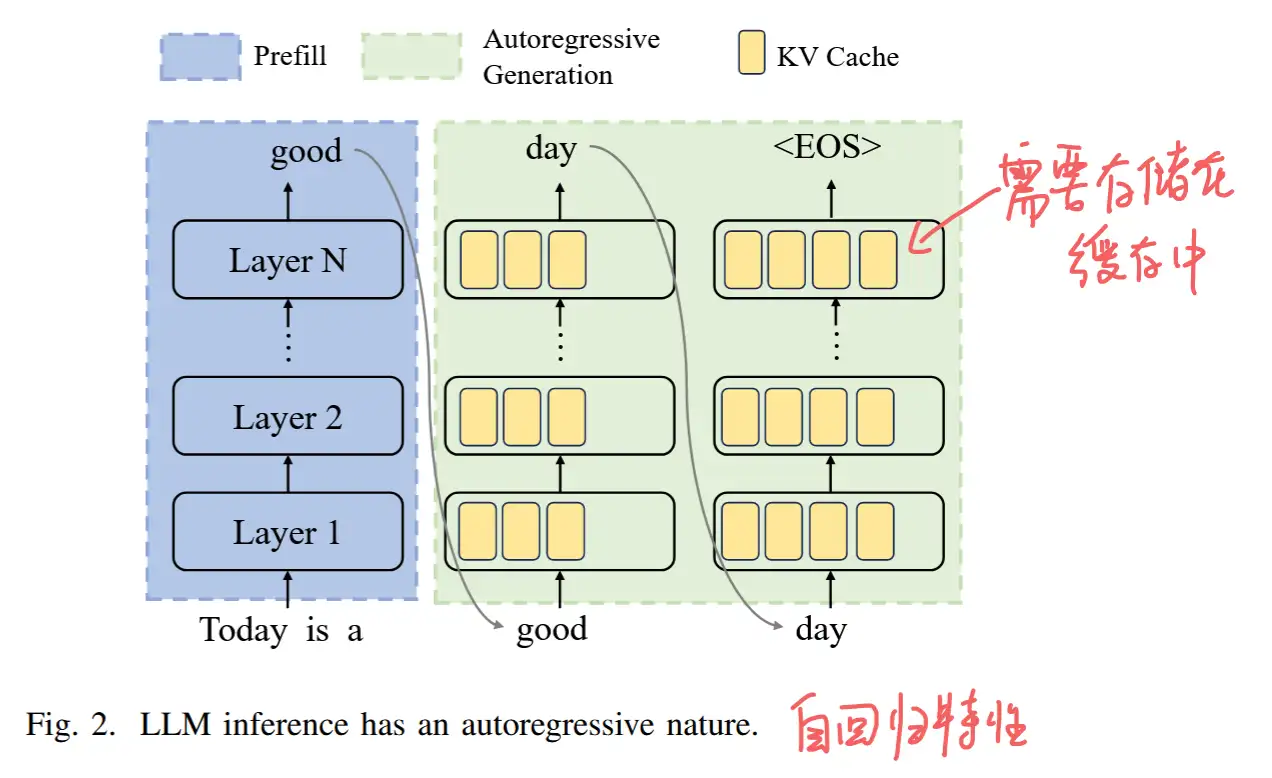
- LLM 大量内存消耗
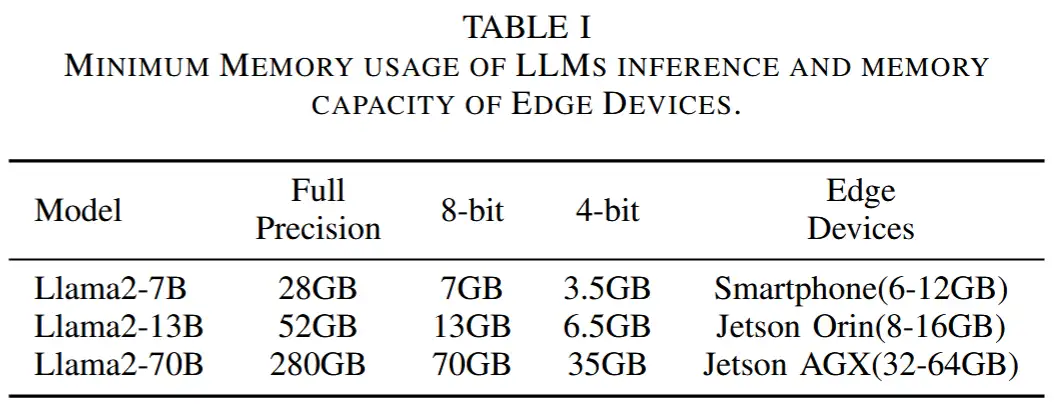
- 以最流行的 LLM 模型之一 Llama2 为例。Llama2-7B 的全精度推理至少需要 28GB 内存,但智能手机通常只有 6-12 GB 内存,而 Jetson Orin NX 有 8-16 GB 内存。
- 在这项工作中,作者利用协作边缘计算,这是一种计算范式,其中地理分布式边缘设备和云服务器协作执行计算任务。基于这个想法,作者提出了 EdgeShard,这是一个通用的 LLM 推理框架,允许在分布式计算设备上进行自适应设备选择和 LLM 分区,以解决高内存需求并利用异构资源来优化 LLM 推理。
Ⅲ 面向 LLMS 的协作边缘计算
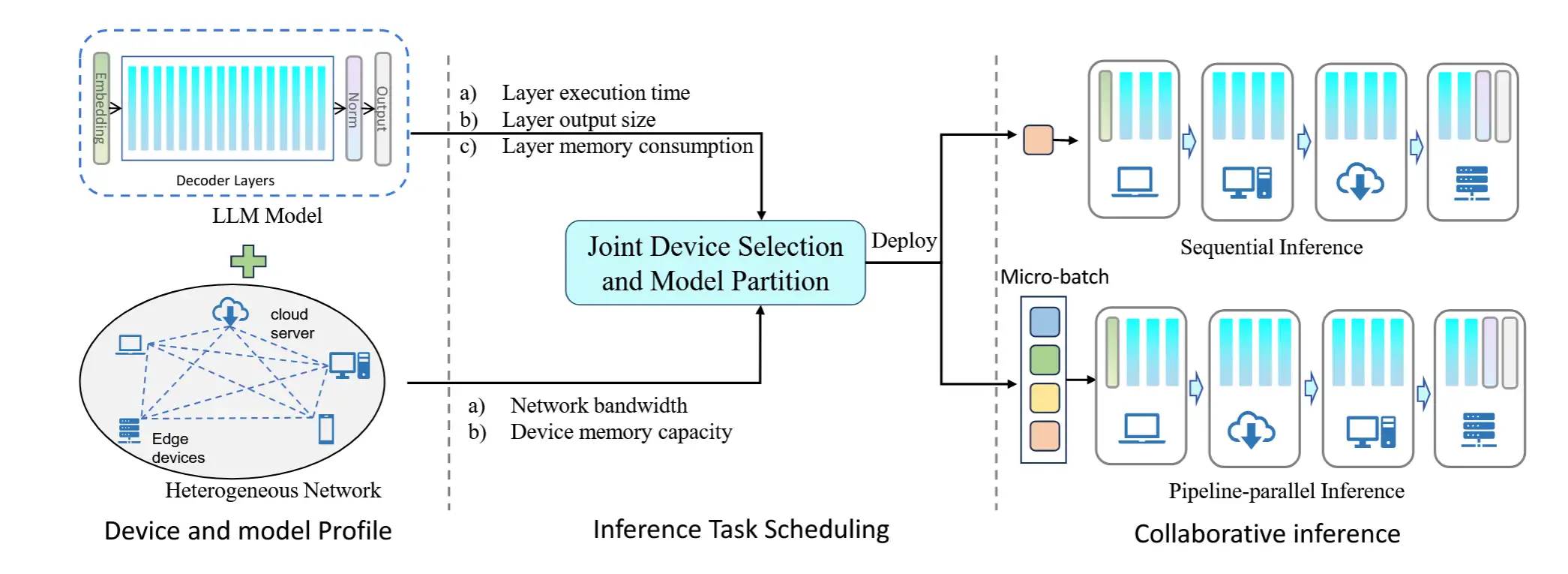
- 该框架分为三个阶段,包括分析、任务调度优化和在线协作推理。如下图
-
分析
- 分析是一个离线步骤,用于分析优化步骤所需的运行时跟踪,并且只需执行一次,这些跟踪包括:
- 每层在不同设备上的执行时间
- LLM 模型每一层的激活大小和内存消耗
- 每个设备的可用内存和设备之间的带宽
- 对于每一层的执行时间,作者分别分析了在 prefill 阶段和 autoregressive 阶段生成 token 的时间,并取平均值。
- 对于那些可能没有有效的内存来保存用于执行分析的完整模型的设备,作者利用动态模型加载技术,其中模型层连续加载以适应受限内存。
- 然后,分析信息将用于支持智能任务调度策略。
- 分析是一个离线步骤,用于分析优化步骤所需的运行时跟踪,并且只需执行一次,这些跟踪包括:
-
调度优化
- 在 任务调度优化阶段,调度器通过确定要参与的设备、如何对 LLM 模型进行分层以及模型分片应分配给哪个设备来生成部署策略。
