- 论文 - 《Test-Time Adaptation for Combating Missing Modalities in Egocentric Videos》
- 代码 - Github
- 关键词 - ICLR2025、模态缺失、多模态(视频+音频)、TTA
摘要
- 问题背景
- 理解包含多种模态的视频任务中,结合多种感官输入可以显著提升动作识别和时刻定位等任务的效果,然而,现实应用中常常因隐私问题、效率需求或硬件限制而面临模态缺失的挑战。
- 当前的方法虽然有效,但通常需要完全重新训练模型以应对缺失的模态,成本高昂。
- 本文方法
- 本文的方法 MiDl(基于互信息的自蒸馏)通过最小化预测与可用模态之间的互信息,使模型在测试时对特定模态来源不敏感。
- 此外,作者引入了 自蒸馏机制,以在两种模态均可用时保持模型的原始性能。
- MiDl 是首个仅在测试时间处理缺失模态的自监督在线解决方案。
- 实验性能
- 通过在多种预训练模型和数据集上的实验,MiDl 展现了显著的性能提升,且无需重新训练。
1 引言
- 缺失模态的限制
- 在实际应用中数据模态可能是不完整的(Ma等,2022;Ramazanova等,2024)
- 例如,在使用可穿戴设备进行实时预测时,部分记录可能会被删除以保护隐私,或者成本限制可能迫使使用更便宜的模态(如音频或IMU)
- 因此,在这种假设下设计的模型在面对缺失模态时表现出显著的性能下降,有时甚至不如基于单模态训练的模型。
- 现有工作
- 一些研究探索了 架构上的改进,以有效融合来自不同模态的信息(Ma等,2022)
- 其他方法则专注于 设计有效的正则化器,以在面对缺失模态时提升模型性能(Colombo等,2021)
- 最近的工作提出了在训练过程中为Transformer模型引入可学习的标记(Lee等,2023;Ramazanova等,2024),这些标记用于在测试时补偿缺失信息,从而显著增强模型对缺失模态的鲁棒性。
- 局限性:所有现有的方法都需要对多模态模型进行昂贵的重新训练,使得预训练模型变得过时。
- 本文出发点:能否开发出无需重新训练即可在测试时应对缺失模态的方法?
- 本文工作
- 假设场景:在测试过程中,连续的未标记数据流被输入到预训练模型中,其中某些样本可能缺失特定模态。
