- 论文 - 《MoniTor: Exploiting Large Language Models with Instruction for Online Video Anomaly Detection》
- 代码 - Github
- 关键词 - 在线视频异常检测VAD、视觉-语言模型VLM
这篇文章聚焦于在线视频异常检测任务,不同于之前的REWARD使用的是传统模型,而本文使用的是LLM、BLIP、ImageBind等。流程上类似LAVAD,主要都是靠VLM生成描述后清洗,再对时序建模输入给LLM进行打分。由于在线场景的特殊性,本文参考了LSTM的特性,对长短期记忆进行建模。但是感觉这里的实时定义和实时性能还是存在疑问的,6.4秒完成一帧的异常得分。
1 引言
- 研究现状
- 现有的 VAD 方法大多采用离线方式,忽视了实时监控与真实世界应用的需求,而这些需求在诸多实际场景中同样扮演着关键角色,例如智能监控、自动驾驶等。
- 流式/在线 VAD 挑战
- 异常事件具有不连续性且发生频率极低,导致缺乏广泛且多样化的异常数据用于训练。
- 人类行为的高度复杂性(即包含大量正常与异常动作)也严重阻碍了 VAD 模型在真实环境中的泛化能力。
- 例如,Karim 等人 [21] 提出了 REWARD,一个用于实时异常检测的弱监督框架。由于训练数据有限,REWARD 在动态摄像机角度和复杂场景下表现不佳,限制了其在多样化环境中的适用性。
- 本文工作 - MoniTor
- 特点:一种新颖的、基于记忆的在线评分队列机制,用于无需训练的视频异常检测。
- 首先,我们通过动态记忆门控模块(Dynamic Memory Gating Module)引入了一种层次化双记忆架构,系统性地应对在线异常固有的时序不连续性。该架构融合了具备自适应遗忘机制的长期情景记忆模块与编码细粒度时空模式的短期工作记忆模块。通过这种双记忆设计,我们有效解决了真实场景中异常事件不连续、低频发生所带来的挑战。