- 该策略彻底考虑了异构资源、设备的内存预算和隐私约束,然后应用于选定的设备以实现高效的 LLM 推理。更多细节在第四节中描述。
-
协作推理
- 在得到 LLM 模型分区分配策略后,选中的设备将进行协同推理。
- 为每个参与设备上的 KV 缓存预先分配内存空间。
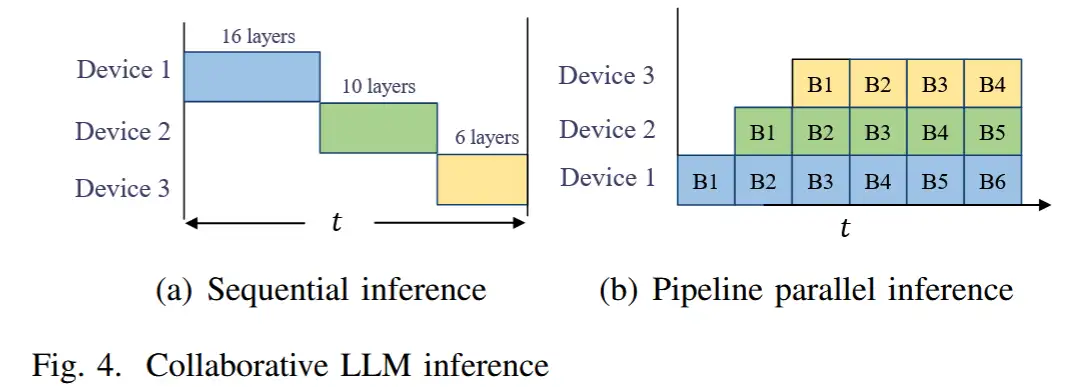
- 考虑了协作推理的两种情况,即顺序推理和管道并行推理(sequential inference and pipeline parallel inference)。
- 在顺序推理中,设备轮流使用分配的模型分片执行计算。顺序推理适用于服务单个用户,例如智能家居场景中。在这种场景下,用户输入prompt得到响应,再输出另一个prompt。目标是最大限度地减少顺序推理的延迟。
- 但是,从系统的角度来看,顺序推理并不节省资源。当设备1进行计算时,设备2和3处于空闲状态。
- 因此,采用管道并行推理提高资源利用率。对于之前工作 Gpipe [17] 和 PipeDream [18] 中针对云服务器采用的管道并行推理,输入数据将首先被拆分为微批处理,然后馈送到系统中。如图 4(b) 所示,设备 1 首先处理数据 B1,然后将中间数据传输给设备 2。处理完数据 B1 后,设备 1 立即进入处理数据 B2。在这种 pipeline 方式下,每个设备都忙于高系统资源利用率。
Ⅳ 优化LLM推理
- 考虑一个具有异构设备和带宽连接的通用协作边缘网络。更具体地说,给定一组与异构带宽连接的异构设备,EdgeShard 旨在选择一个设备子集并将 LLM 划分为分片,这些分片将分配给选定的设备,以最大限度地减少推理延迟或最大化吞吐量。
A 优化LLM推理延迟
-
问题建模
- 作者将总推理时间定义为如下式子,其中X_{i,j} 为二分变量,1表示层 i 在节点 j 上,反之为0;t^{i,j}_{comp} 表示层 i 在节点 j 上的计算时间;t^{i-1,k,j}_{comm} 表示层 i-1 将数据从层 k 传输到层 j 的通信时间。