- 目标:设计一种自适应算法,能够在实时环境中改进模型在缺失模态下的预测能力。
- 评估工作:作者首先评估了现有测试时间自适应文献中的方法,并证明它们在应对这一特定多模态挑战时效果有限。
- 提出方法:作者随后提出一种全新的测试时间自适应技术,专门用于解决缺失模态问题。
- 方法介绍 - 基于互信息与自蒸馏最小化的方法 (MiDI)
- 旨在激励预训练模型的输出在测试时 对模态来源保持不变性。
- 以 自监督 的方式最小化模型输出与测试时输入的未标记数据模态类型之间的 互信息。
- 为了确保在完整模态设置下的模型性能得以保留,作者将该方法 与自蒸馏机制相结合。
- 对 预训练模型架构、数据集以及测试时遇到的具体 缺失模态类型 均保持 无依赖性。
2 相关工作
2.1 模态缺失
- 研究现状
- 一些研究 基于训练数据是模态完整的假设,目标是训练一个在测试时对缺失输入具有鲁棒性的模型。
- Dai等(2024)研究了一种在训练过程中随机丢弃视频帧的策略,以提高多模态系统的鲁棒性。
- Lee等(2019)提出了一种方法,通过训练网络生成音频特征来应对缺失模态。
- Wang等(2023b)专注于一种多模态学习方法,该方法建模共享和特定特征,用于分类和分割任务。
- 其他研究则解决了 模态蒸馏任务,其中训练数据是多模态的,但在测试时仅使用一种模态。
- 少数研究假设模态 可能在训练和测试时均缺失,并尝试训练一个鲁棒的网络。
- 一些研究 基于训练数据是模态完整的假设,目标是训练一个在测试时对缺失输入具有鲁棒性的模型。
- 本文不同之处:探索了一个更现实的场景,即可能 无法访问训练数据或重新训练网络不可行。作者将此设定形式化为 TTA 问题,其中模型在测试时因某些模态的缺失而经历分布偏移。因此,本文提出了首个专门针对测试时缺失模态挑战的测试时间自适应算法。
2.2 TTA
略
3 TTA中的模态缺失
3.1 问题形式化
设 f_\theta : \mathbb{R}^d \to P(Y) 是一个分类器,它将给定的输入 x \in \mathbb{R}^d 通过输出概率 P(Y) 映射到标签集合 Y = \{1, 2, \dots, K\} 上。