- 其次,我们提出了一种基于标准评分队列(Standard Scoring Queue)的原则性异常评分协议,其中包含一种新颖的队列机制,用于顺序传播异常描述符。该协议利用从百科类知识源衍生出的知识增强型异常先验(knowledge-enhanced anomaly prior),显著提升了模型对各类异常事件的泛化能力,有效缓解了人类行为复杂性与现有数据集局限性带来的障碍。
- 第三,我们在行为预测与动态分析(Behavior Prediction and Dynamic Analysis)组件中设计了一个预测评分框架,充分利用流式视频中的时序因果关系。该框架在“预期”与“现实”之间建立反馈回路,即使面对随机且稀疏出现的突发异常,也能显著提升检测灵敏度,从而有效缓解异常训练数据稀缺的问题。
- 作者在两个大规模数据集(UCF-Crime 和 XD-Violence)上对 MoniTor 进行了 评估。实验结果表明,MoniTor 不仅优于当前最先进的方法,而且在无需任何训练的情况下,其性能可与弱监督方法相媲美。
2 相关工作
- Online VAD
- 工作
- 早期在线 VAD 研究中,Chaker 等人 [6] 采用基于滑动窗口的方法构建时空立方体(spatio-temporal cuboid),实现在线异常检测与定位。
- Luo 等人 [28] 与 Wang 等人 [46] 则利用 LSTM 自编码器对运动与外观信息进行编码。
- 近期,受 Zhou 等人 [54] 提出的无需访问全部视频帧的密集视频描述流式模型启发,Rossi 等人 [35] 提出了 MOVAD 框架,包含短期记忆模块(STMM)与长期记忆模块(LTMM),用于处理历史与当前帧以支持在线 VAD 任务。
- 局限:部分方法无法有效捕获历史上下文信息,另一些则可能因误导性历史数据而导致异常评分偏移。
- 工作
- LLM-based VAD
-
工作:略
-
局限:
- 缺乏对视频序列中时序上下文的鲁棒推理能力;
- 对提示工程表现出高度敏感性;
-
针对局限,本文解决方法:
- 基于 LSTM 的遗忘门控机制:有选择地保留关键时序上下文,同时过滤无关信息;
- 新颖的评分队列架构:为 LLM 提供结构化引导,显著提升其在动态环境中的决策精度。
-
3 方法
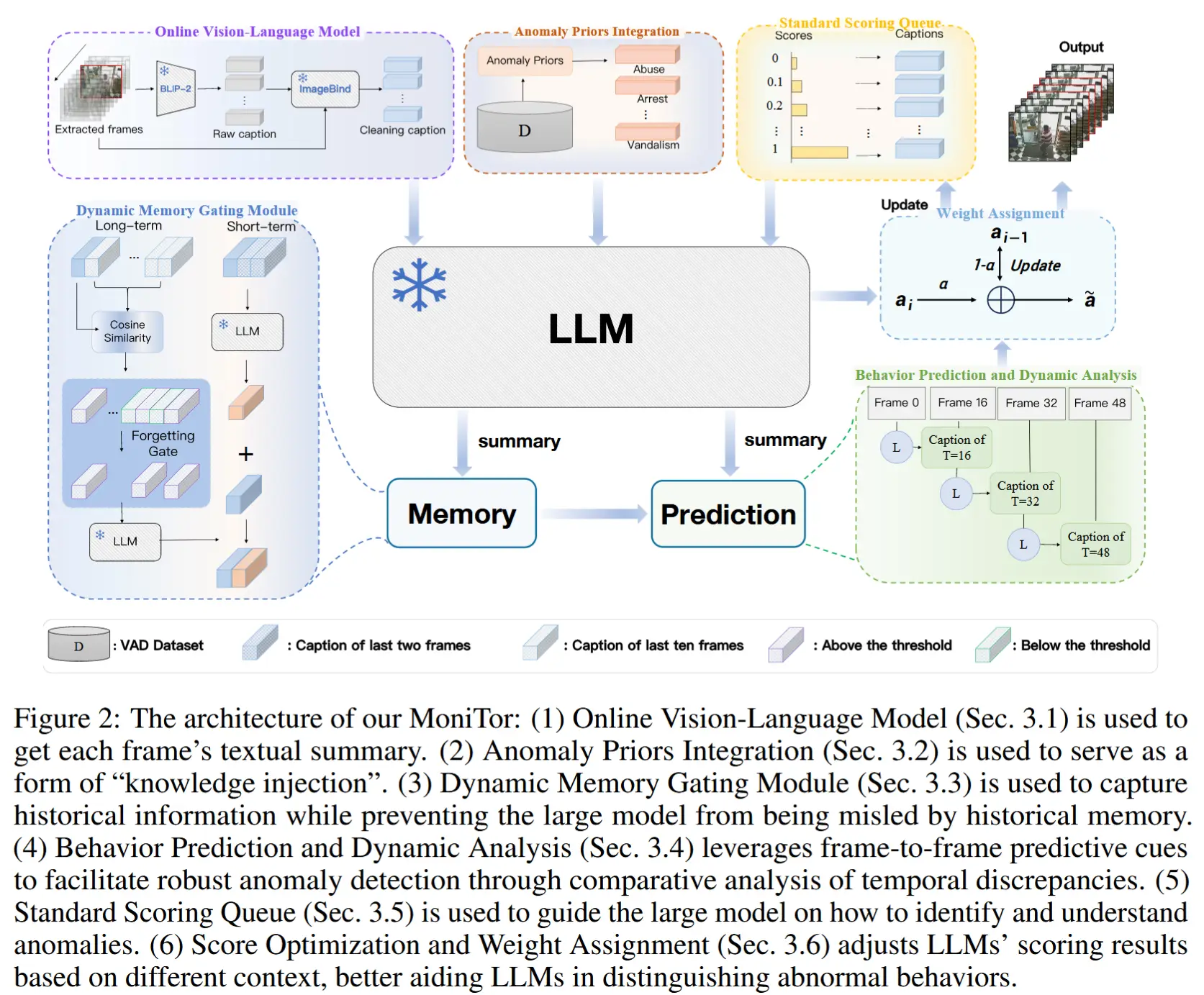
整体框架如图 2 所示。