T_{tol} = \sum_{i=0}^{N-1} \sum_{j=0}^{M-1} X_{i,j}* t^{i,j}_{\text{comp}} + \sum_{i=1}^{N-1} \sum_{j=0}^{M-1} \sum_{k=0}^{M-1} X_{i-1,k}* X_{i,j}* t^{i-1,k,j}_{comm}
- 因此,问题建模为如下图。式3表示最小化推理时间;式4表示受隐私限制,第一层必须在节点0,这样可以使得原始数据在本地处理;式5表示内存限制。
min T_{tol} \tag{3}X_{0,0} = 1 \tag{4}\sum_{i=0}^{N-1} X_{i,j} \cdot \text{Req}_i \leq \text{Mem}_j \tag{5} - 作者将总推理时间定义为如下式子,其中X_{i,j} 为二分变量,1表示层 i 在节点 j 上,反之为0;t^{i,j}_{comp} 表示层 i 在节点 j 上的计算时间;t^{i-1,k,j}_{comm} 表示层 i-1 将数据从层 k 传输到层 j 的通信时间。
-
解决办法
- 为了最大限度地减少推理延迟,作者设计了一种动态编程算法。直觉是第一个 i 层的最小执行时间由第一个 i − 1 层决定, 这意味着可以从子问题的最优结果构建最优解。
- 它具有最 optimal sub-problem 属性,这促使使用动态规划,其中 DP(i,j) 表示表示在将第 i 层分配给节点 j 后,前 i 层的最小总执行时间。
-
此外,由于 LLM 的自回归性质,生成的 token 需要发送回源节点以进行下一次迭代生成。
- 因此,对于最后一层 N − 1,通信时间不仅包括来自 N − 2 层的数据传输时间,还包括到源节点 t^{N−1,j,0}_{comm} 的传输时间。

B 优化LLM推理吞吐量
-
问题建模