然而,在许多实际应用中,提供给模型的输入可能包含缺失模态。用 m \in \{A, V, AV\} 表示给定输入 x 的可用模态类型,分别对应仅音频、仅视觉和音视频。为了简化表示,将缺失模态的部分用零填充,从而固定输入 x 的维度。此外,假设 f_\theta 是在一个训练集 D 上预训练的多模态模型。在本研究中,不对 f_\theta (即架构选择)、数据集 D 或训练过程做任何假设。
在测试时,f_\theta 接收一个可能包含缺失模态的未标记数据流 S 。数据流 S 中某种模态出现的可能性由概率质量函数 P_S(M = m) 描述。例如,如果 P_S(M = V) = 0.5 且 P_S(M = AV) = 0.5 ,那么测试流中的音频缺失率为 50%,即一半的数据仅包含视频而不包含音频。令 p_m = P_S(M = m) ,则不同模态的缺失率可以用 P = \{p_A, p_V, p_{AV}\} 来表征。例如,对于一个 25% 缺失视频的流, P = \{0.25, 0.0, 0.75\} 。
3.2 TTA过程
一个自适应方法是一个函数 g(\theta) ,它顺序地调整模型参数 \theta ,以增强在缺失模态设置下的性能。形式上,遵循在线学习文献,模拟了在时间步 t \in \{0, 1, \dots, \infty\} 下,由 P 表征的数据流 S 与 TTA 方法 g 的交互过程,具体如下:
- 数据流 S 暴露一个样本/批次 x_t 及其对应的模态 m 。
- 模型 f_{\theta_t} 生成预测结果 \hat{y}_t 。
- 自适应方法 g 调整模型参数 \theta_t 至 \theta_{t+1} 。
其中, f_{\theta_0} 是未经自适应的预训练模型。也就是说,对于每个暴露的样本/批次 x_t ,模型需要在其接收到下一个数据点 x_{t+1} 之前预测其标签。自适应方法 g 可以利用预测标签来改进模型在后续暴露样本上的性能。自适应方法 g 的性能通过在线比较预测标签 \hat{y}_t 和真实标签 y_t 来衡量。
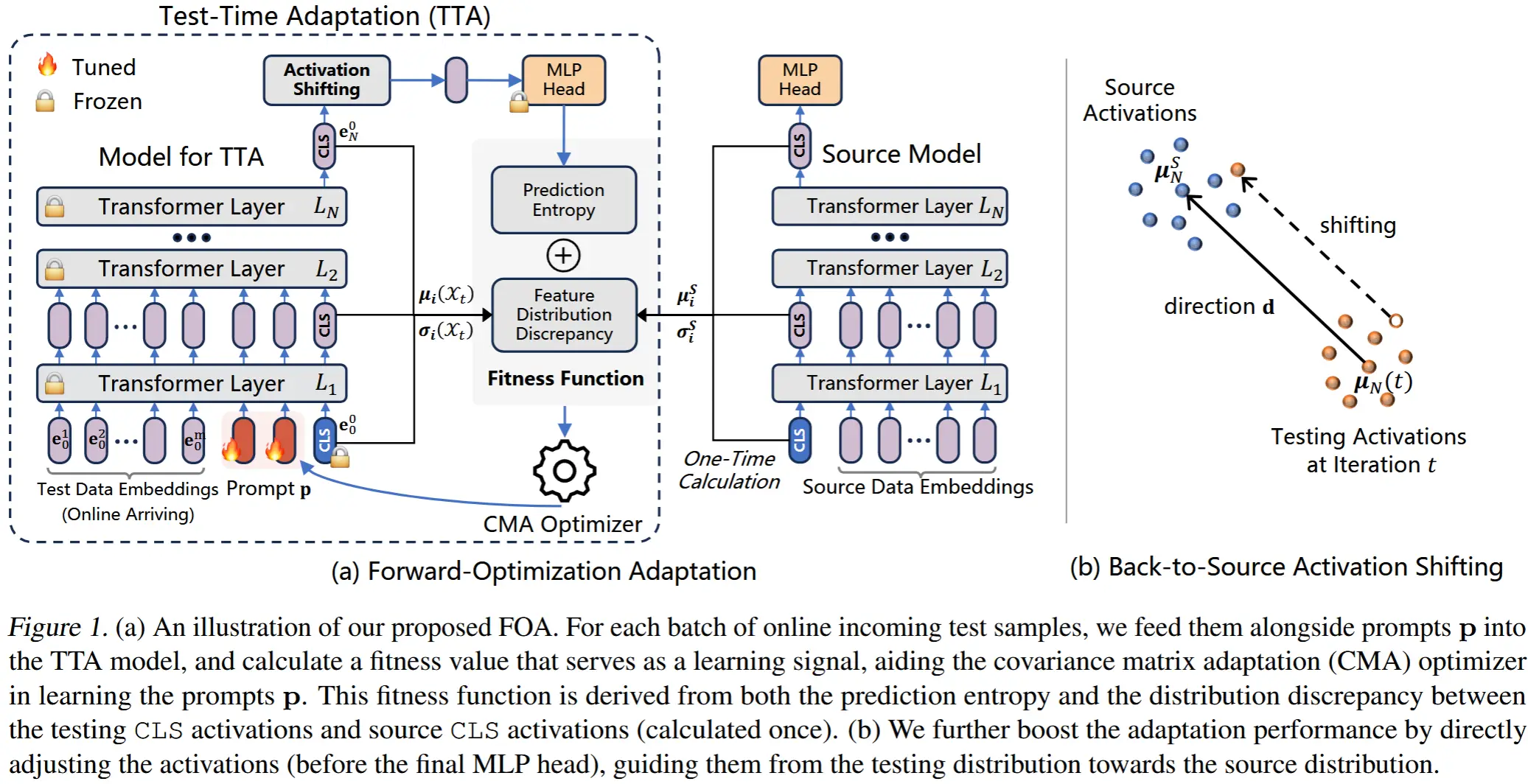
4 提出解决办法
4.1 确立目标函数
为了形式化本文的自适应方法,作者首先提出一个问题:在缺失模态的情况下,一个最优的 f_\theta 应该如何表现?