当从一段未修剪的视频中提取出一帧后,该帧会被送入在线VLM,以生成对应的文本摘要。随后,异常先验集成(Anomaly Priors Integration)模块被用来引导 LLM 更准确地理解“异常事件”的概念。
为了充分融合历史信息,动态记忆门控模块(Dynamic Memory Gating Module)分别对长期和短期历史帧的文本描述进行摘要,并将这些摘要传递给 LLM。同时,行为预测与动态分析模块(Behavior Prediction and Dynamic Analysis Module)被用于引导 LLM 预测下一帧的文本描述;该预测结果将在处理下一帧时作为上下文输入提供给 LLM。
此外,标准评分队列(Standard Scoring Queue)用于存储每个异常分数所对应的历史帧信息,而 LLM 预测出的异常分数则用于更新该评分队列。
3.1 在线VLM
目标:Online VLM 将视频帧实时转换为其对应的文本描述。
实现:
-
首先使用五个 BLIP-2 模型为当前帧 I_i 生成五个原始描述 R_i = \{R_{i1}, R_{i2}, R_{i3}, R_{i4}, R_{i5}\}。
-
然而,这些原始描述可能包含噪声。为缓解此问题,我们充分利用历史信息:对于每个原始描述 A_j(属于集合 A = R_i \cup R_{i-1} \cup R_{i-2} \cup R_{i-3} \cup R_{i-4} \cup R_{i-5}),计算其文本特征与该帧图像特征之间的余弦相似度 X_j,即:
X_j = \langle E_I(I_i) \cdot E_T(A_j) \rangle其中,\langle \cdot, \cdot \rangle 表示余弦相似度,E_I 是 ImageBind 的图像编码器,E_T 是 ImageBind 的文本编码器。
-
随后,根据余弦相似度 X_j 对所有原始描述 A_j 进行排序,并选取前 10 个作为“清洗后”的描述 C_i = \{A_1, A_2, \dots, A_{10}\}。
-
最后,将清洗后的描述 C_i 输入 GLM-4-Flash 模型以获取摘要:
S_i = \Phi_{GLM}(P_S \circ C_i)
3.2 异常先验集成
目标:将异常先验 P_A 融入上下文提示中,以引导 LLMs 识别并关注这些异常事件。
实现:通过将来自维基百科的这些异常类别的定义添加到上下文提示中,并辅以适当示例,来引导 LLMs。
3.3 动态记忆门控模块
目的:本模块基于 LSTM 架构,用于同时捕获长期记忆(M_l)和短期记忆(M_s)。其中引入了一个遗忘门,以确保模型能准确表征输入并滤除噪声。
-
长期记忆(M_l)维护一个由过去 10 帧文本描述组成的摘要,记为 S_i = \{S_{i-10}, S_{i-9}, \dots, S_{i-1}\}。这些帧会通过遗忘门 F 进行筛选,该门计算当前帧与历史帧之间的相似度;若相似度高于阈值 \theta,则保留该帧用于摘要生成。
长期记忆的更新公式如下:M_l = \Phi_{GLM}(D_l) \tag{1}D_l = \begin{cases} D_1 + S_{i-j}, & \text{if } d_{i-j} > \theta \\ D_1, & \text{if } d_{i-j} \leq \theta \end{cases} \quad j = 1,2,\dots,10 \tag{2}d_{i-j} = \langle \mathcal{E}_T(S_i), \mathcal{E}_T(S_{i-j}) \rangle \tag{3}其中:
- \langle \cdot, \cdot \rangle 表示余弦相似度;
- 文本编码器 \mathcal{E}_T: \mathcal{T} \rightarrow \mathcal{Z} 将文本映射到向量空间;_
- d_{i-j} 是当前帧 S_i 与第 j 个历史帧 S_{i-j} 的文本描述之间的余弦相似度;
- D_l 是经过遗忘门过滤后的长期记忆存储内容;
- j 作为索引,用于从当前帧回溯至前 10 帧。
-
短期记忆(M_s)仅对最近的两帧 S_{i-1} 和 S_{i-2} 进行摘要,从而提供对近期上下文更直接的表示。短期记忆通过以下方式更新:
M_s = \Phi_{GLM}(D_s)其中 D_s 包含来自前两个帧的文本描述。