- 为了优化吞吐量,采用流水线并行性以避免设备空闲。在流水线并行推理中,计算时间和通信时间可以重叠,以最大限度地提高吞吐量。
- 因此,对于推理任务,设备 j 的最大延迟可以计算为:
T^j_{latency} = max \begin{cases} t_{comp}^{i \rightarrow m,j} \\ t_{comm}^{i-1,k,j} \\ \end{cases} \tag{9}
- 理想情况下,对于所选设备,实现最大吞吐量相当于将最慢设备的延迟降至最低。因此,若S表示所选设备的集合,则最大化推理吞吐量可以用如下公式表示:
min\{T_{lantency}^j | j \in S\} \tag{10}
-
解决办法
- 与最小化推理延迟类似,最大化吞吐量的问题也具有 optimal sub-problem 属性。从解决分配第一个 i−1 层的问题中可以推导出第一个 i 层的吞吐量最大化。因此,还使用动态规划来解决这个问题。
- 使用 g(i,S,k) 表示使用设备集合S处理前 i 层的最小时间,且k是S中的最后一个节点。
- 状态转移方程如下:
g(m,S',j)_{S' = S \cup \{j\}} = \min_{0 \leq i < m \leq N-1 \atop j \in M / S} \max \begin{cases} g(i,S,K) \\ t_{comm}^{i-1 , k, j} \\ t_{comp}^{i \rightarrow m,j} \end{cases} \tag{11}
-
此外还有内存限制和隐私限制:
Req_{i \rightarrow m} \leq Mem_j \tag{12}g(1,1,0) = t^{0,0} _{comp} \tag{13} -
伪代码

- 管道执行优化
- 注意,上述问题的表述和解决方案都是基于理想情况,即任何时候都没有空闲设备。设备处理一批数据,并继续处理另一批数据,无需等待。但是,在实际情况下进行 LLM 推理是不切实际的。