(目标属性) f_\theta 的预测应与模态来源 m 无关,换句话说, f_\theta 在完整和不完整模态下应输出相同的预测,因此满足以下两个等式/属性:
- f_\theta(x_i; M = A) = f_\theta(x_i; M = V) = f_\theta(x_i; M = AV), \forall i 。
- f_\theta 应在完整模态数据上保持高预测性能,这通常适用于 f_{\theta_0} 。
(目标函数) 为了构建一个满足这两个属性的自适应算法,作者定义了以下目标优化问题:
其中,\text{MI}(u, v) 是 u 和 v 之间的互信息,如果两个随机变量 u 和 v 的互信息 \text{MI}(u, v) = 0 ,则 u 和 v 相互独立。方程 (1) 中的第一项旨在满足属性 (1),即自适应分类器的输出在测试时将独立于可用的模态。方程 (1) 中的第二项旨在满足属性 (2),通过最小化自适应模型预测与原始模型 f_{\theta_0} 预测之间的 KL 散度,为互信息最小化配备了自蒸馏方法。
4.2 更新过程
尽管方程 (1) 中的目标函数是自监督的,但要获得 \theta^* ,需要访问数据流 \mathcal{S} 中的所有样本以评估期望值 \mathbb{E}_{x \sim \mathcal{S}} ,而在线评估协议在测试时无法提供这些样本。为此,需要在测试时时刻 t 接收到的样本 x_t 来近似期望值。
(更新函数) 因此,MiDI 自适应步骤在时间戳 t 可以表示为以下公式:
其中,
其中,\hat{f}_\theta(x_t) = \mathbb{E}_m[f_\theta(x_t; m)] , f_\theta^i(x_t; m) 是向量 f_\theta(x_t; m) 的第 i 个元素,且 \gamma > 0 是梯度下降步长的学习率。