3.4 行为预测与动态分析
目的:着重提升模型对行为的预测能力,并利用长期与短期记忆中的摘要信息进行动态分析。
预测结果 P_2 由下式获得:
其中:
- S_i 表示当前帧的摘要;
- P_2 是基于当前帧对下一帧行为的预测;
- 预测步骤发生在前一步骤的评分阶段内。
组件 P_p 的设计提示为:“如果你是执法机构,请结合可能的可疑活动或行为(如虐待、逮捕、纵火、袭击、入室盗窃、扰乱秩序、爆炸、打斗、抢劫、枪击、盗窃、破坏公物等),预测此场景接下来可能发生什么。请根据当前上下文给出简洁的预测。”
组件 P_{pf} 的结构化提示为:“请精确预测接下来最有可能发生的事件或行为,避免任何额外解释。”
该方法使得模型能够在动态视频序列中对潜在行为进行精准、有针对性的评估,从而优化其评分与分析能力。
3.5 标准评分队列
在本模块中,我们为 LLMs 实现了一种动态评分系统,该系统基于预定义的评估标准,帮助模型生成高质量的输出。为实现这一目标,我们维护一个评分队列 Q = \{Q_0, Q_{0.1}, \dots, Q_1\} ,其中每个元素 Q_i 代表最近一次获得评分为 i 的文本描述。
该评分队列作为这些异常评估结果的存储库,支持实时更新与比较。其更新方式如下:
其中, a_{i-1} 表示第 i-1 帧的异常分数, S_{i-1} 表示第 i-1 帧的文本描述。该公式表明:第 i-1 帧的摘要 S_{i-1} 将根据其异常分数 a_{i-1} 存储在队列中对应的 Q_{a_{i-1}} 位置,用于记录并追踪该时刻的异常检测结果,并为 LLMs 提供评分指导。
3.6 评分优化与权重分配
在我们的方法中,我们实现了一种动态权重分配策略,以自适应地平衡当前帧评分与前一帧评分的重要性。该机制使模型能够在保留先前帧所提供上下文连续性的前提下,对视频序列中的变化做出响应。通过这种方式,模型可以逐步调整新信息,而不会突然丢弃早期帧提供的历史上下文。
权重分配过程结构如下:对于批次中的每一帧,其评分由当前帧评分与前一帧评分组合计算得出,确保两者均贡献加权影响。这种平衡由参数 \alpha 控制,该参数决定了当前帧与前一帧评分的影响比例。加权评分定义为:
其中, \tilde{a}_i 表示第 i 帧经过调整后的评分, a_i 是当前帧的原始评分, a_{i-1} 是前一帧的评分。参数 \alpha (取值范围 0 \leq \alpha \leq 1 )控制了两个评分之间的权重分配,允许模型在考虑过去上下文的同时,灵活适应视频序列中的动态变化。
该方法增强了模型在视频帧间进行平滑、上下文感知的行为预测能力。最终,整体评分由以下公式总结:
其中, a_i 表示当前帧在权重分配前的异常分数,它来源于行为预测、长期与短期记忆、评分队列、异常先验及帧摘要的综合结果。这种结构化方法使模型能够有效区分正常与异常行为,充分利用时序和上下文线索,从而提升视频序列中的异常检测精度。
4 实验
4.1 实验设置
- 数据集:UCF-Crime、XD-Violence
- 评估指标:ROC-AUC、AP
4.2 实验结果
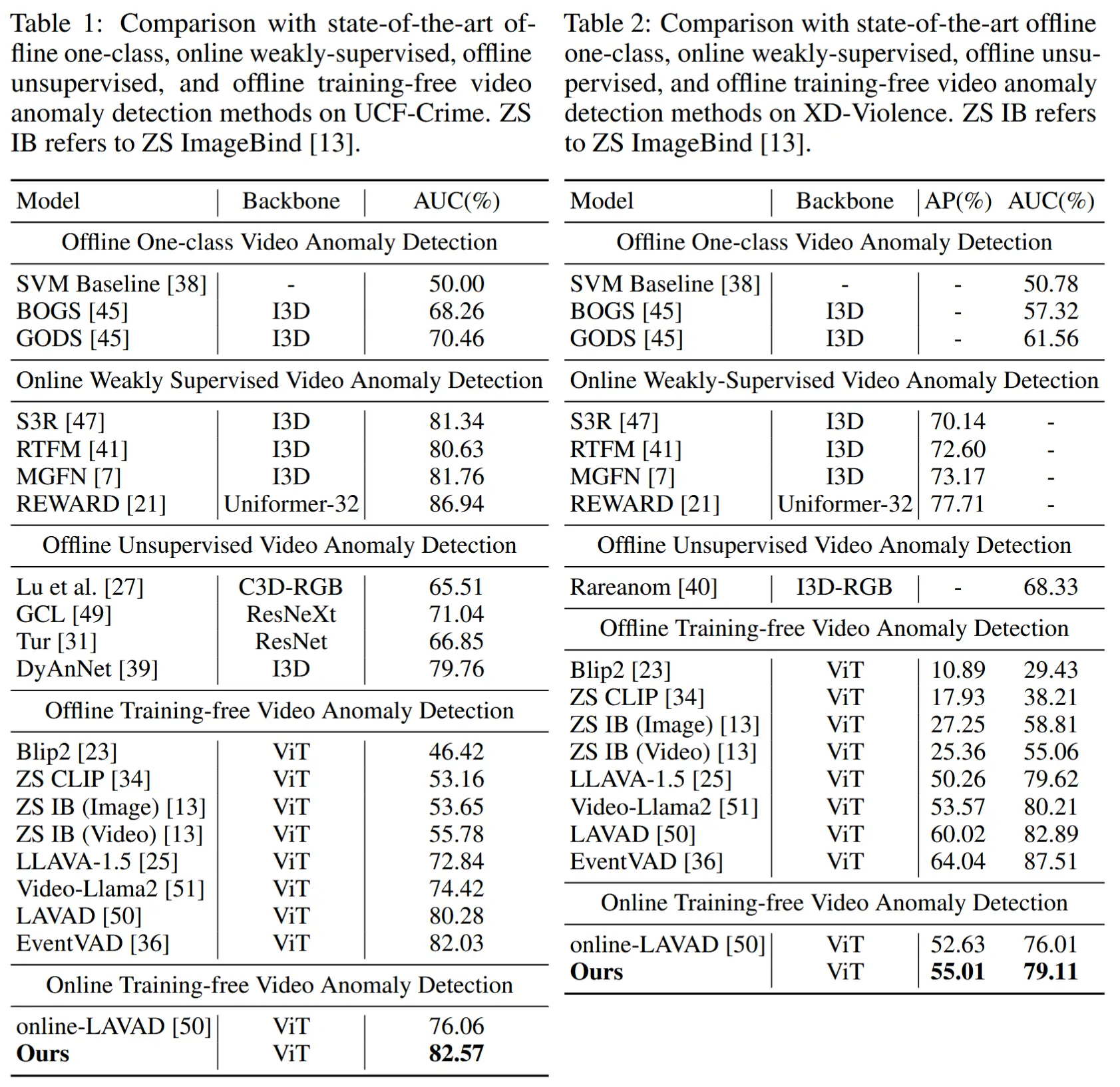
- 与SOTA性能比较
- UCF-Crime结果在表1,XD-Violence结果在表2
- 在 XD-Violence 数据集上提升较小,原因:MoniTor 的设计更适用于监控场景,而 XD-Violence 数据集中包含大量镜头切换(transitions),削弱了动态记忆门控模块与行为预测与动态分析模块的有效性。
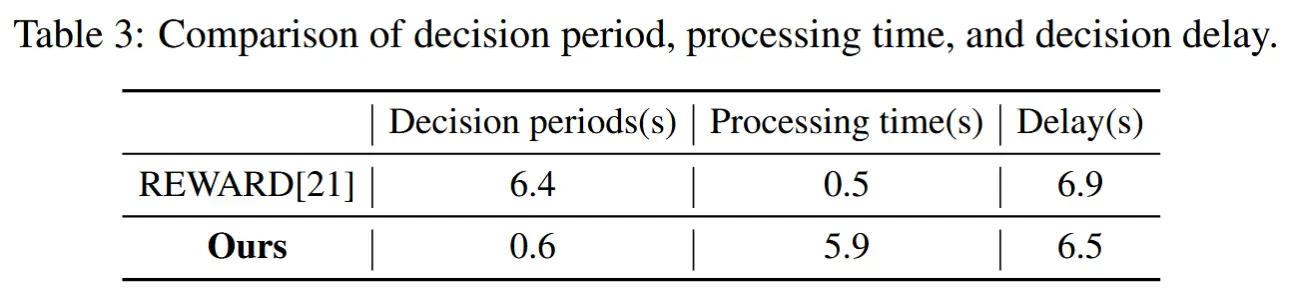
- 计算效率
- 如表 3 所示,与现有方法相比,MoniTor 通过有效捕获和选择历史信息,在实时性能上表现更优。
- MoniTor 每帧生成异常分数仅需 5~6 秒,决策周期为 0.6 秒——远快于一般在线 VAD 方法所要求的 30 秒标准。
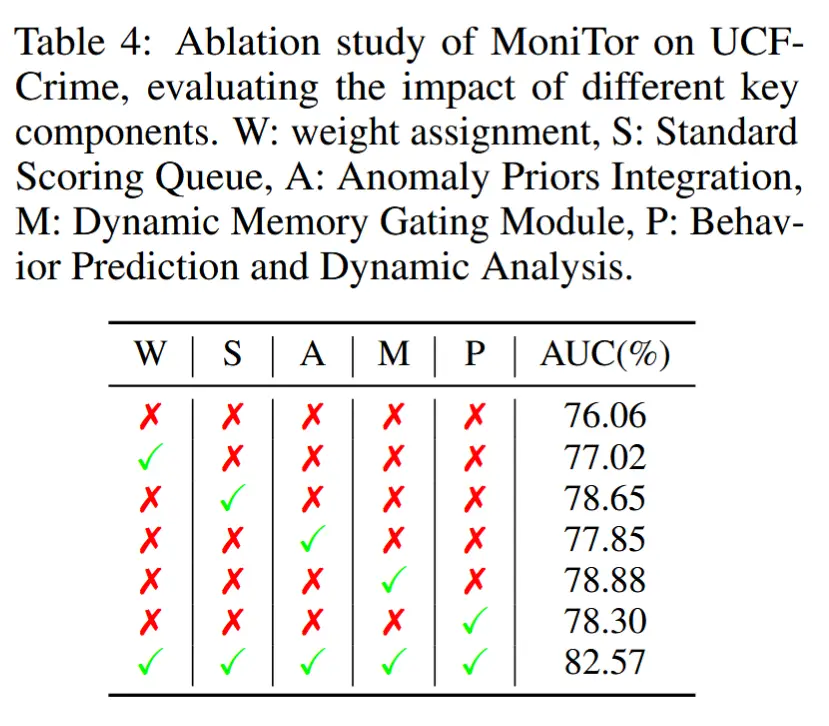
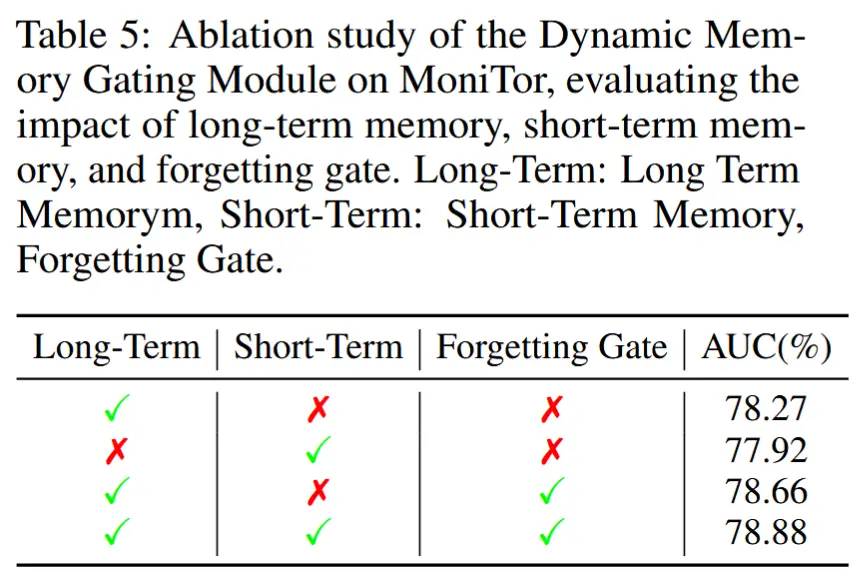
- 消融实验
- 如表 4 所示,在 UCF-Crime 数据集上依次集成各模块(W权重分配、S标准评分队列、A异常先验、M动态记忆门控、P行为预测与动态分析)
- 如表 5 所示,遗忘门与记忆机制的影响。