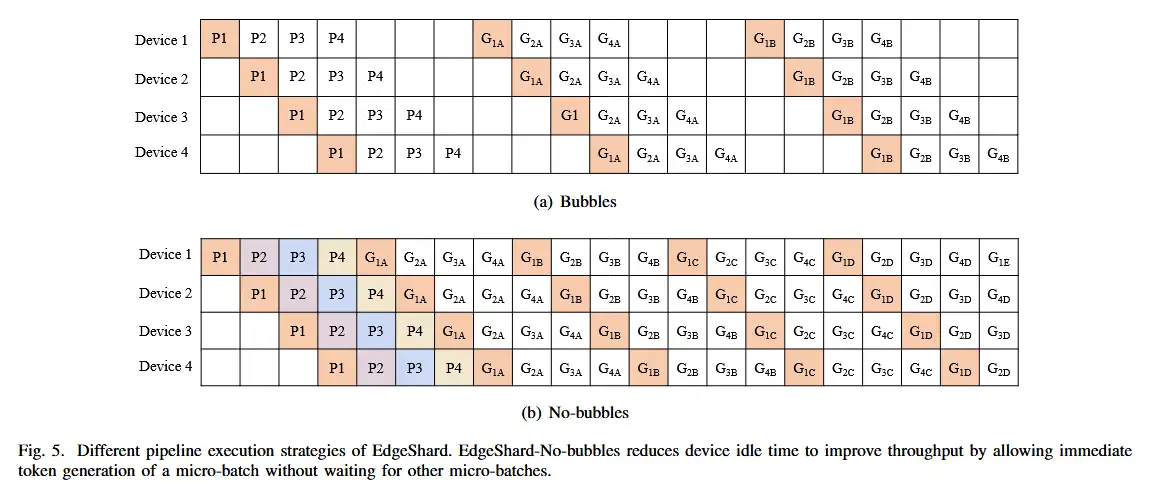
- 基于解码器的 LLM 应用程序具有自回归性质,其中将生成多个 Token,并且当前 Token 的计算依赖于所有先前的 Token。当前 Token 的计算在获取之前生成的 Token 之前无法开始。这会导致管道执行中出现气泡。
- 为了近似理想情况并提高资源利用率以提高吞吐量,倾向于减少管道执行中的气泡。作者提出了 EdgeShard-Nobubbles,它允许立即生成token,而无需等待迭代中所有微批次的结束。
Ⅴ 实验评估
A 实验设置
-
测试平台
- 使用各种边缘设备和云服务器作为协作边缘计算中的异构计算设备。包括12台Jetson AGX Orin、2台Jetson Orin NX和一台作为云服务器的RTX 3090。
- 这些设备通过路由和交换机连接。任意两台设备之间的带宽为 1000Mbps。
- 使用 Linux TC 工具 [20] 来改变设备之间的网络带宽和通信延迟。

-
基准
- 使用一系列 Llama2 模型 [2] 测试了 EdgeShard 的性能,包括 Llama2-7B、Llama213B 和 Llama2-70B。
-
任务
- 对于模型推理,采用文本生成任务来测试性能。作者使用来自 HuggingFace 的 WikiText-2 数据集 [21]。提取一个样本子集,输入标记的长度为 32,并生成 96 个标记。全精度模型推理。
-
基线
- 对延迟和吞吐量进行比较。
- 因为cloud-only会导致隐私问题,因此不作为基准。
- Edge-Solo:LLM 将本地部署在边缘设备上,且不进行模型划分。
- Cloud-Edge-Even:在这种情况下,LLM 被均匀地划分为两部分。一个分配给边缘设备,另一个分配给云服务器。