为了估计期望值 \mathbb{E}_m[f_\theta(x_t; m)] ,需要对 x_t 执行 三次前向传递,分别设置 m \in \{A, V, AV\} 。将这些预测结果取平均,并计算它们的熵来计算 \mathcal{L}_{\text{ent}} (参见图 2)。
全文最核心的地方公式(2),总共包含三个损失函数
- \mathcal{L}_{\text{KL}},用于保证在完整模态下性能也不会下降,通过初始模型和当前模型的预测分布间的KL散度计算而来。
- \mathcal{L}_{\text{ent}},表示模型在特定模态 m 下的预测熵,它衡量了模型在单个模态下的不确定性。
- \mathcal{L}_{div},表示模型在所有模态下的平均预测熵。
\mathcal{L}_{ent} - \mathcal{L}_{div}差值的意义 :衡量了模型输出与模态来源 m 的依赖程度。如果 \mathcal{L}_{MI} = 0,则说明模型输出与模态来源无关,实现了对模态缺失的鲁棒性。
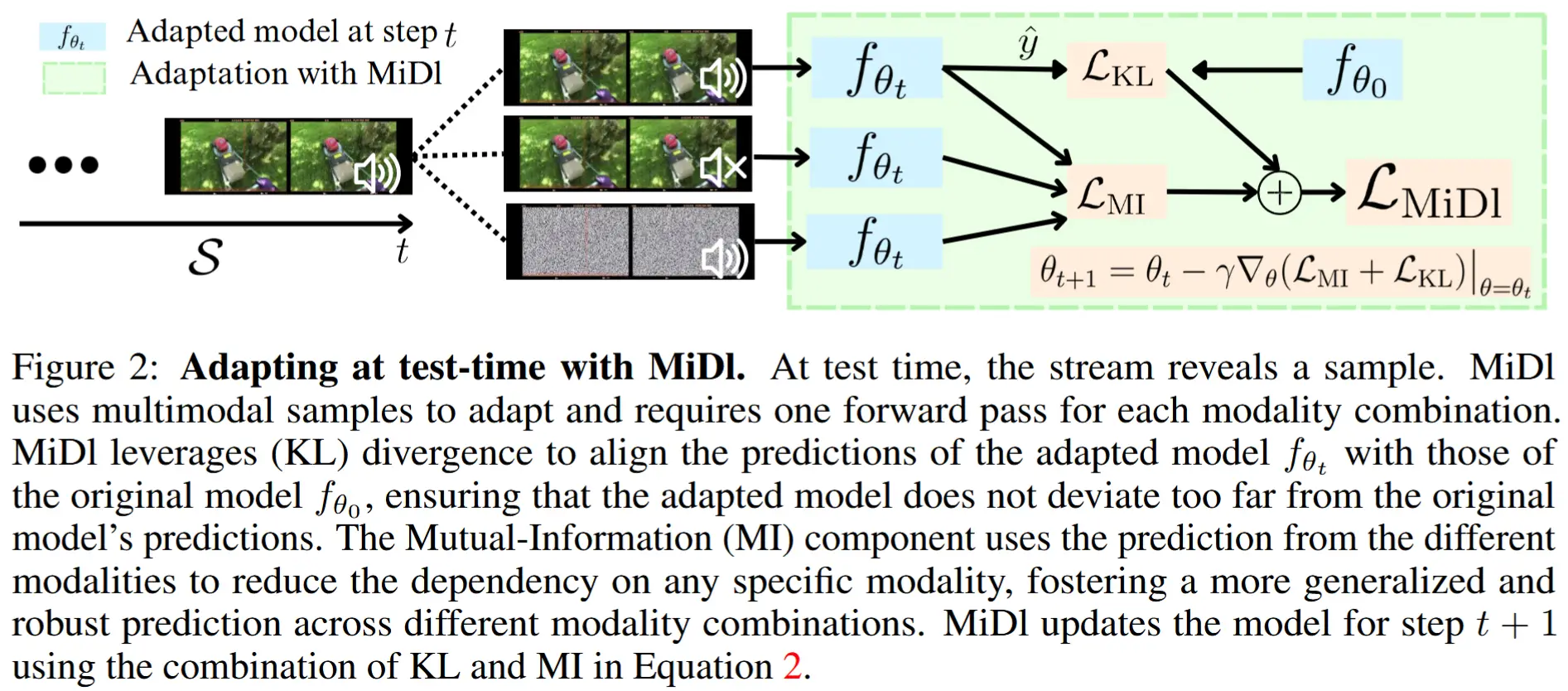
需要注意的是,在不完整模态下, \mathcal{L}_{\text{ent}} = \mathcal{L}_{\text{div}} ,导致 \mathcal{L}_{\text{MI}} = 0 。因此,只有当 x_t 具有完整模态时, \mathcal{L}_{\text{MI}} \neq 0 。基于此,作者建议 仅在数据流 \mathcal{S} 暴露具有完整模态的样本 x_t 时进行自适应步骤。数据流 \mathcal{S} 和 MiDI 在每个时间步 t 的交互形式如下:
- 数据流 \mathcal{S} 暴露一个样本/批次 x_t 及其对应的模态 m 。
- 模型 f_{\theta_t} 生成预测结果 \hat{y}_t 。
- 如果 x_t 具有完整模态,则通过公式 (2) 自适应模型参数 \theta_t 至 \theta_{t+1} ,否则设置 \theta_{t+1} = \theta_t 。
4.3 关键结论
- 本文首次将缺失模态问题形式化为测试时间自适应问题。
- 本文的研究对训练阶段的架构或训练目标没有任何假设,仅要求模型在测试时能够处理多模态数据。
- 本文提出了 MiDl,这是首个有效应对缺失模态挑战的测试时间自适应方法。
- MiDl 仅在遇到模态完整的样本时更新模型参数,但会对所有样本生成预测,无论其包含哪些模态。
- MiDl 能够以无监督在线的方式对任何预训练的多模态模型进行参数调整,从而适应接收到的未标记数据流。
5 实验
5.1 实验设定
- 数据集:Epic-Kitchens、Epic-Sounds、Ego4D-AR
- 评估方法
- 将预训练模型暴露于一个未标记的验证数据流 S_{\text{val}} ,其中以 1 - p_{AV} 的比率随机丢弃一种模态。设置 p_{AV} \in \{0.0, 0.25, 0.5, 0.75, 1.0\} ,对应的缺失率分别为 \{100\%, 75\%, 50\%, 25\%, 0\%\}。
- 根据 Ramazanova 等人(2024),对于每个数据集,丢弃其主要模态(例如,Epic-Sounds 的声音模态和 Epic-Kitchens 的视觉模态)
- 作者还报告了仅依赖可用模态的单模态模型的性能(例如,Epic-Sounds 的视觉模态和 Epic-Kitchens 的音频模态)。理想情况下,一个经过良好自适应的多模态模型应该达到或超过这些单模态模型的性能。