- Cloud-Edge-Opt:使用所前面所提出的动态规划算法进行LLM分区,分别部署在云和边缘设备。与Edgeshard的区别是只有两个设备作为算法输入。(即没有考虑协作和异构?。)
B 整体评估
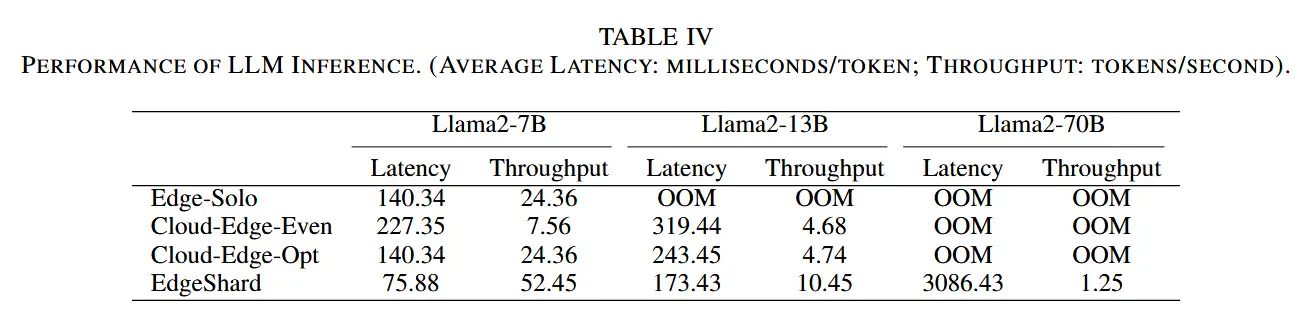
- LLM 推理的延迟和吞吐量如表所示。以下几点观察:
- 第一,EdgeShard 通过将大型模型拆分为分片并将其分配给多个设备来避免出现OOM,从而实现协作模型推理。
- 第二,与基线方法相比,EdgeShard 明显实现了更低的推理延迟和更高的推理吞吐量。
- 第三,还可以看到,对于 Llama2-7B,Cloud-EdgeOpt 在推理延迟和吞吐量方面往往具有与 Edge-Solo 相同的性能。这是因为在此实验设置中,源节点和云服务器之间的带宽非常有限,即 1Mbps。Cloud-Edge-Collaboration 的最优部署策略是本地执行,与 Edge-Solo 相同。
C 带宽的影响
-
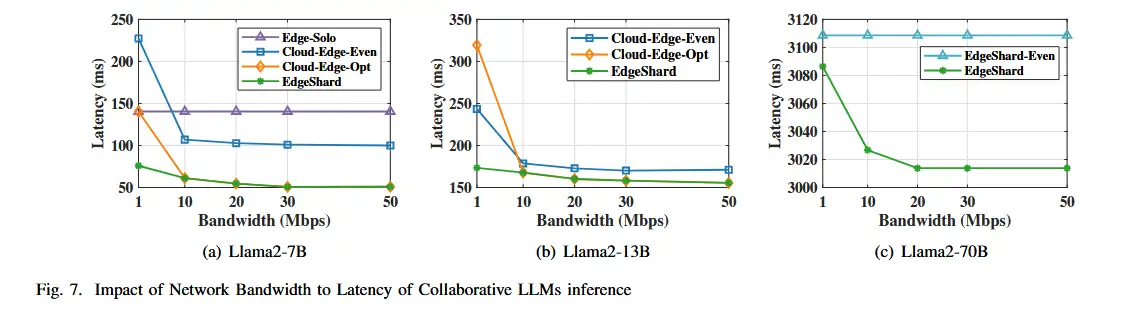
将源节点设置为 AGX Orin,并将云服务器和源节点之间的带宽从 1Mbps 更改为 50Mbps。LLM 推理的延迟和吞吐量的性能如图:
-
对于 Llama2-13B,单个 AGX Orin 无法容纳完整模型。只比较 Cloud-Edge-Even、Cloud-Edge-Opt 和 EdgeShard 之间的性能。
-
同样,由于内存限制,这三种基线方法无法部署 Llama2-70B 模型。将 EdgeShard 的性能与其变体(即 EdgeShard-Even)进行比较,其中模型被平等分区并部署到所有参与的计算设备。 它选择了 11 个 AGX Orin 和 1 个 RTX 3090 来部署 Llama2-70B 模型。
-
对于延迟 如上图
- 随着带宽增加延迟下降。
- 但当10Mbps到50Mbps时差异很小,带宽饱和,计算时间成为瓶颈。
- 有趣的是,当带宽大于 10Mbps 时,Cloud-Edge-Opt 和 EdgeShard 的延迟几乎相同。发现 EdgeShard 生成的模型分区和分配策略与 Cloud-Edge-Opt 方法相同。这表明 EdgeShard 的性能不会比 CloudEdge-Opt 差,Cloud-Edge-Opt 方式是 EdgeShard 的一个特例。在 Llama2-13B 中也观察到类似的模式。
- 对于 Llama2-70B,EdgeShard 的性能优于其变体 EdgeShard-Even,因为云服务器和边缘设备之间存在资源异构性,并且 EdgeShard 在计算设备之间自适应地对 LLM 进行分区。但是,性能提升并不那么明显,因为有 11 个 AGX 具有相同的计算能力,而只有 1 个 RTX 3090。
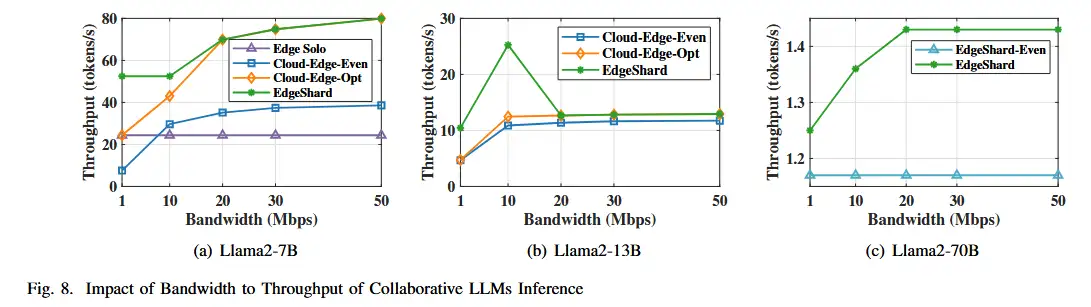
- 对于吞吐量 如上图
- 在 Llama2-7B 模型中也发现了与延迟评估类似的模式。但有以下几点不同
- 对于 Llama2-13B,当带宽为 10Mbps 时,EdgeShard 在 Cloud-Edge-Opt 方法中没有显示出相近性能,而是有很大的改进。这是因为 RTX 3090 和源节点(即 AGX Orin)的内存消耗很高。 对于 Cloud-Edge-Opt,两个设备的内存消耗分别上升到 95% 和 98%,这只允许最大批量大小为 4。
- 对于 Llama2-70B,EdgeShard 的吞吐量略有提升,EdgeShard-Even 显示出稳定的吞吐量,因为均匀分区策略不会随云源带宽的变化而变化。
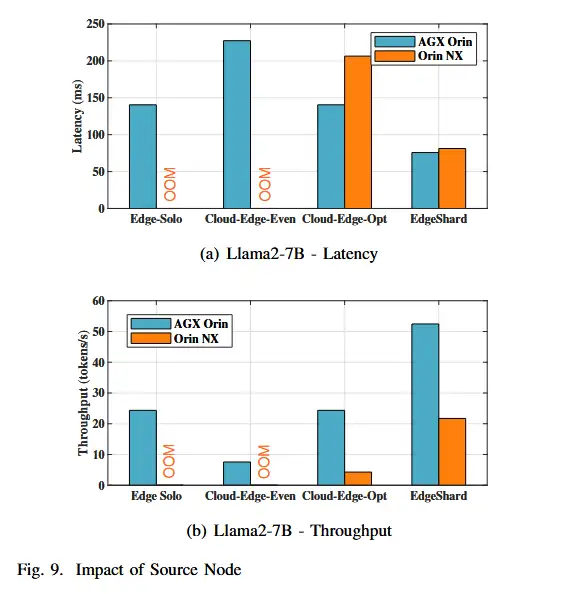
D 源节点的影响
- 还测试了源节点对推理延迟和吞吐量的影响,因为源节点可能具有不同的计算和内存容量,并且EdgeShard 强制执行部署在源节点上的第一层 LLM 模型,以避免原始数据传输。