- 模型:Multimodal Bottleneck Transformer (MBT)
5.2 性能提升
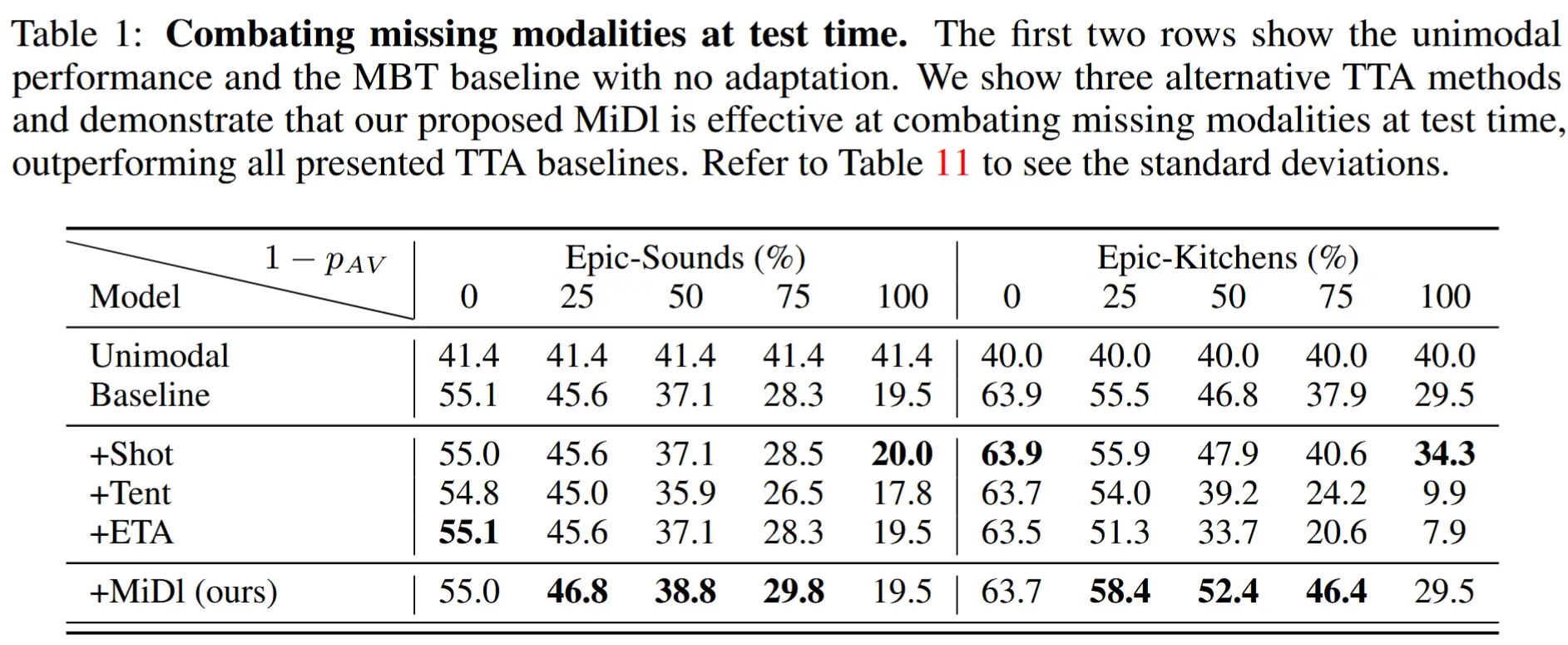
- 表1
- 显著增强基线性能 :在缺失模态的情况下,MiDl 显著提升了模型的性能。
- 当所有模态均存在时(缺失率为 0%),MiDl 能够保留基线模型的性能。
- 现有的 TTA 方法(如信息最大化方法 Shot 和基于熵最小化的 ETA)对缺失模态问题的效果较差。原因在于这些方法主要针对协变量域偏移(covariate domain shift)设计,而非专门应对缺失模态这一特定类型的域偏移。
5.3 长期自适应(LTA)场景
- 表2
- 实验设计:使用训练集的一个子集 S_{in} 进行自适应,随后在验证集 S_{val} 上评估性能。S_{in} 提供完整模态的未标记数据,用于仅执行自适应。
- 实验结果:数据流越长,MiDl 的性能提升越大;其他方法无法从中受益。
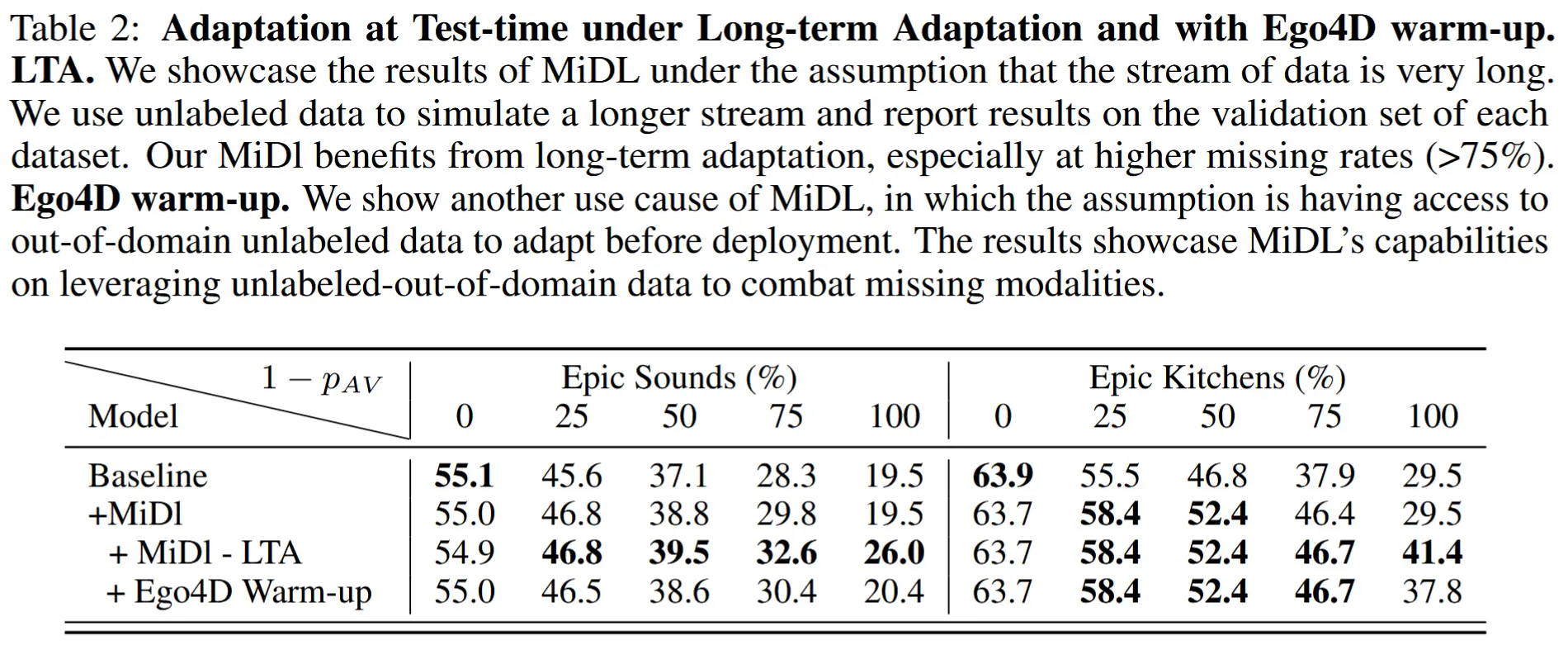
5.4 预热设置
- 上方表2
- 实验设计:在模型部署前,利用来自域外的未标记数据 S_{out} 进行预热,以增强模型对缺失模态的鲁棒性。
- 实验结果:预热对性能有积极影响。
作者还做了其他实验,证明了MiDI与架构选择、缺失模式的类型、预训练无关以及消融实验。感兴趣可以看看原论文。
5 总结
在这项工作中,作者提出了 MiDl,这是一种改进预训练视频识别模型在测试时处理缺失模态的新方法。MiDl 通过最小化互信息和使用自蒸馏,提高了模型给出准确预测的能力,无论模态的可用性如何。实验表明, MiDl 可以显著提高各种数据集和场景以及各种缺失率的准确性,使其成为处理不完全模态的实际应用的实用解决方案。