- 将源节点分别设置为 AGX Orin 和 Orin NX,并比较它们的性能。结果如下图:
- Orin NX内存相对较低,使用EdgeSolo和Cloud-Edge-Even方法遇到OOM错误。
- Cloud-Edge-Opt 方法下两种情况的差异比 EdgeShard 要明显得多。这是因为 Cloud-Edge-Opt 情况下只有两个设备,并且它往往会在源节点上放置更多层。但是,AGX Orin 在计算能力方面比 Orin NX 强大得多。EdgeShard 往往涉及更多的设备,在源节点上放置的模型层更少,这可以填补源节点之间计算能力的空白。
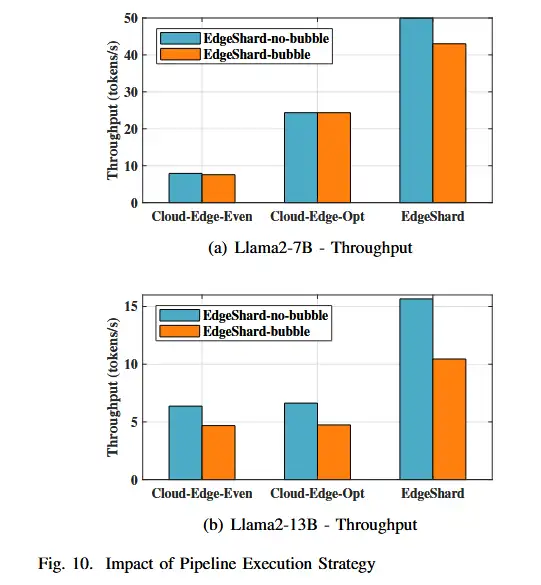
E 流水线执行策略的影响
- 评估了两种管道执行策略。结果如下图所示。
- 可以看到,对于所有方法,EdgeShard-No-bubble 的性能都优于 EdgeShard-Bubble。No-bubble的CloudEdge-Even 和 EdgeShard 分别比有bubble的每秒提高了约 0.36 和 6.96 个token。
- 对于 Cloud-EdgeOpt 方法,在本例中选择本地执行。没有管道执行,因此两种方法的吞吐量相同。
Ⅵ 总结
在这项工作中,作者提出了 EdgeShard,以实现 LLM 在协作边缘设备和云服务器上的高效部署和分布式推理 。作者制定了一个联合设备选择和模型分区问题,分别优化推理延迟和吞吐量,并使用动态规划算法来解决它。实验结果表明,EdgeShard 可以自适应地确定各种异构网络条件下的 LLM 分区和部署策略,以优化推理性能。Edgeshard 并非旨在取代基于云的 LLM 推理,而是通过利用无处不在的计算设备提供灵活且自适应的 LLM 服务方法。实验还表明,当云带宽不足时,EdgeShard 的性能优于云边协同推理方法,并且在面对相对丰富的云带宽时,往往会产生与 CloudEdge 协同推理方法相同的部署策略。

